[논문리뷰] Efficient Training-Free Multi-Token Prediction via Embedding-Space Probing
링크: 논문 PDF로 바로 열기
저자: Raghavv Goel, Mukul Gagrani, Mingu Lee, Chris Lott
키워: Multi-token prediction (MTP), Training-free, Embedding-Space Probing, Speculative decoding, Block efficiency (BE), Dynamic tree expansion, LLMs
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multi-token prediction (MTP) : 단일 모델 호출에서 여러 개의 미래 토큰을 병렬로 예측하는 기법으로, LLM(Large Language Model) Inference의 Throughput을 향상시키기 위한 접근 방식입니다.
- Training-free : 기존 모델의 Weight를 수정하거나 추가적인 Auxiliary head, Draft model 없이 Inference를 수행하는 방식을 의미합니다.
- Embedding-Space Probing : 모델의 Embedding Space에서 Mask token을 직접 합성하여 프롬프트에 주입함으로써, 모델로부터 Multi-token Distribution을 이끌어내는 방법론입니다.
- Block Complexity (BC) : 단일 Forward pass에서 모델이 병렬로 처리하는 총 Input token의 수를 나타내는 지표입니다.
- Block Efficiency (BE) / Average Acceptance Length (τ) : 모델 호출당 평균적으로 수락되는 토큰의 수와 보너스 토큰을 합산한 값으로, 모델 호출 감소 및 Throughput 향상을 직접적으로 반영하는 성능 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
LLM은 Next-token Generation을 위해 훈련되므로, GPU Parallelism을 충분히 활용하지 못하는 문제가 있습니다. 기존의 MTP 접근 방식(예: MEDUSA , PaSS )은 종종 Auxiliary head를 추가하거나, Base model의 Weight를 수정하거나, External Draft model에 의존합니다. 이러한 방법론은 상당한 Engineering effort, Dataset Construction, Architecture tuning, GPU Compute 비용, 그리고 추가적인 Parameter 및 Memory overhead를 발생시키며, 특히 Edge device나 Compute-constrained 환경에는 부적합하다는 한계가 있습니다. 본 연구는 이러한 Training 및 Model Modification 없이 효율적이고 Lossless한 MTP를 달성하는 것을 목표로 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Training-free , Single-model , Probing-based MTP 접근 방식을 제안합니다. 이 방법은 모델의 Embedding Space에서 On-the-fly generated mask tokens 를 합성하여 프롬프트에 주입하고, 이를 통해 여러 미래 토큰에 대한 예측을 병렬로 유도합니다. 이러한 병렬 예측은 Base model에 의해 Jointly verified 되어 Lossless Generation을 보장합니다.
방법론의 핵심은 다음과 같습니다.
- Mask Token Injection : Prompt Embedding Mean 기반의 Soft Initialization과 Last Token Generation 기반의 Dynamic update (Equation 4)를 통해 Mask token Embedding을 생성합니다. 이는 모델이 Prompt Context와 통계적으로 유사한 Embedding을 사용하여 Latent generative pathway를 탐색하도록 돕습니다.
- Dynamic Token-Tree Expansion : 누적 확률에 따라 Token path를 적응적으로 확장하고, Lightweight pruning rule을 적용하여 중복되거나 낮은 확률의 Path를 제거합니다. 이는 효율성을 높이고 Parallel generation의 다양성을 유지합니다. 아래 Figure 1은 Mask token probing과 Verification 과정을 보여줍니다.
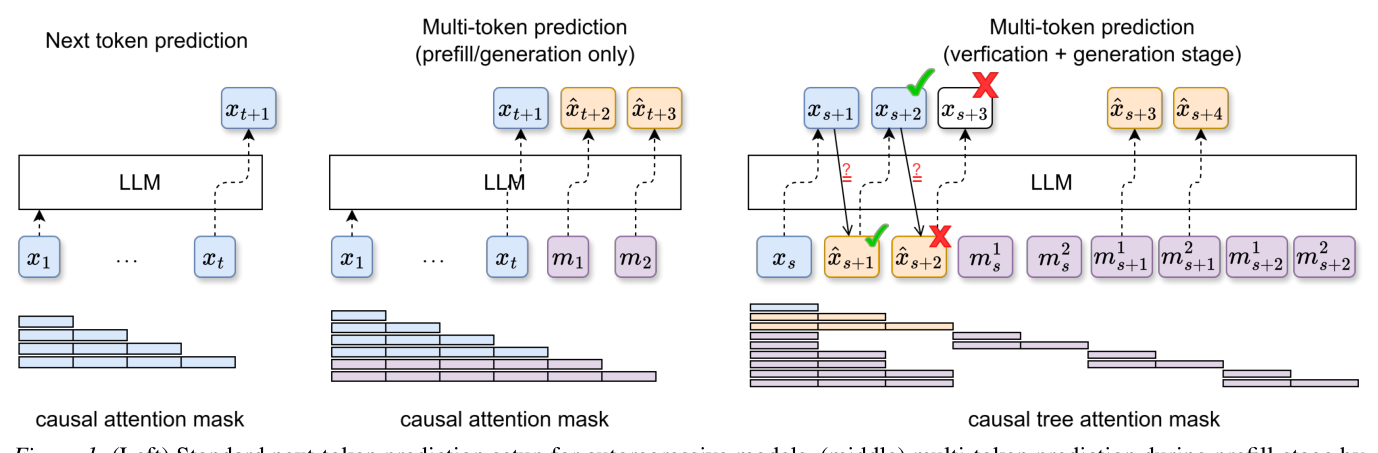 Figure 1: (Left) Standard next-token prediction setup for autoregressive models, (middle) multi-token prediction during prefill-stage by probing mask tokens which are appended to prompt tokens, (right) multi-token prediction with parallel verification and generation. Mask tokens are associated with last generated token (xs) and future tokens (xˆs+1, xˆs+2) through custom tree attention mask.
