[논문리뷰] ESPIRE: A Diagnostic Benchmark for Embodied Spatial Reasoning of Vision-Language Models
링크: 논문 PDF로 바로 열기
저자: Yanpeng Zhao, Wentao Ding, Hongtao Li, Baoxiong Jia, Zilong Zheng et al.
키워: Embodied Spatial Reasoning, Vision-Language Models, Diagnostic Benchmark, Localization, Execution, 6-DoF Manipulation, Robotics
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLM (Vision-Language Model) : 시각 및 언어 정보를 통합적으로 이해하고 추론하는 모델을 지칭합니다.
- Embodied Spatial Reasoning : 3D 물리 세계와 상호작용하고 추론하는 데 필요한 공간 인지 능력을 의미하며, Embodied Agent의 기본 구성 요소입니다.
- Localization : 주어진 지침과 장면에 따라 특정 대상 객체 또는 공간을 식별하고, 이를 2D 픽셀 좌표로 생성하는 과제를 지칭합니다.
- Execution : Localization 단계 이후 실제 로봇 환경에서
pick또는place와 같은 동작을 수행하기 위해, 목표 6-DoF pose (3D 위치 및 Orientation)를 예측하는 과제를 지칭합니다. - 6-DoF (Six Degrees of Freedom) : 객체의 3차원 공간에서의 위치 (x, y, z)와 Orientation (pitch, yaw, roll)을 모두 설명하는 자유도를 의미합니다.
- Generative Evaluation Paradigm : 모델이 미리 정의된 선택지 중 하나를 고르는 Discriminative 방식 대신, 2D 포인트나 3D pose와 같은 출력을 직접 생성하도록 요구하는 평가 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Vision-Language Models (VLMs)는 Embodied Domain에서의 공간 인지 능력을 향상시키기 위한 상당한 진전을 이루었지만, 기존의 평가 방식에는 여러 한계가 존재합니다. 현재 벤치마크는 주로 Static한 Multiple-Choice VQA (Visual-Question Answering) 방식을 채택하고 있어, Distractor에 의존하는 경향이 있어 편향에 취약합니다. 더욱이 VQA는 VLM Agent가 3D 환경에서 주어진 지침에 따라 능동적으로 act해야 하는 실제 시나리오와는 거리가 멀며, Execution 단계를 간과하거나 과도하게 단순화합니다.
 *Table 1: *
*Table 1: *
에서 볼 수 있듯이 기존 벤치마크는 Systematic한 설계나 물리적 Grounding이 부족하여 모델 발전의 반복적인 Iteration을 방해합니다. 저자들은 이러한 한계점을 극복하고 VLM의 공간 추론 능력을 진단하기 위해, 평가와 실제 배포 간의 Gap을 줄일 수 있는 새로운 Diagnostic Benchmark의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 ESPIRE 라는 Embodied Spatial Reasoning을 위한 Diagnostic Benchmark를 제안합니다. 이 벤치마크는 Isaac Sim 을 기반으로 물리적으로 Grounded된 시뮬레이션 환경에서 VLM을 평가합니다. VLM을 로봇 작업에 적용하기 위해 각 Task를 Localization (조작 가능한 Target 식별)과 Execution (해당 Action 수행)으로 분해하고, 두 단계를 Goal Position 및 Goal Pose Generation의 Generative Problems 으로 구성합니다.
 *Figure 1: *
*Figure 1: *
은 ESPIRE의 Spatial World, Spatial Aspect, Reference Frame, Reference Object, 그리고 Localization 및 Execution Task 예시를 보여줍니다. Localization 성능은 Accuracy 로 측정되며, Execution 성능은 Motion Planner를 통한 Acceptance Rate 로 평가됩니다.
ESPIRE 는 Spatial Aspect (Attribute, Distance, Relationship, Orientation), Reference Frame (Relative, Intrinsic, Absolute), Reference Object (Oriented/Non-oriented)를 포함하는 계층적 설계 철학에 따라 Tasks를 체계적으로 디자인하여, 다양한 공간 추론 시나리오와 Granularity를 포괄합니다. Functional Program으로 Task Instructions를 표현하여 3D Scene Graph에서 실행되며 Ground-truth Target을 생성합니다.
