[논문리뷰] GigaWorld-Policy: An Efficient Action-Centered World--Action Model
링크: 논문 PDF로 바로 열기
저자: Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, et al.
키워: World Model, Action-Centered, Robotic Manipulation, Low-Latency Control, Diffusion Transformer, Policy Learning, Vision-Language-Action (VLA)
1. Key Terms & Definitions (핵심 용어 및 정의)
- Vision-Language-Action (VLA) Models : 시각, 언어, 행동 정보를 통합하여 로봇 제어를 수행하는 모델입니다. 주로 높은 차원의 관찰 및 작업 컨디셔닝을 처리하지만, 행동 슈퍼비전의 희소성(sparsity)과 낮은 다양성(low-diversity) 문제가 있습니다.
- World Model (WM) : 환경의 역학(dynamics)을 학습하여 미래 상태를 예측하는 모델입니다. 비디오 생성(video generation)과 유사한 방식으로 미래 시각적 관찰을 예측하고, 이를 로봇 정책 학습(robot policy learning)에 활용하여 슈퍼비전 밀도(supervision density)를 높입니다.
- Action-Centered World-Action Model (WAM) : 행동 예측과 미래 시각 역학 모델링을 통합하여, 행동을 중심으로 세계 모델링을 수행하는 접근 방식입니다. 추론 시 비디오 생성에 대한 과도한 의존을 줄여 Latency를 개선합니다.
- Causal Sequence Model : 인과적 마스크(causal mask)를 사용하여 토큰 간의 정보 흐름을 제어하는 시퀀스 모델입니다. GigaWorld-Policy에서는 행동 토큰(action tokens)과 미래 시각 토큰(future-visual tokens) 간의 인과 관계를 명시하여 정보 누출을 방지합니다.
- Inference Latency : 모델이 단일 추론(inference)을 완료하는 데 걸리는 시간입니다. 로봇 제어 시스템에서는 실시간 반응성(real-time responsiveness)을 위해 낮은 Latency가 중요합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 Vision-Language-Action (VLA) 모델 은 강력한 성능을 보였지만, 슈퍼비전 희소성(sparsity) 이라는 주요 문제에 직면해 있습니다. 즉, 높은 차원의 관찰 정보와 의미론적으로 풍부한 작업 컨디셔닝에도 불구하고, 행동에 대한 슈퍼비전은 매우 희소하고 다양성이 부족하여 모델이 물리적으로 일관된 행동 분포를 학습하기보다는 문맥적 지름길(contextual shortcuts)에 의존하게 됩니다. 일부 연구는 미래 상태 슈퍼비전(future-state supervision)을 주입하여 이 문제를 해결하려 했으나, VLM 기반 VLA 모델 은 주로 식별적 추론(discriminative reasoning)에 최적화되어 있어 높은 충실도의(high-fidelity) 비디오 생성에는 적합하지 않았습니다.