Figure 1: (Left) Standard next-token prediction setup for autoregressive models, (middle) multi-token prediction during prefill-stage by probing mask tokens which are appended to prompt tokens, (right) multi-token prediction with parallel verification and generation. Mask tokens are associated with last generated token (xs) and future tokens (xˆs+1, xˆs+2) through custom tree attention mask.
- Theoretical Justification : Lemma 3.1 (Appendix A에 증명)은 Mask token의 Hidden state와 True token의 Hidden state 간의 Cosine Similarity가 높을수록, Top-K 예측에 올바른 토큰이 포함될 확률이 높아짐을 이론적으로 뒷받침합니다. [Figure 2] 는 실제로 Accepted token의 Cosine Similarity가 Rejected token보다 후반 Layer에서 더 높게 나타남을 보여줍니다.
- Efficient Static-Tree Implementation : GPU-friendly한 Attention mask 및 Position ID update 구현을 통해 Throughput을 크게 개선했습니다.
실험 결과, 제안된 방법은 기존의 Training-free Baseline(예: Lookahead Decoding , Prompt Lookup Decoding , STAND )을 일관적으로 능가합니다.
- Average Acceptance Length (τ) 는 LLaMA3 모델에서 ~12% , Qwen3 모델에서 8-12% 향상되었습니다.
- Token Throughput (T/S) 은 최대 15-19% 증가했습니다.
- Block Complexity (BC) 30 및 60 에서 모델 Forward call 수가 최대 40% 감소했습니다. [Table 6]
- Efficiency 개선을 통해 LLaMA3.1-8B-Instruct 에서 15% , LLaMA3.2-3B-Instruct 에서 14% 의 Token-rate 증가를 달성했습니다. [Table 3]
 Table 1: Comparison of multi-token prediction average acceptance length (τ) and tokens per second (T/S) across models and methods averaged on Spec-bench tasks for block complexity BC = 30 and BC = 60
Table 1: Comparison of multi-token prediction average acceptance length (τ) and tokens per second (T/S) across models and methods averaged on Spec-bench tasks for block complexity BC = 30 and BC = 60
위 Table 1에 따르면, LLaMA3.2-3B-Instruct에서 BC=60일 때 τ는 1.67, T/S는 45.1을 기록하며 Baseline 대비 가장 우수한 성능을 보였습니다.
