[논문리뷰] Alignment Makes Language Models Normative, Not Descriptive
링크: 논문 PDF로 바로 열기
저자: Eilam Shapira, Moshe Tennenholtz, et al.
키워: LLM alignment, normative bias, descriptive behavior, strategic games, behavioral economics, RLHF, DPO
1. Key Terms & Definitions (핵심 용어 및 정의)
- Alignment : Post-training optimization process for Large Language Models (LLMs), typically via Reinforcement Learning from Human Feedback (RLHF) or Direct Preference Optimization (DPO), to align their outputs with human preferences or instructions.
- Normative Bias : Alignment 과정에서 LLM이 인간이 이상적으로 행동해야 한다고 여기는 (normative) 방식을 따르도록 편향되는 현상으로, 인간이 실제로 행동하는 (descriptive) 방식과 다를 수 있다.
- Descriptive Behavior : 사회 및 행동 과학에서 인간이 실제로 어떻게 행동하는지를 설명하는 개념으로, 종종 합리적인 (normative) 예측에서 벗어나 상호작용 기록, 감정, 휴리스틱 등에 의해 영향을 받는다.
- Strategic Games : 여러 플레이어가 각자의 이익을 최대화하기 위해 상호작용하며 의사결정을 내리는 상황을 모델링하는 게임 이론적 구조를 의미한다. 본 논문에서는 Bargaining, Persuasion, Negotiation, Repeated Matrix Games를 포함한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Large Language Models (LLMs)는 homo silicus로서 인간 행동을 시뮬레이션하고 예측하는 데 광범위하게 활용되고 있습니다. 그러나 이러한 연구의 대부분은 aligned models 를 사용하며, alignment가 행동 예측에 중립적이거나 유익하다고 암묵적으로 가정합니다. 저자들은 이 가설에 의문을 제기하며, alignment가 인간 평가자들이 선호하는 '협력적이고 공정하며 사회적으로 적절한' 응답에 모델을 최적화하지만, 실제 전략적 상황에서의 인간 행동은 종종 bluff, retaliation 등 이러한 규범적 패턴에서 벗어난다는 점을 지적합니다. 이로 인해 alignment가 LLM에 normative bias 를 유발하여, 인간이 지지하는 행동을 예측하도록 학습시키지만 실제로 보이는 행동은 그렇지 못할 수 있다는 문제가 발생합니다. 기존 연구들은 alignment가 출력 다양성을 감소시키고 특정 그룹의 의견으로 수렴시키는 alignment tax를 보였지만, 이러한 변화가 멀티라운드 전략적 상호작용에서 인간 행동 예측의 fidelity 에 미치는 영향은 아직 체계적으로 검증되지 않았습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 120개 의 same-provider base-aligned model pairs 를 23개 모델 제품군에서 비교하여 alignment의 효과를 고립적으로 분석했습니다. 이들은 Bargaining , Persuasion , Negotiation , Repeated Matrix Games 의 네 가지 멀티라운드 전략 게임 시나리오에서 총 10,050건 의 실제 인간 의사결정을 예측하는 실험을 수행했습니다. 모델의 예측 능력은 P_accept 예측과 실제 인간 행동 간의 Pearson correlation 으로 측정되었습니다.
핵심 결과는 다음과 같습니다:
- 멀티라운드 전략 게임 : Base models 는 aligned models 를 9.7:1 (213 대 22) 의 압도적인 비율로 능가하며, p-value는 10^-40 미만 으로 모든 게임 가족에서 개별적으로 유의미한 우위를 보였습니다
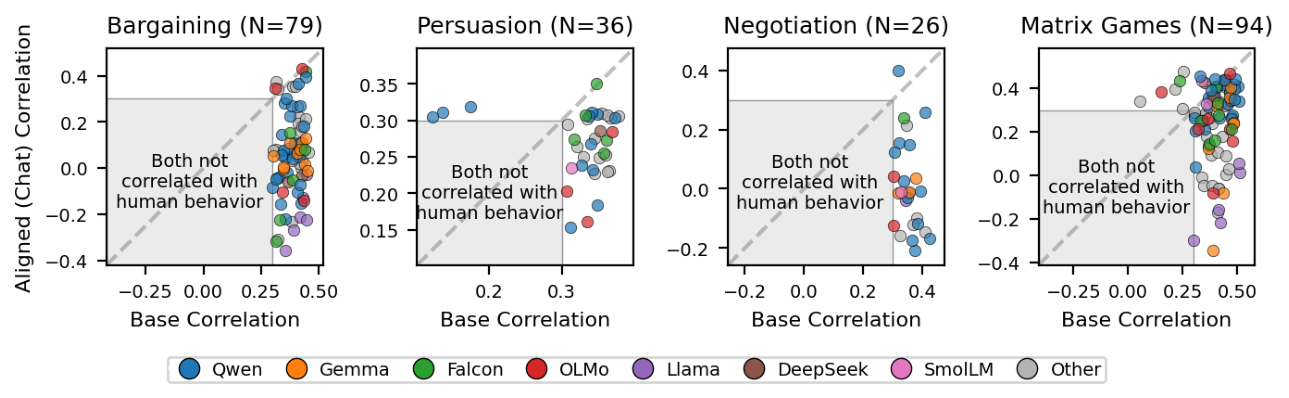 Figure 1: Pearson correlations of base models and human decisions (x-axis) vs. aligned models and human decisions (y-axis) across four game families.
