[논문리뷰] Efficient Exploration at Scale
링크: 논문 PDF로 바로 열기
저자: Mohammad Asghari, Chris Chute, Vikranth Dwaracherla, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLHF (Reinforcement Learning from Human Feedback) : 인간의 피드백을 활용하여 언어 모델(Language Model)을 정렬(align)하고 개선하는 강화 학습 프로세스입니다.
- Epistemic Neural Network (ENN) : 보상 모델(Reward Model)의 불확실성(uncertainty)을 모델링하기 위해 사용되는 신경망 아키텍처로, 정보 지향적 탐색(Information-Directed Exploration)의 핵심 구성 요소입니다.
- Information-Directed Exploration (IDE) : 보상 모델의 불확실성 추정치를 활용하여 인간 피드백을 위한 응답(response) 선택을 유도하는 탐색 전략입니다.
- Affirmative Nudge : Reinforcement signal에 추가되는 작은 양의 positive scalar로, 온라인 RLHF 알고리즘이 훈련 과정에서 성능이 급격히 저하되는 현상(tanking behavior)을 방지하는 데 기여합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
오늘날 대규모 언어 모델(LLM)은 방대한 데이터를 학습하며 발전했지만, LLM의 능력을 인간의 선호도에 맞춰 정렬하는 데 필요한 고품질의 informative한 데이터를 효율적으로 수집하는 것은 여전히 중요한 과제입니다. 기존의 인간 피드백 기반 강화 학습(RLHF) 기법들은 데이터 효율성이 낮아, 데이터 양이 증가해도 성능 향상이 미미한 제한적인 scalability를 보여왔습니다. 특히, 오프라인 RLHF는 고정된 샘플링 분포(fixed sampling distribution)로 인해 데이터 커버리지(data coverage) 문제와 stationary하지 않은 학습 타겟(learning targets) 문제에 직면합니다. 이러한 한계는 효율적인 탐색(exploration)이 LLM의 안전한 인공 초지능(artificial superintelligence)으로 가는 길의 초석이 되어야 한다는 점과 대비됩니다.
 Figure 1: The plots are of performance, in terms of the win rate over a baseline policy, as functions of the amount of human feedback, in terms of the number of choices observed. Efficient exploration shifts the scaling law.
Figure 1: The plots are of performance, in terms of the win rate over a baseline policy, as functions of the amount of human feedback, in terms of the number of choices observed. Efficient exploration shifts the scaling law.
은 기존 RLHF의 scaling law가 비효율적임을 시사합니다. 따라서, 본 연구는 LLM의 alignment를 위한 데이터 효율성을 획기적으로 개선하는 새로운 온라인 학습 알고리즘 개발의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 인간 피드백으로부터의 강화 학습(RLHF)을 위한 온라인 학습 알고리즘을 제안합니다. 이 알고리즘은 인간의 선택 데이터(choice data)가 수신됨에 따라 보상 모델(RM)과 언어 모델(LM)을 점진적으로 업데이트합니다. RM은 선택 데이터에 fit되며, LM은 RM이 제공하는 reinforcement signal과 함께 reinforce의 변형(variation of reinforce)을 통해 업데이트됩니다. 데이터 효율성을 획기적으로 개선하는 세 가지 핵심 혁신은 다음과 같습니다: 첫째, 각 reinforcement signal에 작은 양의 affirmative nudge 를 추가하여, 기존 온라인 RLHF 알고리즘에서 흔히 발생하는 성능 "tanking" 현상을 성공적으로 방지합니다. [Figure 4(right)]는 이 nudge의 긍정적인 효과를 보여줍니다. 둘째, 보상 불확실성(reward uncertainty)을 모델링하는 epistemic neural network (ENN) 를 사용합니다. 이 ENN은 기존 리워드 모델 아키텍처에 추가적인 입력 Z 를 받아 불확실성을 표현합니다.