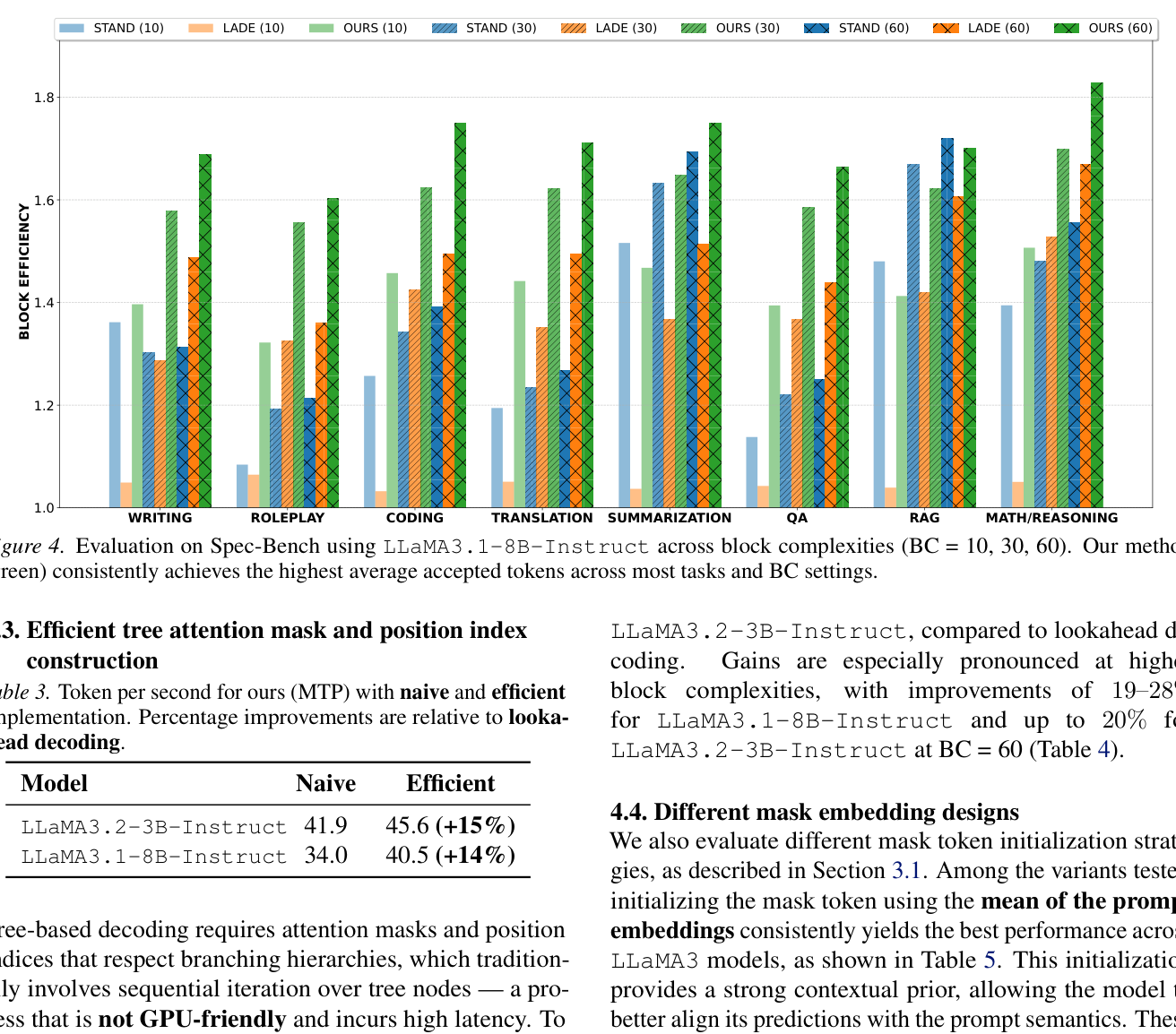 Figure 4: Evaluation on Spec-Bench using LLaMA3.1-8B-Instruct across block complexities (BC = 10, 30, 60). Our method (green) consistently achieves the highest average accepted tokens across most tasks and BC settings.
Figure 4: Evaluation on Spec-Bench using LLaMA3.1-8B-Instruct across block complexities (BC = 10, 30, 60). Our method (green) consistently achieves the highest average accepted tokens across most tasks and BC settings.
위 Figure 4와 [Figure 5]는 LLaMA3.1-8B-Instruct와 Qwen3-32B 모델에서 다양한 Task 및 BC 설정에 걸쳐 제안 방법이 가장 높은 Block Efficiency를 달성했음을 보여줍니다.
- Prompt Embedding Mean based Soft Initialization 이 Mask token 초기화 전략 중 가장 좋은 성능을 보였으며 [Table 5] , Tree pruner는 Average token acceptance를 최대 4% 까지 향상시켰습니다 [Table 11] .
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Dynamically generated mask token을 이용한 Probing을 통해 Frozen LLM의 Latent Multi-token prediction 능력을 활용하는 Training-free MTP 프레임워크를 성공적으로 제시했습니다. 이 방법은 어떠한 모델 Weight 수정이나 Auxiliary model 없이도 일관된 Acceptance rate 및 Throughput 향상을 제공하며 Lossless Generation을 보장합니다.
이 연구는 LLM Inference의 Substantial speedup 를 가능하게 하여, 특히 Compute-constrained environments (Mobile device, Embedded system, Edge deployment)에서 LLM의 활용성을 크게 높일 수 있습니다. 또한, Decoder representation 내에 잠재된 Multi-step predictive structure에 대한 통찰력을 제공하여 LLM의 Interpretability 및 미래 모델 설계에 기여할 것으로 기대됩니다. 궁극적으로, 배포 비용을 절감하고 더 빠르고 확장 가능한 Generation을 가능하게 함으로써 고품질 LLM Inference에 대한 접근성을 넓히는 데 중요한 역할을 할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Efficient Exploration at Scale
- 현재글 : [논문리뷰] Efficient Training-Free Multi-Token Prediction via Embedding-Space Probing
- 다음글 [논문리뷰] GigaWorld-Policy: An Efficient Action-Centered World--Action Model
댓글