[논문리뷰] Chat2Workflow: A Benchmark for Generating Executable Visual Workflows with Natural Language
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yi Zhong, Buqiang Xu, Yijun Wang, Zifei Shan, Shuofei Qiao, Guozhou Zheng, Ningyu Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Workflow: 다수의 기능적 노드(Node)를 연결하여 복잡한 작업을 구조화하고 실행 가능한 형태로 구현한 시스템.
- Pass Rate: 생성된 workflow의 JSON 표현이 Chain-of-Thought(CoT) 시퀀스 및 사전 정의된 변수와 일치하며, 플랫폼에서 실행 가능한 YAML 파일로 성공적으로 변환되는지를 측정한 지표.
- Resolve Rate: 생성된 workflow가 실제 플랫폼 내에서 성공적으로 실행되어, 특정 instruction이 요구하는 최종 결과물을 올바르게 산출하는지를 측정한 지표.
- Workflow Orchestration Platforms: Dify 및 Coze와 같이 노드 기반의 workflow를 구축하고 실행할 수 있는 실무용 플랫폼.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실무 환경에서 널리 사용되는 agentic workflow의 구축이 현재 전적으로 수동적인 엔지니어링에 의존하고 있어, 자동화 및 확장성에 한계가 있다는 문제를 해결하고자 한다. 기존의 ReAct 기반 agent와 달리, 기업 현장에서는 신뢰성과 제어 가능성을 위해 명시적인 workflow를 선호하지만, 이를 자연어에서 직접 생성하는 것은 복잡한 제어 흐름 추론과 변경되는 요구사항 반영 측면에서 매우 어렵다. 이러한 문제를 체계적으로 연구하기 위해 저자들은 최초의 실행 가능한 visual workflow 생성 벤치마크인 Chat2Workflow를 도입하였다 [Figure 1].
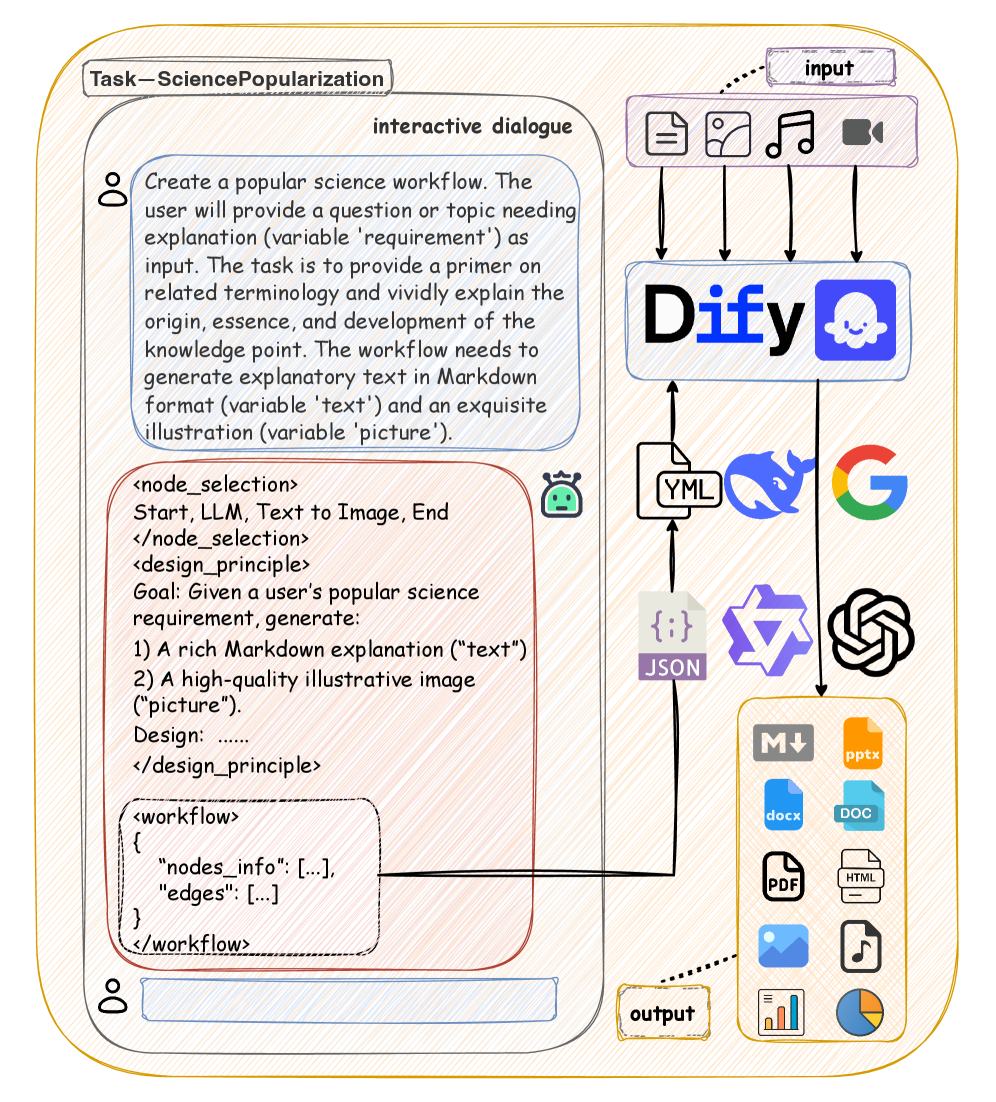