Figure 1: Pearson correlations of base models and human decisions (x-axis) vs. aligned models and human decisions (y-axis) across four game families.
. 이 우위는 23개 모델 제품군, 10개 프롬프트 변형, 모든 게임 구성 매개변수에 걸쳐 robust 하게 나타났으며, 모델의 scale 이 커질수록 더욱 뚜렷해졌습니다
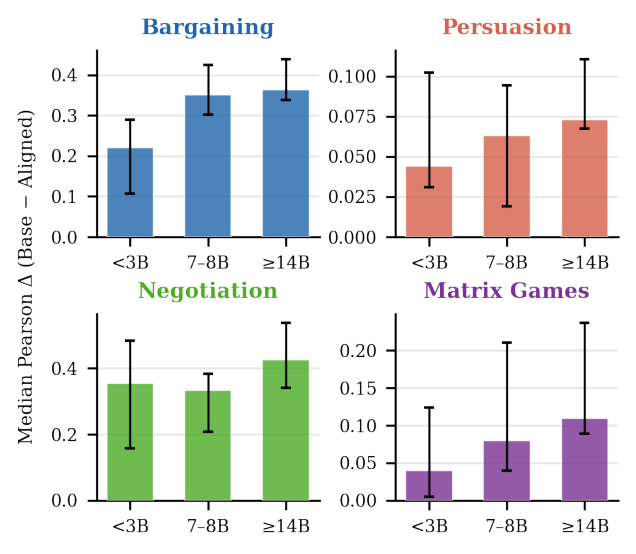 Figure 2: Median Pearson correlation difference (base minus aligned) by model size, with 95% bootstrap confidence intervals (5,000 resamples, percentile method).
Figure 2: Median Pearson correlation difference (base minus aligned) by model size, with 95% bootstrap confidence intervals (5,000 resamples, percentile method).
. 2. Boundary Conditions (규범적 설정) : 반면, 인간 행동이 normative predictions 에 더 가깝게 따르는 설정에서는 이 패턴이 역전되었습니다. Aligned models 는 one-shot 2x2 matrix games 에서 4.1:1 (57 대 14) 의 비율로 승리하며 p-value는 10^-6 미만 이었고
 Table 2: Base vs. aligned wins on one-shot 2 × 2 games by game type (N = 71 pairs). p: one-sided binomial test.
Table 2: Base vs. aligned wins on one-shot 2 × 2 games by game type (N = 71 pairs). p: one-sided binomial test.
, 비전략적 binary lottery choices 에서도 2.2:1 (62 대 28) 의 비율로 우세했습니다. One-shot games 에서 aligned models 의 예측은 Nash equilibrium 과 더 높은 상관관계(aligned 모델: r=0.41 , base 모델: r=0.28 )를 보였으며, 이는 alignment가 예측을 규범적 패턴으로 전환시켰음을 시사합니다. 또한, 멀티라운드 게임의 첫 번째 라운드 에서는 aligned models 가 우위를 보이다가, 상호작용 이력이 축적되면서 base models 가 우위를 차지하는 round-by-round dynamics가 관찰되었습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 alignment가 Large Language Models (LLMs)에 normative bias 를 부여하여, 모델이 인간이 마땅히 그래야 한다고 생각하는 방식대로 행동을 예측하게 하며, 이는 인간이 실제로 보이는 복잡한 descriptive behavior 를 예측하는 능력을 저해한다는 것을 보여줍니다. Alignment tax 는 단순한 기능 저하가 아니라, KL-regularized reward maximization 이 base distribution을 annotator-approved behavioral modes 에 지수적으로 집중시켜, reciprocity , retaliation , reputation dynamics 와 같은 미묘하고 복잡한 행동 패턴이 존재하는 tails를 억압하기 때문에 발생합니다. 이러한 발견은 LLM을 인간 행동의 대리인으로 사용하는 연구에 중요한 시사점을 제공합니다. 멀티라운드 대화형 전략 환경에서는 base models 가 선호되어야 하지만, one-shot 또는 비전략적 작업에서는 aligned models 가 더 적합할 수 있습니다. 궁극적으로, annotator preferences 를 반영하는 단일 보상 모델에 최적화하는 현재의 alignment 방법론으로는 인간 행동의 전체 분포를 보존하는 것이 어렵다는 normative-descriptive trade-off가 존재하며, 이는 LLM을 인간 행동 모델로 활용할 것인지, 아니면 인간 사용에 최적화된 도구로 활용할 것인지에 대한 근본적인 모델링 가정을 결정합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] AdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
- 현재글 : [논문리뷰] Alignment Makes Language Models Normative, Not Descriptive
- 다음글 [논문리뷰] BenchPreS: A Benchmark for Context-Aware Personalized Preference Selectivity of Persistent-Memory LLMs
댓글