[논문리뷰] R^3-SQL: Ranking Reward and Resampling for Text-to-SQL
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hojae Han, Yeonseok Jeong, Seung-won Hwang, Zhewei Yao, Yuxiong He
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Functional Inconsistency: 동일한 실행 결과(Execution Result)를 산출함에도 불구하고 SQL 쿼리의 표면적 형태 차이로 인해 서로 다른 순위 점수를 할당받는 현상.
- Bounded Recall: LLM이 생성한 초기 후보군 내에 올바른 SQL이 존재하지 않아, 어떠한 순위 결정 전략으로도 정답을 찾아낼 수 없는 한계.
- Agentic Resampling: LLM 에이전트가 후보군을 검사하여 정답이 없다고 판단될 경우, 추가적인 후보 생성을 수행하는 능동적 샘플링 전략.
- GRPO (Group Relative Policy Optimization): 본 논문에서 리스트와이즈 랭커를 학습시키기 위해 도입한 강화학습 프레임워크로, 순서 불변성(Position-invariance) 등을 보장함.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 Text-to-SQL 시스템의 순위 결정(Ranking) 과정에서 발생하는 Functional Inconsistency와 Bounded Recall이라는 두 가지 핵심 과제를 해결하는 데 목적을 둡니다. 기존 방식들은 실행 결과가 동일한 SQL 쿼리들에 대해 서로 다른 점수를 부여하거나, 그룹화하더라도 그룹 크기에만 의존하여 정답을 포함한 소규모 그룹이 무시되는 등의 한계를 보입니다. 또한, 초기 생성 과정에서 정답 SQL이 누락될 경우 이를 복구할 메커니즘이 부재하여 성능의 상한선이 고정되는 문제가 있습니다. [Figure 1]은 이러한 기존 랭킹 전략들의 한계를 가시적으로 보여주며, 왜 통합된 그룹 기반 랭킹과 에이전트 기반 재샘플링이 필요한지를 입증합니다.
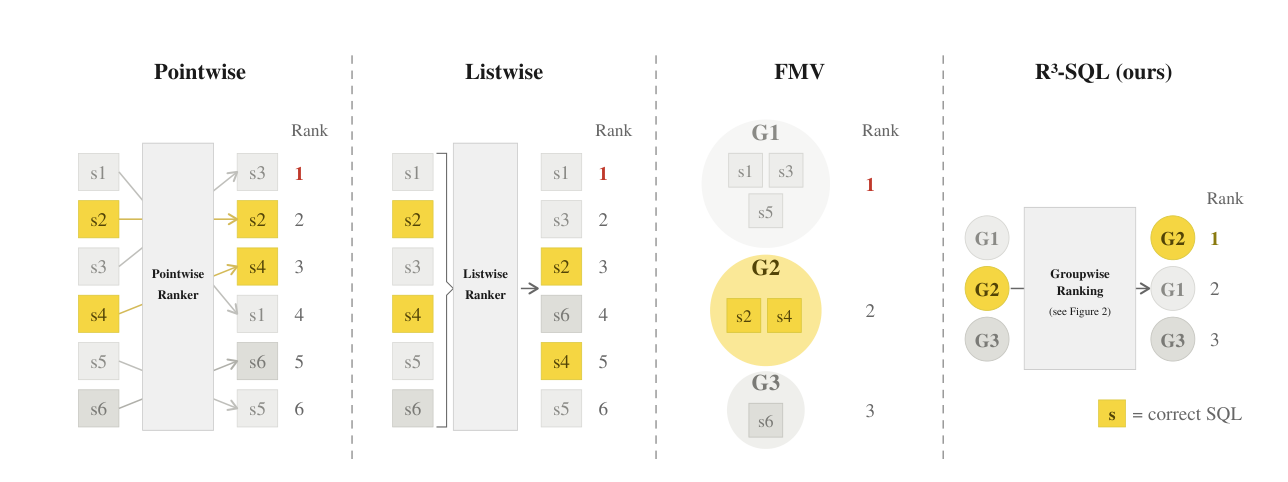
Figure 1 — 기존 랭킹 전략의 한계와 R^3-SQL의 개선 방향을 보여주는 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문이 제안하는 R^3-SQL은 그룹 기반 순위 결정과 에이전트 재샘플링을 결합한 통합 프레임워크입니다. 실행 결과(Execution Result)를 기준으로 후보군을 그룹화하여 의미론적 일관성을 확보하고, Pairwise Preference와 Pointwise Utility 신호를 통합하여 그룹 순위를 결정함으로써 Functional Inconsistency를 해결합니다. 또한, LLM 에이전트가 후보군의 정답 포함 가능성을 평가하여 부족한 경우에만 재샘플링을 수행하는 Agentic Resampling을 통해 Bounded Recall 문제를 완화합니다. 실험 결과, R^3-SQL은 BIRD-dev 벤치마크에서 75.03%의 Execution Accuracy (EX)를 기록하며, 공개된 모델 사이즈를 사용하는 시스템 중 가장 우수한 성능을 입증했습니다. [Table 2]는 제안 방법론이 다양한 벤치마크에서 기존 Baseline 대비 평균적으로 더 높은 성능을 기록했음을 명확히 보여줍니다.