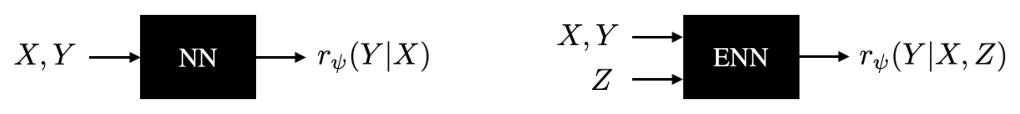 Figure 5: A neural network reward model versus an epistemic neural network reward model.
Figure 5: A neural network reward model versus an epistemic neural network reward model.
는 ENN의 아키텍처를 시각적으로 설명합니다. 셋째, 이 불확실성 추정치를 활용한 information-directed exploration 전략을 통해, 피드백 쿼리(feedback query)를 위한 informative한 응답 쌍(response pairs)을 선택하여 데이터 수집의 효율성을 극대화합니다.
제안된 알고리즘은 Gemma LLM을 사용하여 offline RLHF 대비 획기적인 데이터 효율성 개선을 입증했습니다. 구체적으로, 본 알고리즘은 20K 미만의 레이블(labels)을 사용하여 200K 레이블로 훈련된 offline RLHF의 성능과 일치하며, 이는 10배 이상의 데이터 효율성 향상을 나타냅니다. [Figure 1] 및
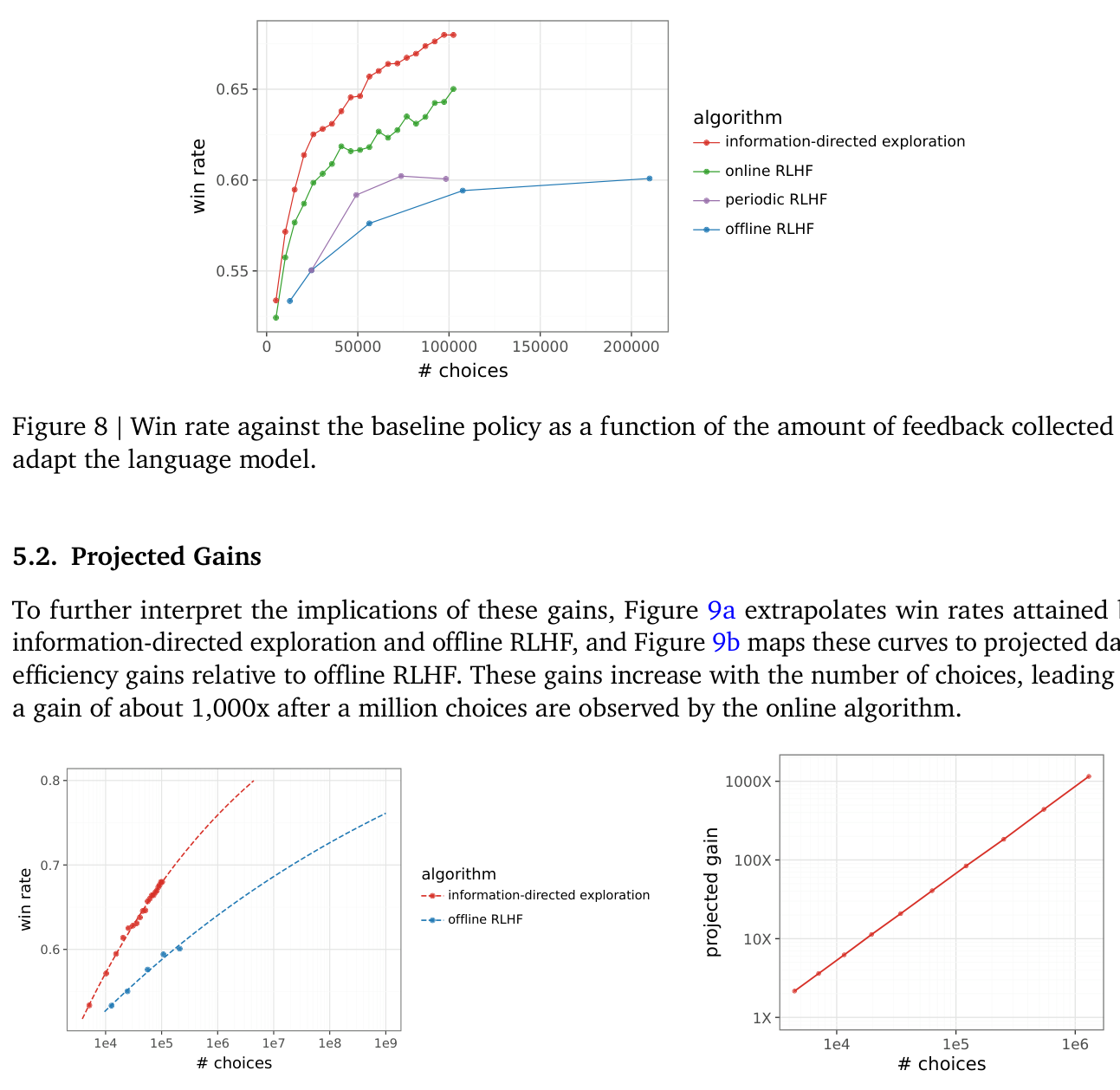 Figure 8: Win rate against the baseline policy as a function of the amount of feedback collected to adapt the language model.
Figure 8: Win rate against the baseline policy as a function of the amount of feedback collected to adapt the language model.
은 이러한 데이터 효율성 scaling law의 변화를 명확하게 보여줍니다. 나아가, 본 연구는 1M 레이블로 훈련된 제안 알고리즘이 1B 레이블로 훈련된 offline RLHF와 동등한 성능을 달성할 것으로 예상하며, 이는 1,000배 의 데이터 효율성 향상을 의미합니다. [Figure 9b]는 이러한 projected gain을 시각화합니다. 