[논문리뷰] Complementary Reinforcement Learning
링크: 논문 PDF로 바로 열기
저자: Dilxat Muhtar, Jiashun Liu, Wei Gao, Weixun Wang, Shaopan Xiong, Ju Huang, Siran Yang, Wenbo Su, Jiamang Wang, Ling Pan, Bo Zheng et al.
키워: Reinforcement Learning, LLM Agents, Sample Efficiency, Experience Replay, Co-evolution, Complementary Learning Systems, Policy Actor, Experience Extractor
1. Key Terms & Definitions (핵심 용어 및 정의)
- Complementary RL : 신경과학의
Complementary Learning Systems에서 영감을 받아 제안된 프레임워크로,RL최적화 루프 내에서Experience Extractor와Policy Actor의 원활한co-evolution을 달성한다. - Policy Actor (πθ) :
LLM-based agent로,sparse outcome-based rewards를 통해 최적화되어 실제 태스크를 수행한다. - Experience Extractor (πφ) : 원본
trajectory에서structured textual knowledge(experience)를 추출하고experience bank를 관리하도록 최적화된 모델이다. - Experience Bank (M) : 과거
trajectory에서 추출된structured textual knowledge를 저장하는 저장소로,Policy Actor의 학습을 가이드하는 데 사용된다. - Distributional Misalignment : 정적으로 저장된 과거
experience와actor의 진화하는 능력 사이의 점진적인 불일치 현상이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Reinforcement Learning (RL)은 Large Language Models (LLM) 기반 agent의 agentic capabilities를 향상시키는 데 강력한 패러다임으로 부상했지만, sparse outcome feedback과 agent가 episode 전반의 prior experience를 활용하지 못하는 문제로 인해 낮은 sample efficiency라는 한계에 직면해 있다. historical experience를 활용하여 agent를 보강하는 기존 접근 방식들은 치명적인 약점을 가지고 있다. 바로 history에서 추출된 experience가 정적으로 저장되거나 improving actor와 함께 co-evolve하지 못하여, 훈련 과정에서 experience와 actor의 진화하는 능력 사이에 progressive misalignment가 발생하여 유용성이 저하된다는 점이다. 결과적으로 수집된 rollout에 포함된 풍부한 procedural information (예: 효과적인 행동, 복구 가능한 실패 패턴, 중요한 의사 결정 지점)이 대부분 활용되지 않아 agent의 학습 과정이 sample-inefficient해진다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 비효율성을 완화하기 위해 신경과학의 complementary learning systems에서 영감을 받아 RL 최적화 루프 내에서 experience extractor와 policy actor의 원활한 co-evolution을 달성하는 Complementary RL 을 제안한다. 구체적으로, actor는 sparse outcome-based rewards를 통해 최적화되는 반면, experience extractor는 추출된 experience가 actor의 성공에 기여하는지에 따라 최적화되어 actor의 성장하는 능력과 발맞춰 experience management strategy를 발전시킨다. 이 프레임워크는 Primary Training Loop와 Background Track으로 구성된 asynchronous dual-loop design 을 통해 rollout collection과 experience distillation을 분리하며, Experience Manager (H)가 Experience Consolidation 및 Experience Retrieval을 담당한다. 특히, Query Batching, Parallel Search, Periodic Merge 등의 메커니즘을 통해 experience bank (M)을 효율적으로 관리한다.
