[논문리뷰] LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition
링크: 논문 PDF로 바로 열기
저자: Vlad-Constantin Lungu-Stan, Ionuţ Mironică, Mariana-Iuliana Georgescu
키워: Latent Diffusion, RGBA Layer Generation, Text-to-Layers, Image Decomposition, Prompt Expansion, 4D ROPE
1. Key Terms & Definitions (핵심 용어 및 정의)
- LaDe (Layered Media Design) : 저자들이 제안하는 Latent Diffusion Framework로, 텍스트 프롬프트로부터 flexible 한 수의 semantically meaningful layers 를 포함하는 그래픽 미디어를 생성하고, 기존 이미지를 레이어로 분해하는 unified 모델입니다.
- RGBA VAE : Alpha channel을 지원하는 Variational Autoencoder로, 투명도 정보를 포함하는 RGBA 이미지를 디코딩하여 레이어의 alpha-blending 을 가능하게 합니다.
- 4D ROPE (Rotary Positional Embedding) : Latent Diffusion Transformer 에 적용된 positional encoding 메커니즘으로, 공간 좌표( H, W ), 레이어 인덱스( F ), 토큰 역할( R )의 4개 차원을 인코딩하여 프롬프트의 각 부분과 해당 레이어 간의 정밀한 연결을 제공합니다.
- Prompt Expansion (PE) : LLM 기반 전략으로, 짧은 사용자 의도를 구조화된 per-layer descriptions 로 변환하여 LaDe 의 미디어 디자인 생성 과정을 안내합니다.
- VLM-as-a-judge : 생성된 미디어 디자인 및 레이어 분해의 질적 측면을 평가하기 위해 Vision-Language Models (VLM) (예: GPT-40 mini , Qwen3-VL )을 활용하는 평가 패러다임입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 generative models , 특히 Diffusion Models (DM) 은 고품질 이미지를 생성하는 데 탁월하지만, 결과물을 단일 flat image artifact 로 생성하여 전문 디자인 워크플로우에서 요구되는 개별 요소에 대한 fine-grained control 을 제공하지 못하는 한계가 있습니다. 포스터, 광고, 앱 화면과 같은 미디어 디자인은 본질적으로 여러 semantically distinct elements 로 구성된 layered 구조를 가지며, 각 요소는 독립적으로 편집 가능해야 합니다. 