다양한 VLM (예: Gemini2.5-Pro , Qwen3-VL , InternVL3 , RoboBrain2.0 )에 대한 평가 결과는 다음과 같습니다
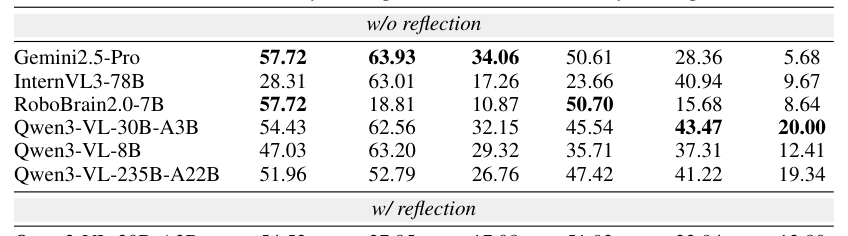 *Table 2: *
*Table 2: *
:
- VLMs 는 Localization 에서 Execution 보다 훨씬 우수한 성능을 보였으며, 이는 Passive Spatial Understanding은 양호하나 Acting-oriented Spatial Reasoning 능력이 제한적임을 시사합니다.
- 모든 Spatial Aspect 중 Orientation reasoning 이 Localization과 Execution 모두에서 가장 큰 난관으로 작용하며, 3D Rotational Geometry Grounding에 심각한 결함이 있음을 나타냅니다.
- 'Place' Tasks 는 Target Space의 추가 제약 조건과 Occlusion 문제로 인해 'pick' Tasks 보다 전반적으로 더 어렵게 나타났습니다.
- Distance reasoning 은 모든 모델에서 성능이 가장 낮게 나타났습니다.
- Reflection (이전 실패 시도에 대한 피드백)은 Localization 성능을 향상시키지만, Execution 성능은 저하시키는 경향을 보였습니다.
- Gemini2.5-Pro 는 대부분의 Metric에서 가장 강력한 성능을 보였습니다. 특히 Table 7 의 Rotation Prediction 분석 결과,
pickTask에서는 pitch 가, ConstrainedplaceTask에서는 roll 이 핵심 요소임을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
저자들은 물리적으로 Grounded된 포토리얼리스틱 환경에서 VLM의 Embodied Spatial Reasoning을 진단하는 ESPIRE 벤치마크를 성공적으로 제시했습니다. ESPIRE 는 로봇 Task를 Localization 과 Execution 으로 분해하여 Passive Spatial Understanding과 Acting-oriented Spatial Reasoning을 통합적으로 평가하며, 평가와 실제 배포 사이의 Gap을 줄입니다. 체계적인 Task 설계는 다양한 공간 추론 Context와 Granularity에 걸쳐 상세한 분석을 가능하게 합니다. 실험 결과, VLM은 Localization 보다 Execution 에서 훨씬 낮은 성능을 보였으며, 특히 3D Rotational Geometry에 대한 Grounding 부족으로 Orientation reasoning 이 가장 큰 병목 현상임을 밝혀냈습니다. ESPIRE 는 VLM의 Spatial Cognition 발전을 위한 유망한 방향을 제시하며, 향후 Architecture에 필요한 Specialized Spatial Inductive Biases를 식별하는 구체적인 로드맵을 제공합니다. 이는 실제 환경 평가를 대체하기보다는 확장 가능하고 재현 가능한 대안으로서 모델 개선을 가속화할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Conservative Offline Robot Policy Learning via Posterior-Transition Reweighting
- 현재글 : [논문리뷰] ESPIRE: A Diagnostic Benchmark for Embodied Spatial Reasoning of Vision-Language Models
- 다음글 [논문리뷰] Efficient Exploration at Scale
댓글