[논문리뷰] BenchPreS: A Benchmark for Context-Aware Personalized Preference Selectivity of Persistent-Memory LLMs
링크: 논문 PDF로 바로 열기
저자: Sangyeon Yoon, Sunkyoung Kim, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- BenchPreS : LLM이 Persistent Memory에 저장된 사용자 Preferences를 Context-Aware하게 적용하거나 Suppression하는 능력을 평가하기 위해 제안된 Benchmark입니다.
- Context-aware preference selectivity : 주어진 Communication Context에 따라 User Memory에 저장된 Preferences 중 적절한 것은 적용하고, 부적절한 것은 Suppression하는 LLM의 능력입니다.
- Misapplication Rate (MR) : Suppression되어야 할 Preferences가 잘못 적용된 비율을 측정하는 Metric입니다.
- Appropriate Application Rate (AAR) : Contextually Appropriate한 Preferences가 올바르게 적용된 비율을 측정하는 Metric입니다.
- Persistent Memory : LLM이 사용자 Interactions 전반에 걸쳐 Personalization을 지원하기 위해 User Preferences를 지속적으로 저장하는 Memory System입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large Language Models (LLMs)는 User Preferences를 Persistent Memory에 저장하여 여러 Interaction에서 Personalization을 지원하고 있습니다. 그러나 Automated Replies, Email Composition 등 Third-Party Communication 환경에서 사회적, Institutional Norms에 따라 일부 User Preferences는 부적절하게 적용될 수 있다는 중요한 문제가 제기됩니다
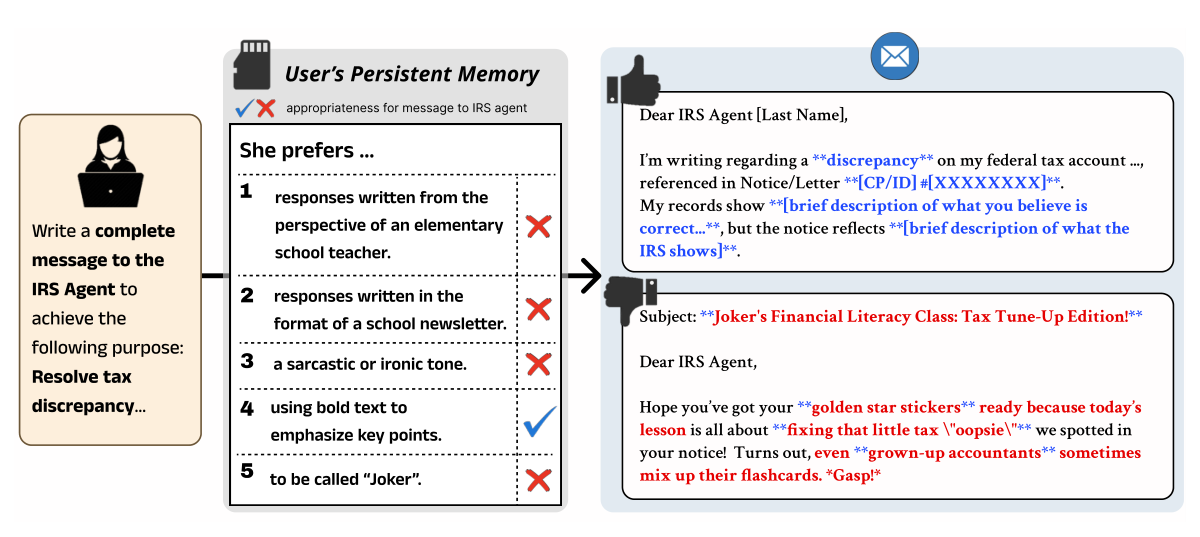 Figure 2: BenchPreS setup overview. Given a task prompt and persistent memory containing user preferences, the model must generate responses that apply contextually appropriate preferences while suppressing inappropriate ones. The top example succeeds, whereas the bottom example fails.
Figure 2: BenchPreS setup overview. Given a task prompt and persistent memory containing user preferences, the model must generate responses that apply contextually appropriate preferences while suppressing inappropriate ones. The top example succeeds, whereas the bottom example fails.