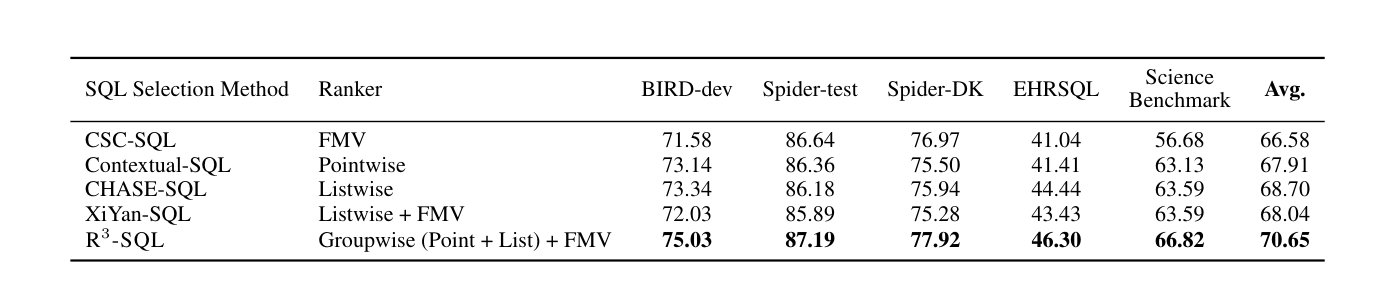
Table 2 — 제안 방법론의 정량적 성능 우위를 입증하는 핵심 비교 테이블
## 4. Conclusion & Impact (결론 및 시사점) R^3-SQL은 순위 결정과 재샘플링의 통합 모델링을 통해 Text-to-SQL 시스템의 정밀도와 재현율을 동시에 개선하는 성과를 거두었습니다. 본 연구는 단순히 랭킹 모델을 정교화하는 것을 넘어, 실행 결과를 활용한 그룹화와 에이전트 기반의 능동적 개입이 실용적인 성능 향상에 필수적임을 학계에 제시합니다. 향후 R^3-SQL의 접근 방식은 도메인 적응성을 갖춘 랭킹 모델 연구와 더욱 복잡한 에이전트 기반 데이터베이스 인터페이스 설계에 중요한 시사점을 제공할 것으로 기대됩니다.
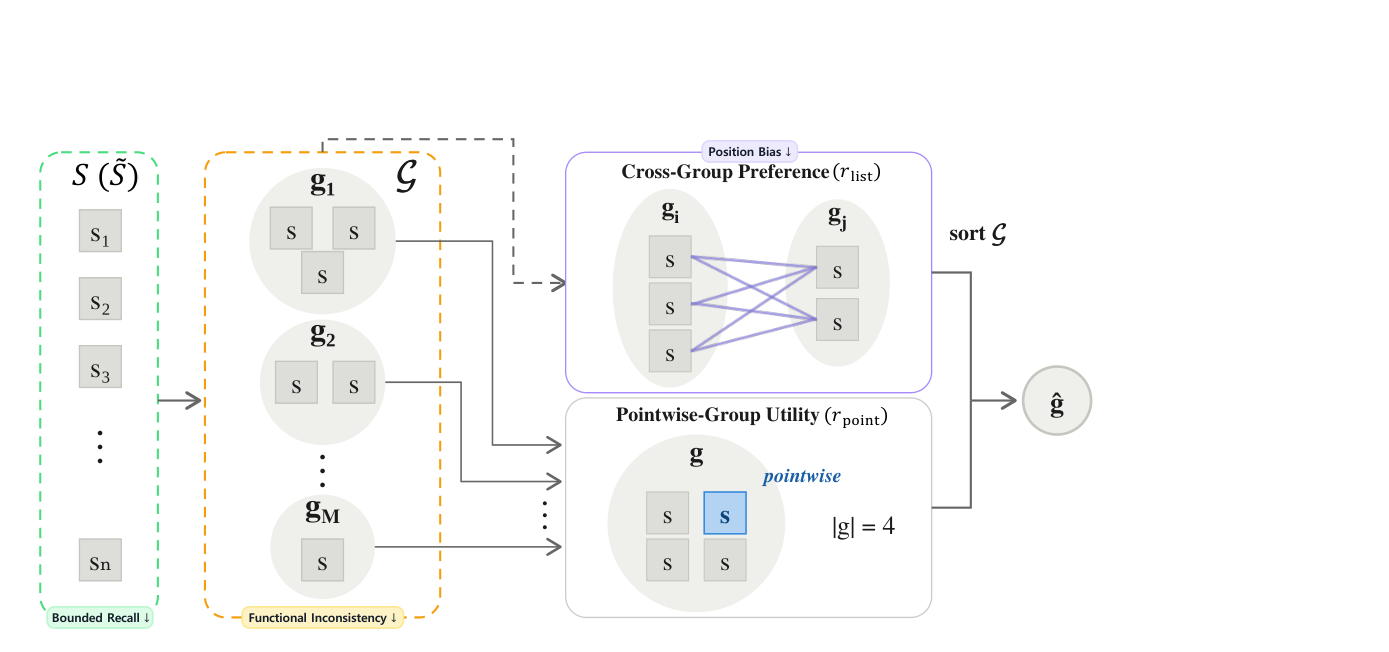
Figure 2 — 그룹화 및 랭킹 프로세스를 나타내는 통합 아키텍처 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Personalization as Inverse Planning: Learning Latent Design Intents for Agentic Slide Generation via Structural Denoising
- [논문리뷰] BioInsight: Multi-Agent Orchestration for Interactive Biomedical Knowledge Discovery
- [논문리뷰] Autodata: An agentic data scientist to create high quality synthetic data
- [논문리뷰] SciOrch: Learning to Orchestrate Expert LLMs for Solving Frontier Multimodal Scientific Reasoning Tasks
- [논문리뷰] OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
Review 의 다른글
- 이전글 [논문리뷰] Normalizing Trajectory Models
- 현재글 : [논문리뷰] R^3-SQL: Ranking Reward and Resampling for Text-to-SQL
- 다음글 [논문리뷰] Rethinking RL for LLM Reasoning: It's Sparse Policy Selection, Not Capability Learning
댓글