반면, World Model 을 로봇 정책 학습에 통합하려는 최근 노력은 슈퍼비전 밀도를 높이고 확장성(scalability)을 향상시키는 데 효과적이지만, 추론(inference) 시 미래 비디오 생성을 위해 반복적인 샘플링(iterative sampling)이 필요하여 높은 Latency 를 유발합니다. 또한, 비디오 예측의 오류가 행동 디코딩(action decoding)으로 전파되어 장기적인 제어 성능을 저하시킬 수 있습니다. 이러한 한계점을 극복하기 위해, low-latency 로 효율적인 로봇 제어를 가능하게 하는 새로운 World-Action 모델 의 필요성이 대두되었습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 action-centered 및 efficient World-Action 모델 인 GigaWorld-Policy 를 제안합니다. 이 방법론은 5B-parameter diffusion Transformer 를 기반으로 하며,
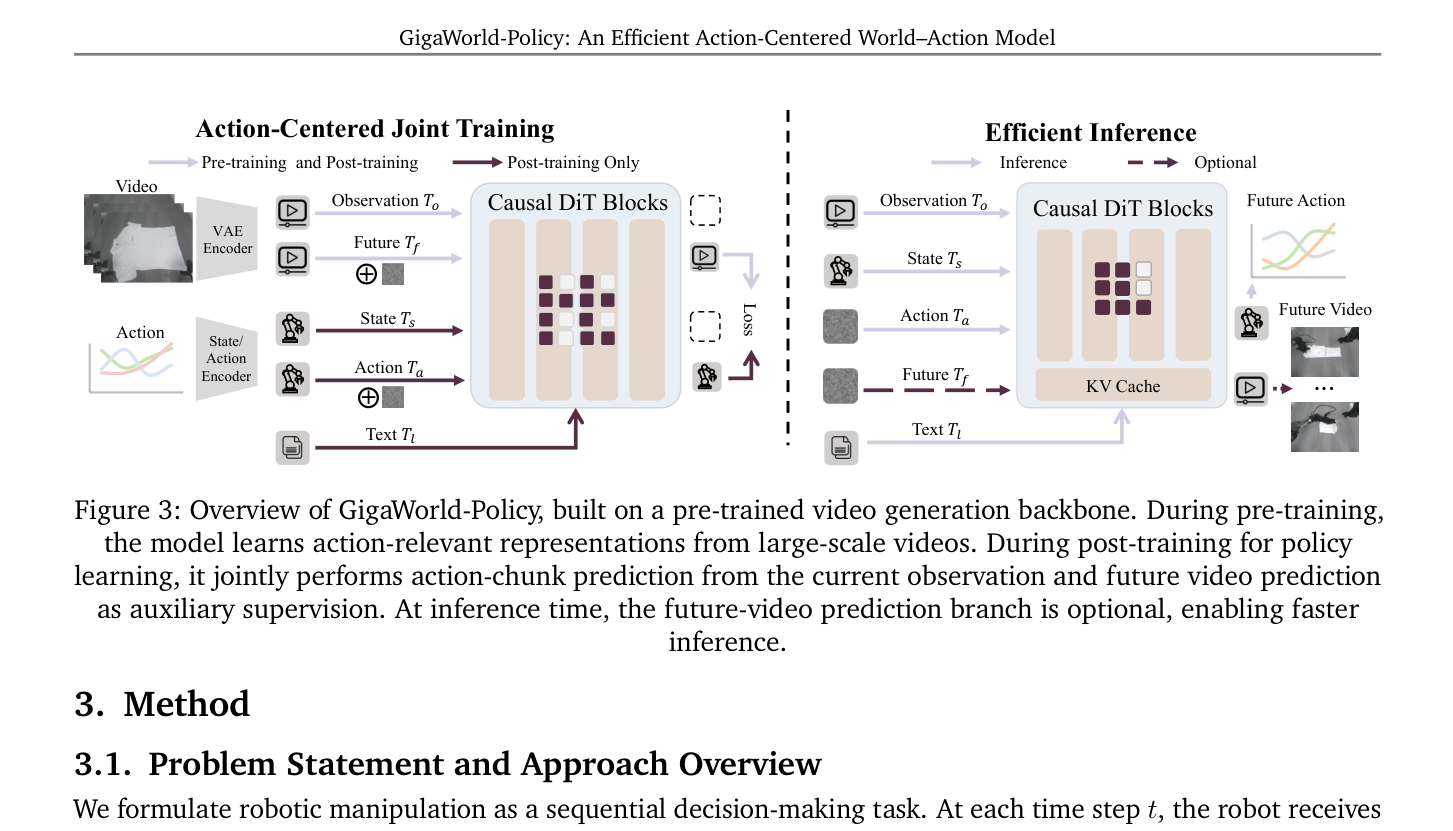 Figure 3: Overview of GigaWorld-Policy, built on a pre-trained video generation backbone. During pre-training, the model learns action-relevant representations from large-scale videos. During post-training for policy learning, it jointly performs action-chunk prediction from the current observation and future video prediction as auxiliary supervision. At inference time, the future-video prediction branch is optional, enabling faster inference.