실험 결과, Complementary RL 은 experience를 학습하지 않는 outcome-based agentic RL baselines를 일관적으로 능가한다. 단일 태스크 시나리오에서 10% 의 성능 향상(멀티태스크 환경에서는 +8.7% relative performance gain
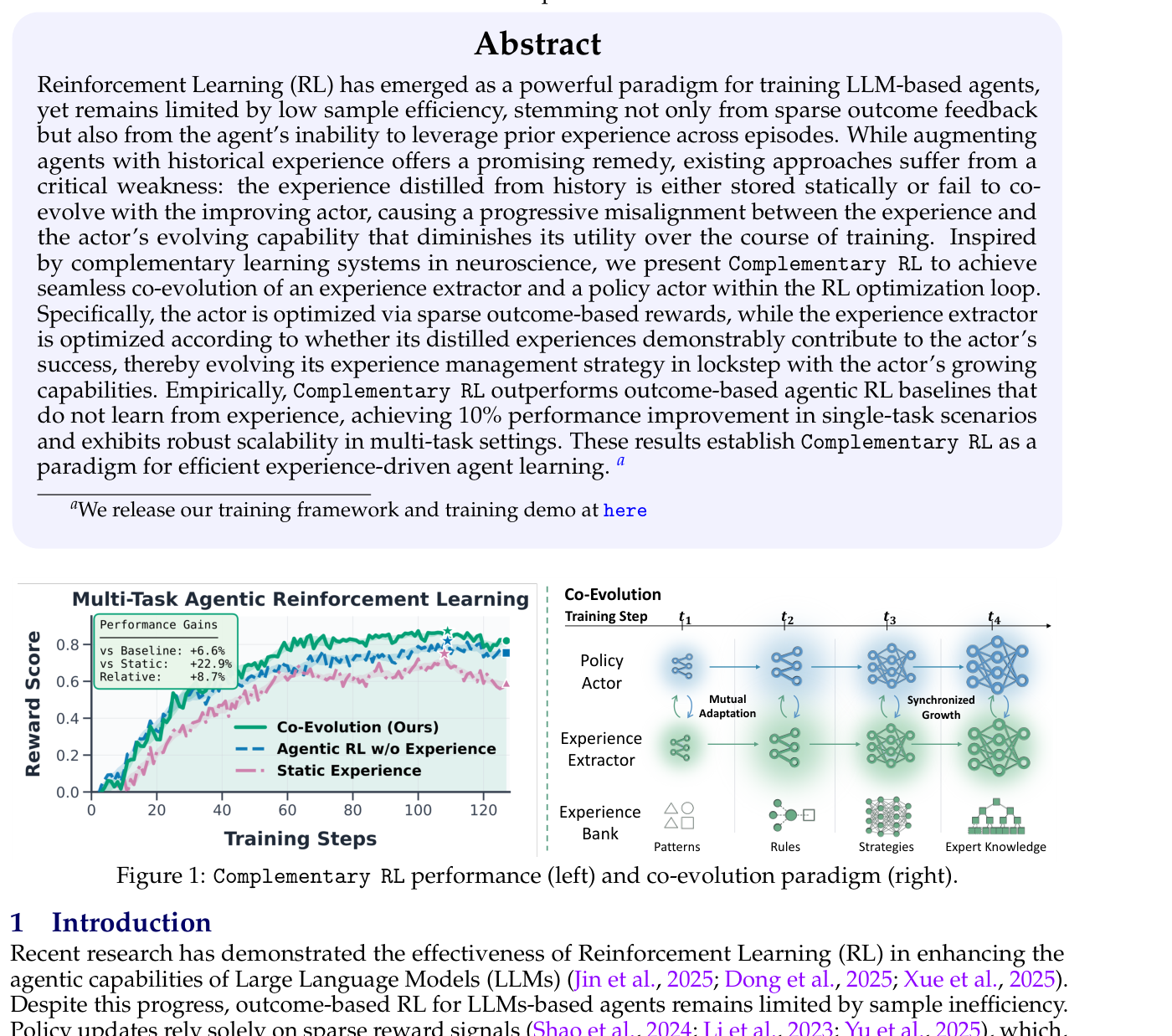 Figure 1: Complementary RL performance (left) and co-evolution paradigm (right).
Figure 1: Complementary RL performance (left) and co-evolution paradigm (right).
달성), MiniHack Room 및 ALFWorld에서 1.3배 의 성능 마진과 뛰어난 학습 안정성을 보였다 [Figure 6]. challenging software engineering benchmark인 SWE-Bench에서는 baseline 대비 +3.0% 의 향상을 보여주었다. 또한, MiniHack Room에서 1.5배 , ALFWorld에서 2배 더 적은 action으로 태스크를 완료하여 distilled experience가 더 효과적인 의사결정을 유도함을 입증했다 [Figure 7]. 멀티태스크 환경에서도 Complementary RL 은 Baseline, Static Online Exp., Exp. Only 대비 우수한 성능을 보였으며 [Figure 8, Table 1], test time에 experience를 활용할 경우 baseline 대비 평균 +7% 의 성능 향상을 달성했다. rollout collection 과정에서 추가적인 latency는 거의 발생하지 않았다 [Figure 9c]. 더 강력한 experience extractor를 사용할 경우 평균 +5% 의 추가 성능 향상이 가능함을 확인했다 [Figure 9a].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RL training process 전반에 걸쳐 agent가 experience를 효과적으로 활용하고 축적할 수 있도록 하는 통합된 알고리즘 및 인프라 co-design framework인 Complementary RL 을 제시한다. 이 방법론은 experience construction 및 management를 고정된 extractor를 가진 정적 구성 요소로 취급하지 않고, policy actor와 experience extractor를 비동기식 dual-loop 내에서 함께 훈련한다. 이러한 co-evolutionary design은 actor의 성장하는 능력이 extractor가 추출하는 experience를 지속적으로 재구성하고, extractor의 개선된 출력이 actor의 학습을 가속화하여 상호적이고 지속적으로 성능을 향상시킨다. 결과적으로 LLM agent의 sample efficiency를 크게 향상시키며, 복잡한 대화형 환경에서 보다 유능하고 적응력 있는 LLM agent 개발을 위한 새로운 패러다임을 확립하는 데 기여한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] BenchPreS: A Benchmark for Context-Aware Personalized Preference Selectivity of Persistent-Memory LLMs
- 현재글 : [논문리뷰] Complementary Reinforcement Learning
- 다음글 [논문리뷰] Conservative Offline Robot Policy Learning via Posterior-Transition Reweighting
댓글