[논문리뷰] Conservative Offline Robot Policy Learning via Posterior-Transition Reweighting
링크: 논문 PDF로 바로 열기
저자: Wanpeng Zhang, Ziheng Xi, Hao Luo, Sipeng Zheng, Haoqi Yuan, Yicheng Feng, Haoqing Liu, Haiweng Xu, Zongging Lu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Posterior-Transition Reweighting (PTR) : 이 논문에서 제안하는 reward-free sample scoring mechanism으로, post-action consequences를 identification posterior로 변환하여 데이터 샘플의 weight를 재조정하는 방법론입니다.
- Vision-Language-Action (VLA) models : Vision encoders, language models, 그리고 action decoders를 통합하여 end-to-end robot policy를 구현하는 모델입니다.
- Being-H0.5 : 이 연구에서 baseline으로 사용된 state-of-the-art VLA model의 backbone으로, heterogeneous robots를 unified action space로 mapping하여 cross-embodiment pretraining을 가능하게 합니다.
- BeliefTokenizer : PTR의 구성 요소 중 하나로, current-step features를 next-step belief proxy tokens으로 압축하여 상호작용 기록(interaction history)을 요약합니다.
- Identification Posterior : 유한한 후보 풀(candidate pool) 내의 target들에 대한 softmax 분포로, 기록된 action chunk가 현재 policy context에 얼마나 attributable한지를 나타내는 척도입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Vision-Language-Action (VLA) model의 발전은 large-scale multi-robot dataset을 통해 robot policy를 pretrain하는 데 큰 진전을 보였습니다. 하지만 이러한 dataset들은 본질적으로 heterogeneity 와 suboptimal demonstrations 를 포함하며, 표준 supervised fine-tuning (SFT) 방식은 모든 demonstration을 동일하게 취급하여 성능 저하로 이어질 수 있습니다. 특히 noisy하거나 cross-embodiment 데이터의 경우 더욱 그렇습니다. 기존의 reward-weighted regression (AWR) 같은 방법론들은 reward signal을 필요로 하지만, 실제 로봇 데이터에서는 reward label을 얻기 어렵거나 신뢰성이 떨어지는 경우가 많습니다. 따라서 저자들은 reward label이나 tractable policy likelihood 없이도 데이터 품질을 평가하고 cross-embodiment transfer를 선택적으로 활용할 수 있는 새로운 접근 방식의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Posterior-Transition Reweighting (PTR) 이라는 새로운 method를 제안합니다. PTR은 표준 offline post-training에 conservative reweighting mechanism을 추가합니다. 핵심적으로, BeliefTokenizer 를 사용하여 interaction history를 compact한 belief proxy token으로 요약하며, lightweight consequence encoder와 transition scorer는 post-action consequences를 per-sample quality signal로 변환하여 identification posterior 를 생성합니다