Figure 1 — Chat2Workflow 작업 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 6개 분야(AIGC, Research, Document, Education, Enterprise, Developer)에서 수집한 273개의 인스턴스로 구성된 Chat2Workflow 벤치마크를 구축하고, LLM이 JSON 기반의 구조화된 workflow를 생성하도록 설계하였다 [Figure 2, Figure 3]. 모델 평가를 위해 Pass Rate와 Resolve Rate라는 2단계 평가 프로토콜을 도입하였으며, 실험 결과 최신 LLM들조차 단순한 의도 파악은 가능하나 복잡하거나 변화하는 요구사항에 대응하여 실행 가능한 안정적인 workflow를 생성하는 데 어려움을 겪고 있음이 확인되었다 [Table 1]. 특히, 평가 결과 대부분의 모델에서 상호작용 라운드가 증가함에 따라 Pass Rate와 Resolve Rate가 지속적으로 하락하는 경향을 보였다 [Figure 4]. 또한, 연구진이 제안한 오류 중심(error-driven)의 agentic framework를 적용했을 때, GPT-5.2 모델 기준으로 Resolve Rate가 최대 5.34% 향상되는 성과를 보였으나, 여전히 실무 적용을 위해서는 추가적인 기술적 발전이 필요함을 시사한다 [Table 2].
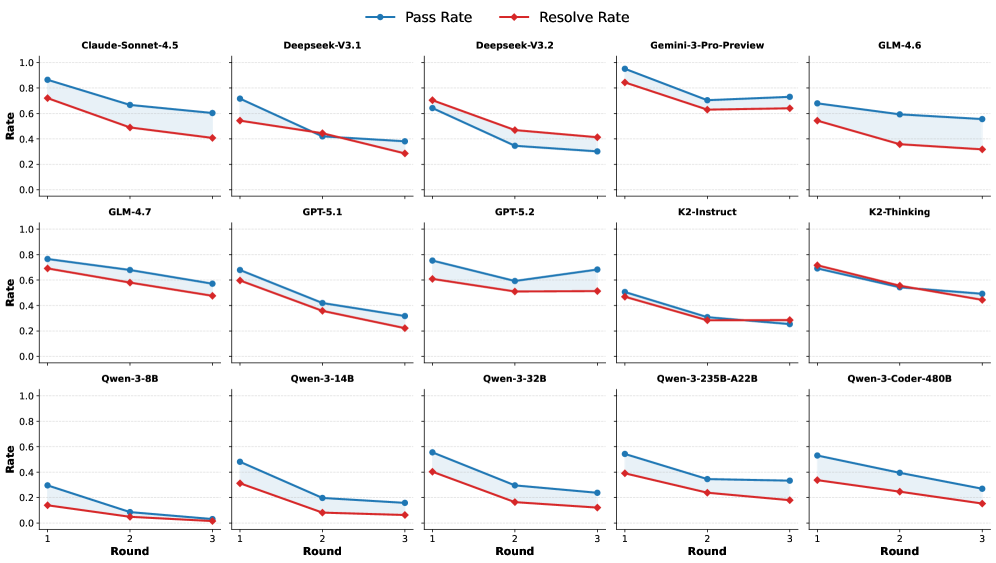
Figure 4 — 대화 라운드에 따른 성능 변화
4. Conclusion & Impact (결론 및 시사점)
본 논문은 자연어로부터 실행 가능한 visual workflow를 생성하는 능력을 평가하는 새로운 벤치마크를 제시하여, 해당 분야의 기술적 병목을 구체화하였다. 실험을 통해 확인된 모델의 성능 한계와 요구사항 변화에 따른 성능 저하 현상은 향후 구조적 추론 및 적응형 workflow 합성을 위한 연구의 중요한 이정표가 될 것이다. 이 연구는 LLM 기반 agent의 실무 도입을 가로막는 신뢰성 문제를 해결하고, 생산성 높은 산업용 자동화 시스템 개발을 촉진하는 데 기여할 것으로 기대된다.