Figure 3: Overview of GigaWorld-Policy, built on a pre-trained video generation backbone. During pre-training, the model learns action-relevant representations from large-scale videos. During post-training for policy learning, it jointly performs action-chunk prediction from the current observation and future video prediction as auxiliary supervision. At inference time, the future-video prediction branch is optional, enabling faster inference.
에 제시된 바와 같이, 현재 관찰(observation)과 로봇 상태(robot state), 언어 지시(language instruction)로부터 행동 청크(action chunk)를 예측하고, 동시에 예측된 행동에 조건화된 미래 시각 역학(visual dynamics)을 학습하는 단일 통합 모델 gθ로 구현됩니다. 이 모델은 action tokens 과 future-visual tokens 를 causal mask 하에 causal sequence model 로 표현합니다.
GigaWorld-Policy 는 비디오 생성 백본(video generation backbone)으로 사전 학습된 후, 로봇 중심 데이터와 인간의 egocentric video 를 포함하는 embodied data 로 추가 사전 학습됩니다. 마지막으로, 타겟 로봇의 제어 인터페이스 및 상태 분포에 특화된 instruction-conditioned action prediction 을 위해 post-training 됩니다. 훈련 목표는 flow matching 을 사용하여 행동 예측과 미래 시각 역학 모델링을 최적화하며, 추론 시에는 [Figure 4]의 causal self-attention mask 를 통해 미래 비디오 예측을 선택 사항(optional) 으로 만들어 low-latency action generation 을 가능하게 합니다.
핵심 결과는 다음과 같습니다.
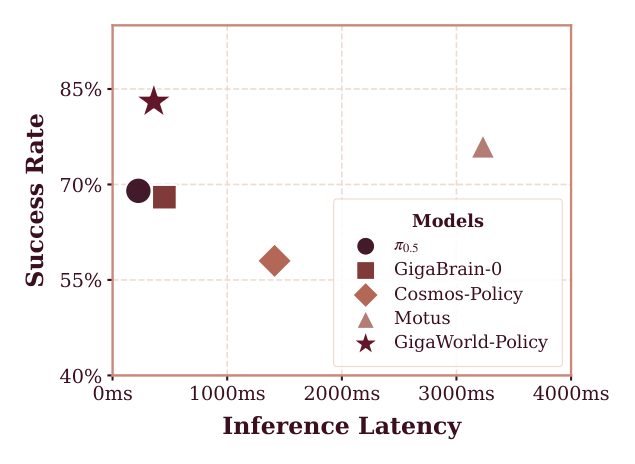 Figure 1: Comparison of GigaWorld-Policy with baselines on inference frequency and task success rate in real-world settings and on an A100 GPU.
Figure 1: Comparison of GigaWorld-Policy with baselines on inference frequency and task success rate in real-world settings and on an A100 GPU.
및
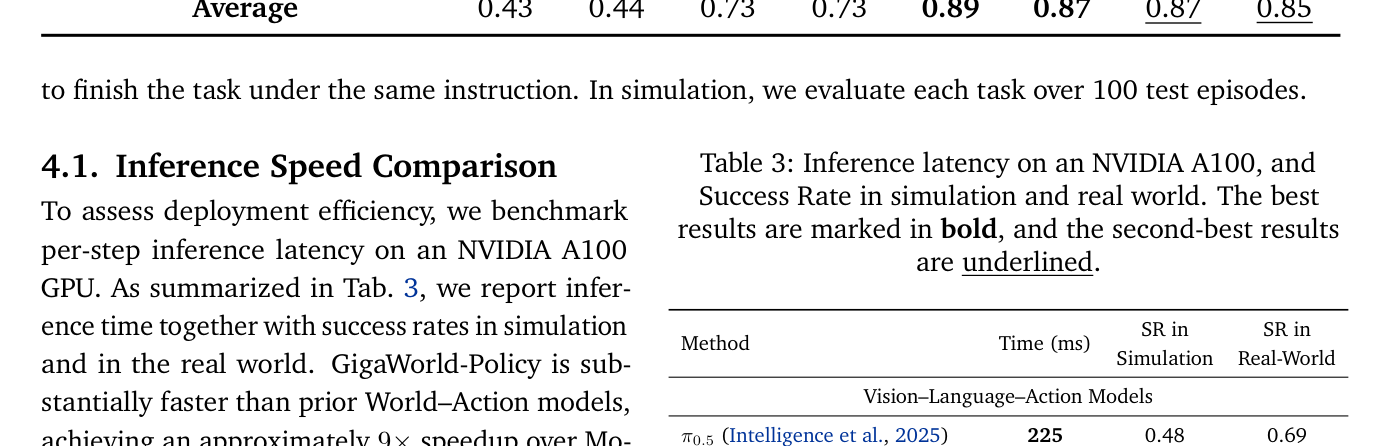 Table 3: Inference latency on an NVIDIA A100, and Success Rate in simulation and real world. The best results are marked in bold, and the second-best results are underlined.