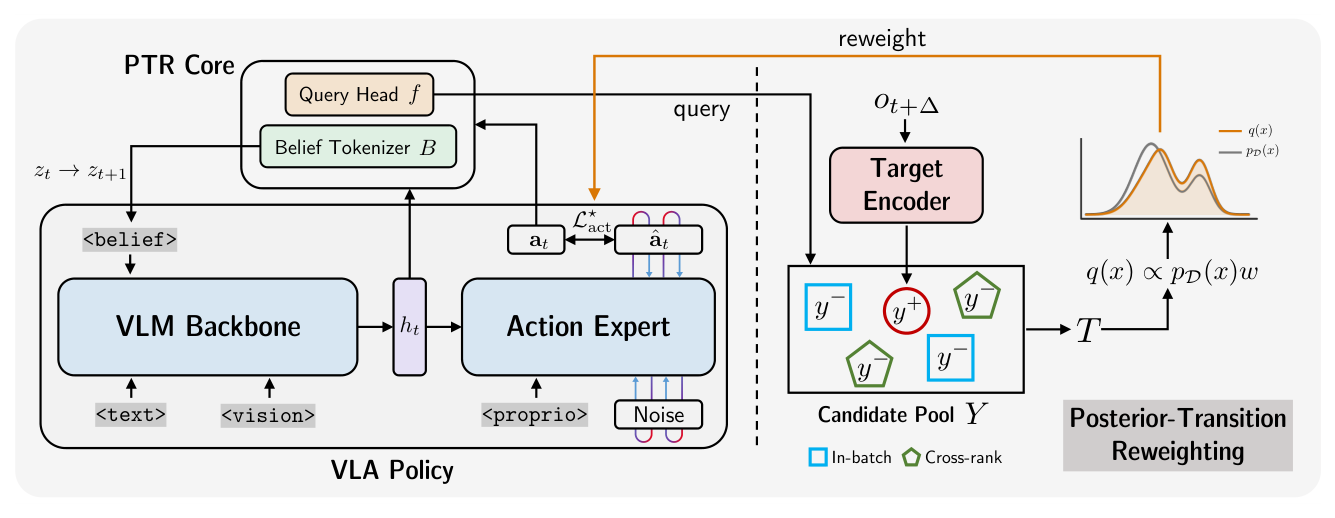 Figure 1: Overview of PTR. Left: the standard policy stack (backbone + action expert) is augmented with a lightweight scorer and a BeliefTokenizer. Right: for each training chunk, the scorer identifies the matched post-action target among mismatched candidates; the resulting identification posterior is converted into a conservative weight that rescales the supervised action loss. No reward labels or policy likelihoods are needed.
Figure 1: Overview of PTR. Left: the standard policy stack (backbone + action expert) is augmented with a lightweight scorer and a BeliefTokenizer. Right: for each training chunk, the scorer identifies the matched post-action target among mismatched candidates; the resulting identification posterior is converted into a conservative weight that rescales the supervised action loss. No reward labels or policy likelihoods are needed.
. 이 posterior는 reward-free 방식으로 각 training chunk의 quality를 평가하며, 이후 conservative weight ($w_t$)로 변환되어 supervised action loss를 re-scale합니다 [Eq 21, Eq 27]. 이 과정에서 reward label이나 policy likelihood는 필요하지 않습니다. PTR은 KL divergence 및 bounded density ratio 와의 이론적 연결을 통해 weight의 conservatism을 보장합니다 [Proposition 1, Proposition 2]. 또한, adaptive scale controller 가 scorer temperature, advantage scaling, hard-negative ratio를 조정하여 training stability를 유지합니다.
주요 실험 결과는 다음과 같습니다:
- Simulation Benchmarks: Clean training data에서 PTR은 LIBERO 에서 97.8% (SFT 98.3%), RoboCasa 에서 55.6% (SFT 54.2%)의 성공률을 기록하며, 기존 SFT와 경쟁하거나 능가하는 성능을 보였습니다. 특히 Object (99.2%) 및 Long-Horizon (97.0%) suite에서 SFT 대비 더 높은 성공률을 달성했습니다.
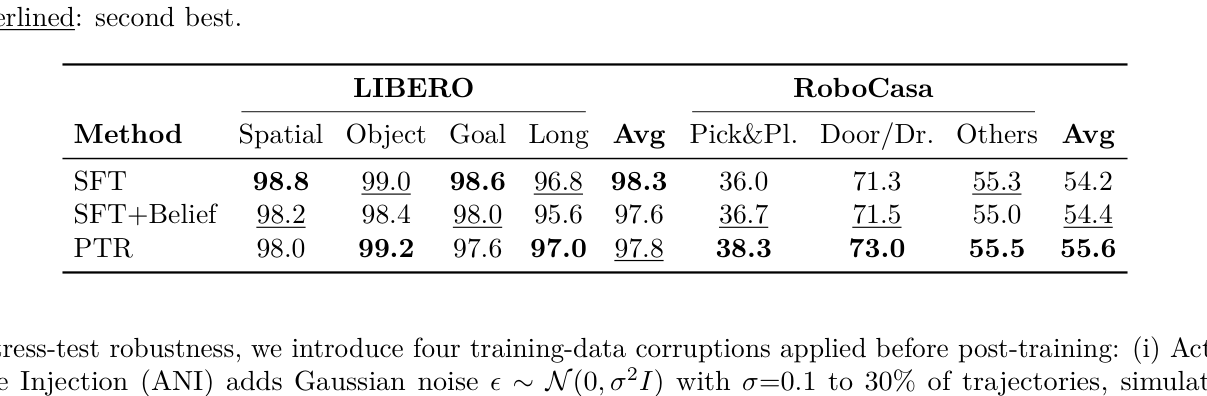 Table 1: Standard simulation results (success rate %) on LIBERO and RoboCasa. LIBERO reports per-suite averages over 500 episodes each; RoboCasa reports category averages over 1200 total trials. Bold: best; Underlined: second best.