기존 layered media design generation 방법론들은 이러한 문제를 해결하려 했으나, OmniPSD [14]는 생성 가능한 레이어 수를 3개로 고정하는 제약이 있었고, ART [18]는 레이어 수의 유연성을 제공하지만 각 레이어가 spatially continuous regions 만 포함해야 한다는 제약으로 인해 디자인 복잡도가 증가하면 레이어 수가 선형적으로 늘어나 편집 효율성과 시각적 계층 구조가 저해되는 문제가 있었습니다. 또한, 기존 방법론들은 Text-to-Layers (T2L) , Text-to-Image (T2I) , Image-to-Layers (I2L) 작업 중 일부만 지원하여 unified 된 접근 방식이 부족했습니다. 저자들은 이러한 기존 방법론의 한계점을 해결하고, 가변적인 레이어 수와 semantically meaningful 하며 편집 가능한 레이어를 생성할 수 있는 unified framework 의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 unified multi-layered graphic media generation and decomposition 을 위한 LaDe ( Layered Media Design ) 프레임워크를 제안합니다. LaDe 는 LLM-based prompt expander , 4D ROPE positional encoding 메커니즘을 갖춘 Latent Diffusion Transformer , 그리고 full alpha-channel support 를 제공하는 RGBA VAE 의 세 가지 핵심 구성 요소로 이루어져 있습니다. prompt expander 는 짧은 사용자 의도를 구조화된 per-layer descriptions 로 변환하여 생성 과정을 안내하며, Latent Diffusion Transformer 는 이 상세 프롬프트와 노이즈를 입력받아 전체 미디어 디자인과 그 구성 요소인 RGBA layers 를 공동으로 생성합니다. 특히 4D ROPE 는 공간 좌표, 레이어 인덱스, 토큰 역할을 인코딩하여 텍스트 프롬프트와 해당 레이어 간의 정밀한 정렬을 가능하게 합니다. 또한, LaDe 는 bucketing and packing 작업을 통해 가변적인 aspect ratio 와 레이어 수를 효율적으로 처리하며 GPU 메모리 사용을 최적화했습니다. LaDe 는 훈련 중 레이어 샘플을 조건으로 사용하여 Text-to-Image generation , Text-to-Layers media design generation , 그리고 Image-to-Layers decomposition 의 세 가지 작업을 unified 된 방식으로 지원합니다
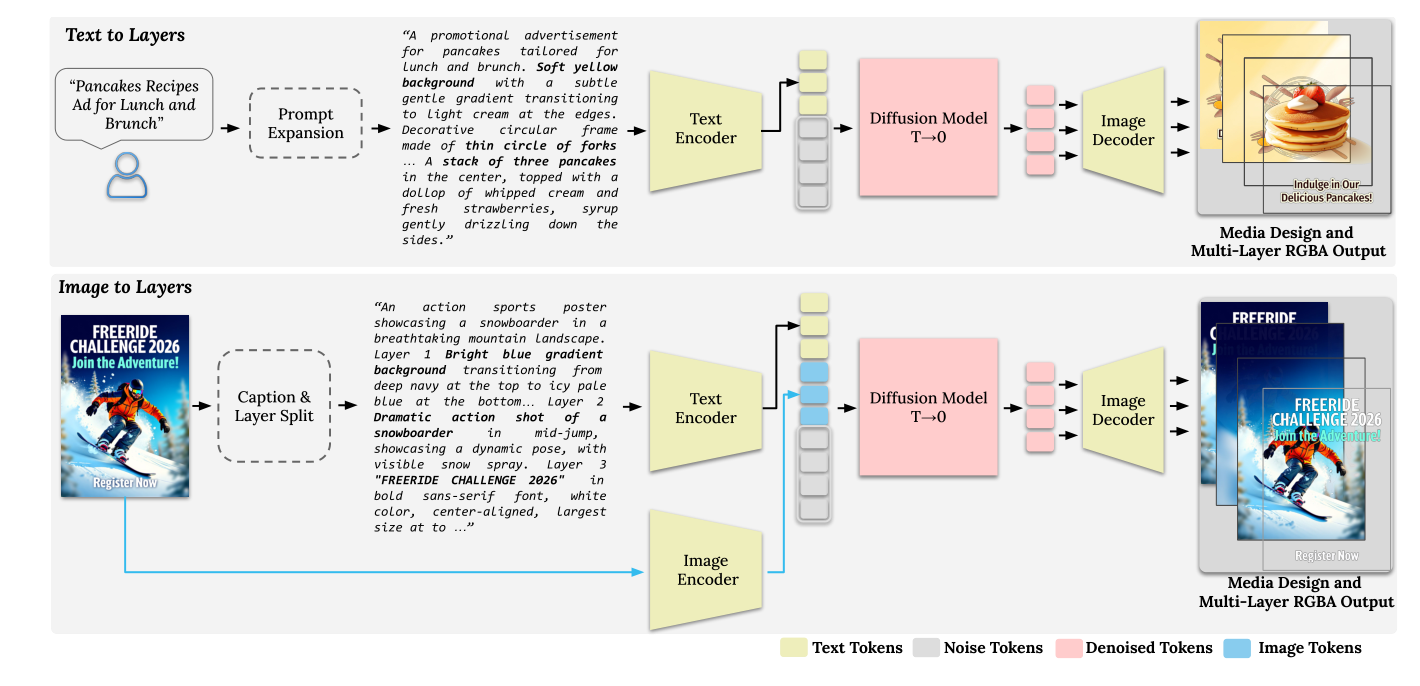 Figure 5: Text-to-Layers generation pipeline (top) and Image-to-Layers decomposition (bottom)
Figure 5: Text-to-Layers generation pipeline (top) and Image-to-Layers decomposition (bottom)
.