Table 3: Inference latency on an NVIDIA A100, and Success Rate in simulation and real world. The best results are marked in bold, and the second-best results are underlined.
에서 볼 수 있듯이, GigaWorld-Policy 는 기존 World-Action 모델 인 Motus 대비 추론 속도에서 9배 빠른 360ms 를 달성하면서도, real-world 작업 성공률(Success Rate)에서 7% 높은 0.83 을 기록했습니다. simulation SR 에서는 Motus 와 유사한 0.86 의 성능을 유지했습니다. 또한, VLM-based VLA 모델인 π0.5 와 비교했을 때, GigaWorld-Policy 는 약간의 Latency 증가(360ms vs. 225ms)에도 불구하고 simulation SR 과 real-world SR 모두에서 현저히 우수한 성능을 보였습니다. 특히, [Table 4]의 real-world 실험에서는 GigaWorld-Policy 가 평균 0.83 SR 로 Motus 의 0.76 SR 을 능가했으며, π0.5 의 0.69 SR 대비 약 14% 더 높은 성공률을 달성했습니다. Data efficiency 측면에서도, [Figure 7]에서 GigaWorld-Policy 는 VLA 모델의 최대 SR 을 달성하는 데 필요한 훈련 데이터의 10% 만으로도 유사한 성능을 보였습니다. Ablation study 에서는 미래 프레임 예측을 통해 0.18 의 absolute gain 을 얻었으며, 사전 학습(pre-training)의 각 단계가 성능 향상에 상호 보완적으로 기여함을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
이 연구는 action-centered 및 효율적인 World-Action 모델 인 GigaWorld-Policy 를 성공적으로 도입했습니다. 이 모델은 정책 학습을 미래 행동 시퀀스 예측과 행동 조건화 비디오 생성으로 분해하여, 더 풍부한 슈퍼비전으로 2D pixel-action dynamics 를 학습하고, 더 정확하고 그럴듯한 행동 계획을 생성합니다. real-world robotic platform 에서의 실험 결과는 GigaWorld-Policy 가 추론 오버헤드(inference overhead)를 크게 줄이면서도 작업 성능을 향상시킨다는 것을 명확히 보여주었습니다. 구체적으로, 9배의 추론 속도 향상 (inference당 0.36초 )과 기존 베이스라인 대비 최대 7%의 작업 성공률 증가 를 달성했습니다.
이 연구는 로봇 학습 분야에 큰 시사점을 제공합니다. low-latency control 이 중요한 실제 로봇 애플리케이션에서 world model 기반의 정교한 동적 이해를 활용하면서도 실용적인 배포를 가능하게 하는 효과적인 방법을 제시했습니다. causal masking scheme 을 통해 비디오 예측을 선택 사항으로 만든 디자인은 inference efficiency 와 control performance 사이의 균형점을 성공적으로 찾았으며, 이는 향후 로봇 시스템의 지능과 자율성을 향상시키는 데 중요한 역할을 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Efficient Training-Free Multi-Token Prediction via Embedding-Space Probing
- 현재글 : [논문리뷰] GigaWorld-Policy: An Efficient Action-Centered World--Action Model
- 다음글 [논문리뷰] LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition
댓글