본 연구는 LLM 스케일에서 이러한 대규모의 데이터 효율성 향상이 가능함을 최초로 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 온라인 학습과 불확실성 기반 탐색(uncertainty-guided exploration)이 RLHF의 데이터 효율성을 비약적으로 향상시킬 수 있음을 성공적으로 시연했습니다. affirmative nudge 의 도입을 통해 온라인 RLHF 과정에서 흔히 관찰되는 성능 "tanking" 현상을 극복했으며, epistemic neural network 와 information-directed exploration 을 통해 informative한 피드백 수집의 기반을 마련했습니다. 이러한 혁신적인 접근 방식은 LLM의 alignment를 위한 데이터 수집 비용을 크게 절감하고, 모델의 학습 속도를 가속화할 수 있는 잠재력을 가집니다. 본 연구의 결과는 LLM 스케일에서 1,000배 의 데이터 효율성 향상을 달성할 가능성을 제시하며, 이는 인공 초지능(artificial superintelligence)으로 가는 길에 안전하고 효율적인 학습 시스템을 구축하는 데 중요한 시사점을 제공합니다. 또한, 이 연구는 exploration 알고리즘 개선, 프롬프트 선택, 멀티턴 대화, AI 에이전트 및 AI assisted feedback 등 다양한 LLM 활용 사례로 확장될 수 있는 유망한 연구 방향을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The State-Prediction Separation Hypothesis
- [논문리뷰] In-Context Reinforcement Learning for Tool Use in Large Language Models
- [논문리뷰] Diffusion Language Models are Super Data Learners
- [논문리뷰] Every Activation Boosted: Scaling General Reasoner to 1 Trillion Open Language Foundation
- [논문리뷰] LimRank: Less is More for Reasoning-Intensive Information Reranking
Review 의 다른글
- 이전글 [논문리뷰] ESPIRE: A Diagnostic Benchmark for Embodied Spatial Reasoning of Vision-Language Models
- 현재글 : [논문리뷰] Efficient Exploration at Scale
- 다음글 [논문리뷰] Efficient Training-Free Multi-Token Prediction via Embedding-Space Probing
댓글