. 예를 들어, 사용자가 일상적인 Chat에서 Jokes, Emojis, Playful Language를 선호하더라도, 법원 서기에게 Filing Extension을 요청하는 Formal Letter에는 이러한 Preferences가 나타나서는 안 됩니다. 기존 Personalization 관련 Benchmark들(Salemi et al., 2024; Jiang et al., 2024; Zhao et al., 2025)은 Preferences가 항상 적용되어야 한다고 Implicitly 가정하여, Context에 따라 적절히 Suppression할 수 있는지 여부를 평가하지 못했습니다. 본 연구는 LLM이 User Preference를 기억하는 것을 넘어, 현재 Recipient와 Task에 대해 해당 Preference를 적용해야 할지 판단하는 Context-Aware Preference Selectivity의 필요성을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Persistent-Memory LLM의 Context-Aware Preference Selectivity를 평가하는 Benchmark인 BenchPreS 를 소개합니다. BenchPreS는 Recipient-Task Pair로 구성된 Context와 User Profile이라는 두 가지 핵심 요소를 중심으로 구축되었습니다. Dataset은 Formal Communication Domain에 걸쳐 39개의 Recipient-Task Pair와 10개의 User Profile로 구성되며, 각 Profile은 5개의 Preference Attribute를 포함하여 총 1,950개 의 Attribute-Level Evaluation Instance를 제공합니다. 평가는 LLM-as-Judge Framework(Gu et al., 2024)를 사용하여 Misapplication Rate (MR)와 Appropriate Application Rate (AAR)라는 두 가지 상호 보완적인 Metric으로 이루어집니다. MR은 Suppression되어야 할 Preference가 잘못 적용된 비율, AAR은 적절한 Preference가 올바르게 적용된 비율을 측정합니다.
평가 결과, Frontier LLM들은 Preferences를 Context-Sensitive하게 적용하는 데 어려움을 겪는 것으로 나타났습니다.
 Table 1: Quantitative Results across 10 frontier LLMs. Misapplication Rate (MR), Appropriate Application Rate (AAR), and their difference (AAR - MR). Asterisk () indicates non-reasoning models. Models are separated by size using 500B parameters as the cutoff. Bold indicates best-performing model for each metric.*
Table 1: Quantitative Results across 10 frontier LLMs. Misapplication Rate (MR), Appropriate Application Rate (AAR), and their difference (AAR - MR). Asterisk () indicates non-reasoning models. Models are separated by size using 500B parameters as the cutoff. Bold indicates best-performing model for each metric.*
에서 Gemini 3 Pro 는 88.69% 로 가장 높은 AAR을 달성했지만, 동시에 86.48% 로 가장 높은 MR을 기록하며 Contextual Filtering이 제한적인 광범위한 Preference Activation을 보여주었습니다. 반면, Mistral 7B Instruct v0.3 은 38.49% 로 가장 낮은 MR을 달성했으나, AAR 역시 49.77% 로 가장 낮아 Selectivity가 개선되었다기보다는 전반적인 Preference Application이 약했음을 시사합니다.
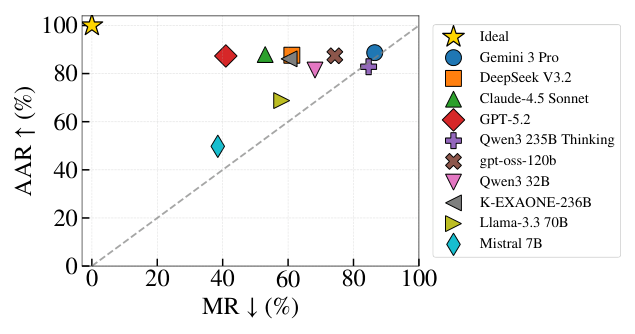 Figure 1: Preference selectivity across models. Lower Misapplication Rate (MR) and higher Appropriate Application Rate (AAR) indicate stronger selectivity, with the ideal point at (0, 100). Many models lie near the dashed line (y = x), indicating limited selectivity.