Table 1: Standard simulation results (success rate %) on LIBERO and RoboCasa. LIBERO reports per-suite averages over 500 episodes each; RoboCasa reports category averages over 1200 total trials. Bold: best; Underlined: second best.
- Robustness to Corrupted Data: Action Noise, Trajectory Truncation, Label Noise 및 이들의 Combined corruption 조건에서 PTR은 SFT 대비 훨씬 뛰어난 robustness 를 입증했습니다. Combined corruption의 경우, LIBERO에서 +5.6 pp , RoboCasa에서 +9.4 pp 의 절대적인 성능 향상을 보였습니다.
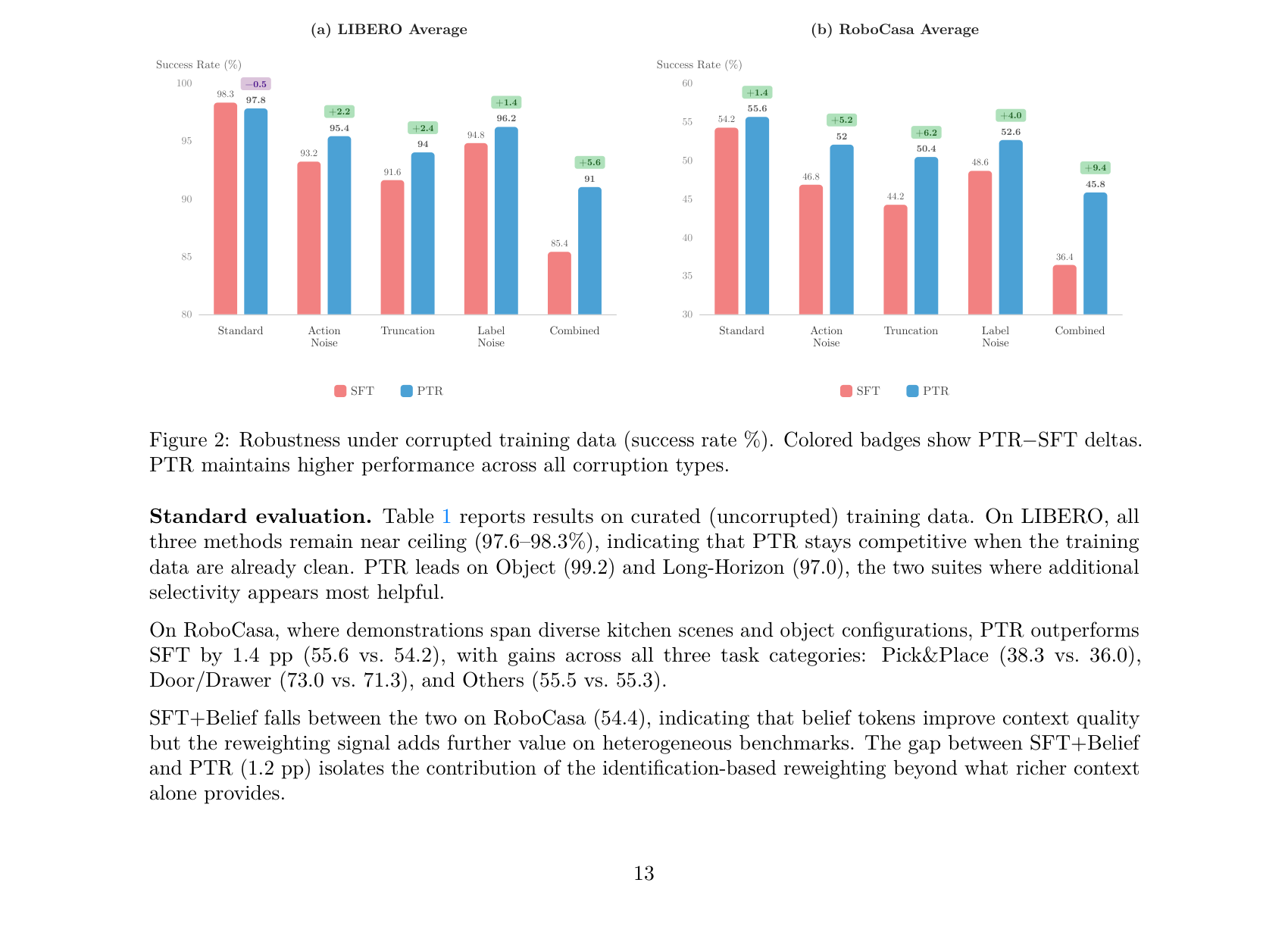 Figure 2: Robustness under corrupted training data (success rate %). Colored badges show PTR–SFT deltas. PTR maintains higher performance across all corruption types.
Figure 2: Robustness under corrupted training data (success rate %). Colored badges show PTR–SFT deltas. PTR maintains higher performance across all corruption types.
- Real-Robot Evaluation [Table 3]: 세 가지 실제 로봇 플랫폼에서 진행된 specialist training에서 PTR은 SFT 대비 평균 +6.3 pp (67.1% vs 60.8%)의 성공률 향상을 보였습니다. Generalist training에서는 PTR이 cross-embodiment conflicts로 인한 성능 저하를 3.3 pp 로 제한하며, SFT-Generalist 대비 +13.8 pp (72.1% vs 65.7%)의 성능 격차를 벌렸습니다.
4. Conclusion & Impact (결론 및 시사점)