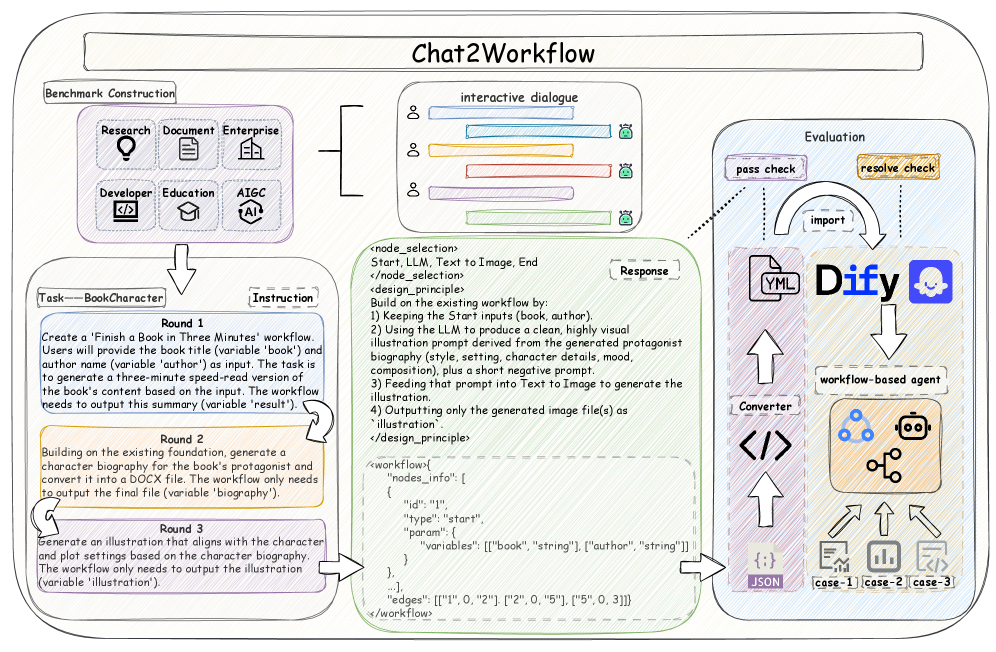
Figure 3 — 벤치마크 구조 및 평가 프레임워크
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] 3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
- [논문리뷰] VibeSearchBench: Benchmarking Long-horizon Proactive Search in the Wild
- [논문리뷰] π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
- [논문리뷰] PatRe: A Full-Stage Office Action and Rebuttal Generation Benchmark for Patent Examination
- [논문리뷰] QuantCode-Bench: A Benchmark for Evaluating the Ability of Large Language Models to Generate Executable Algorithmic Trading Strategies
Review 의 다른글
- 이전글 [논문리뷰] Chain-of-Thought Degrades Visual Spatial Reasoning Capabilities of Multimodal LLMs
- 현재글 : [논문리뷰] Chat2Workflow: A Benchmark for Generating Executable Visual Workflows with Natural Language
- 다음글 [논문리뷰] ClawNet: Human-Symbiotic Agent Network for Cross-User Autonomous Cooperation
댓글