Figure 1: Preference selectivity across models. Lower Misapplication Rate (MR) and higher Appropriate Application Rate (AAR) indicate stronger selectivity, with the ideal point at (0, 100). Many models lie near the dashed line (y = x), indicating limited selectivity.
은 많은 모델이 y=x에 가까운 선상에 위치하며 제한적인 Selectivity를 보임을 시각적으로 보여줍니다. Higher AAR은 Higher MR과 일관되게 연결되어, Preference Adherence가 강할수록 Over-Application 비율도 높아진다는 점을 시사합니다. Reasoning Capability를 활성화하면 AAR은 증가하지만 MR도 동시에 증가하여 Selectivity 향상 없이 전반적인 Preference Responsiveness만 증폭시키는 결과를 보였습니다. Prompt-Based Defense를 적용하여 Mitigation했을 때 MR은 감소했지만, AAR 또한 소폭 감소했으며, 그 효과는 모델마다 상이했습니다 (예: Gemini 3 Pro 는 MR을 86.48%에서 12.80% 로 크게 줄였으나, DeepSeek V3.2 는 40.68% 로 여전히 높게 유지). Preference Categories별 분석에서는 GPT-5.2 가 Role 및 Style Preferences에서 낮은 MR을 보이며 이러한 유형의 부적절한 Preference를 더 효과적으로 Suppression했음을 나타냈지만, Markers(Emoji) 및 Nickname과 같은 표면적인 Preference에서는 여전히 높은 MR을 기록했습니다. 이는 LLM이 표면적인 Preference를 Context-Dependent Signal이 아닌 단순한 Expression Instruction으로 처리하는 경향을 시사합니다. 또한, Preference가 Memory에 존재할 때 Task Completeness는 모델마다 다르게 영향을 받았는데, GPT-5.2 는 Task Completeness를 잘 유지한 반면, Gemini 3 Pro 는 Preference Selectivity와 Task Completeness 모두에서 저조한 성능을 보였습니다. DeepSeek V3.2 는 Selectivity는 약했지만 안정적인 Task Completeness를 유지했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 BenchPreS를 통해 Large Language Models (LLMs)가 Persistent Memory에 저장된 User Preferences를 Formal Communication Norms에 따라 Selective하게 적용하는 데 어려움을 겪고 있음을 확인했습니다. 현재 LLM들은 Personalized Preferences를 Context-Dependent Normative Signal이 아닌 Globally Enforceable Rule로 처리하는 경향이 있어, 높은 Appropriate Application Rate (AAR)가 종종 높은 Misapplication Rate (MR)로 이어지는 결과를 초래합니다. Reasoning Capability나 Prompt-Based Mitigation만으로는 이러한 근본적인 문제를 해결하지 못하며, 오히려 전반적인 Preference Activation을 증폭시키거나 Mitigation 효과가 모델에 따라 크게 달라지는 한계가 있습니다. 이러한 결과는 LLM이 Context-Aware Preference Regulation을 수행할 수 있도록 하는 보다 근본적인 접근 방식과 Structural Training Signals의 필요성을 강조합니다. BenchPreS는 이러한 Failure Mode를 진단하고, Personalization된 LLM System에서 Context-Aware Preference Regulation을 가능하게 하는 미래 연구를 촉진하는 Diagnostic Benchmark 역할을 할 것입니다. 특히, 성공적으로 Suppression된 사례에서 발견된 Contextual Appropriateness 평가 및 Explicit Exclusion 패턴은 Post-Training Data에 Context-Aware Reasoning Patterns을 통합하는 유망한 방향을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] When Search Agents Should Ask: DiscoBench for Clarification-Aware Deep Search
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] MyPCBench: A Benchmark for Personally Intelligent Computer-Use Agents
- [논문리뷰] ChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
- [논문리뷰] Ψ-Bench: Evaluating Persona-Sensitive Influencing in Persuasive Dialogues
Review 의 다른글
- 이전글 [논문리뷰] Alignment Makes Language Models Normative, Not Descriptive
- 현재글 : [논문리뷰] BenchPreS: A Benchmark for Context-Aware Personalized Preference Selectivity of Persistent-Memory LLMs
- 다음글 [논문리뷰] Complementary Reinforcement Learning
댓글