PTR은 reward label이나 tractable policy likelihood 없이 heterogeneous robot demonstrations 전반에 걸쳐 credit을 재할당하는 conservative offline post-training method입니다. 이 method는 ambiguous하거나 noisy한 demonstration에 대한 강조를 줄여주는 "floor" 효과와, 유용한 cross-embodiment transfer를 증폭시키는 "ceiling" 효과를 동시에 제공합니다. Exponential weight mapping, clipping, 그리고 self-normalization을 통해 induced training distribution이 원래 데이터 분포와 가깝게 유지되도록 설계되어 conservatism 이 보장됩니다. 이 연구는 대규모의 heterogeneous dataset에서 로봇 학습의 robustness 와 cross-embodiment generalization 을 크게 향상시키며, 특히 reward 신호가 부족하거나 신뢰할 수 없는 환경에서 데이터 큐레이션 메커니즘으로서 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Robots Need More than VLA and World Models
- [논문리뷰] UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
- [논문리뷰] Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
- [논문리뷰] Steering Vision-Language-Action Models as Anti-Exploration: A Test-Time Scaling Approach
- [논문리뷰] Robot Learning: A Tutorial
Review 의 다른글
- 이전글 [논문리뷰] Complementary Reinforcement Learning
- 현재글 : [논문리뷰] Conservative Offline Robot Policy Learning via Posterior-Transition Reweighting
- 다음글 [논문리뷰] ESPIRE: A Diagnostic Benchmark for Embodied Spatial Reasoning of Vision-Language Models
댓글