Crello test set [25]에 대한 실험 결과, LaDe 는 Text-to-Layers generation 작업에서 기존 Qwen-Image-T2I+Qwen-Image-Layered-I2L [28] 모델을 크게 능가하는 성능을 보였습니다. 두 가지 VLM-as-a-judge 평가자( GPT-40 mini 및 Qwen3-VL )를 사용하여 평가한 결과, LaDe 는 모든 레이어 수(2, 3, 4, 5 layers)에서 Qwen-Image-T2I+Qwen-Image-Layered-I2L 보다 높은 점수를 달성했습니다
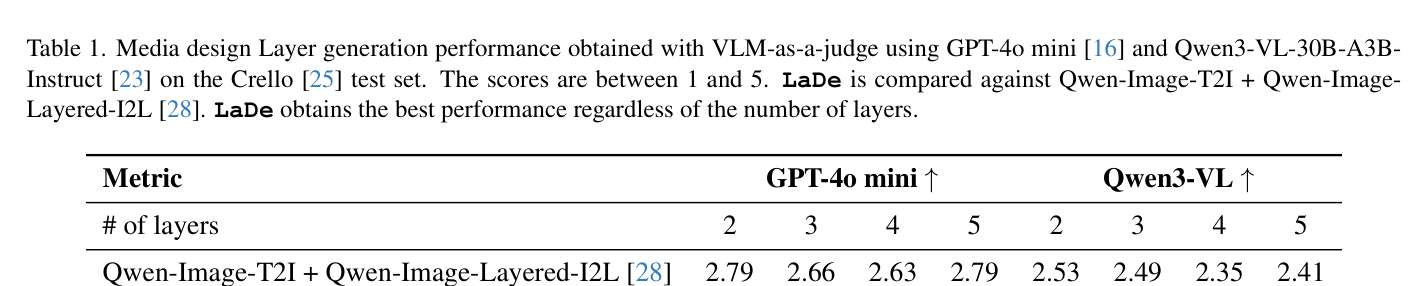 Table 1: Media design Layer generation performance obtained with VLM-as-a-judge
Table 1: Media design Layer generation performance obtained with VLM-as-a-judge
. 예를 들어, 5개 레이어 생성 시 LaDe 는 GPT-40 mini 평가에서 3.92 점을, Qwen-Image-T2I+Qwen-Image-Layered-I2L 는 2.79 점을 기록하여 text-to-layer alignment 가 크게 향상되었음을 입증했습니다. Image-to-Layers decomposition 작업에서는 LaDe 가 2개 레이어 분해 시 32.65 의 PSNR 점수를 달성하여 Qwen-Image-Layered-I2L [28]보다 우수한 decomposition 정확도를 보여주었으며, RGB L1 지표에서도 2~3개 레이어 분해 시 더 나은 성능을 보였습니다
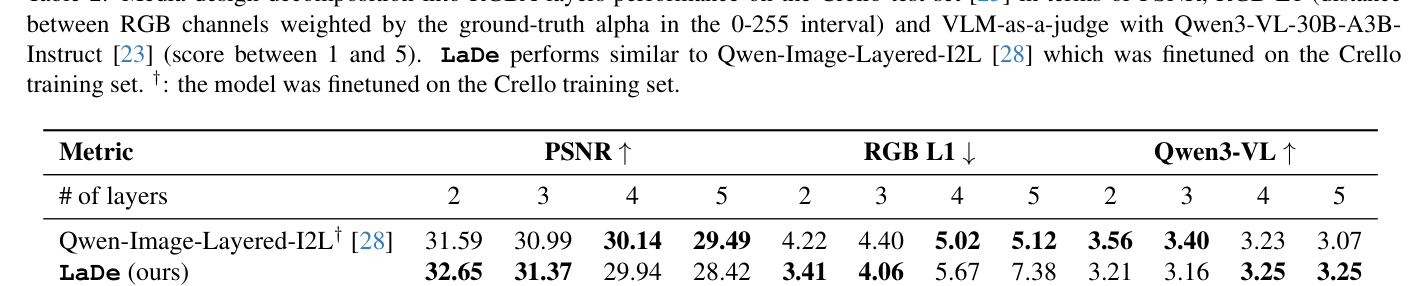 Table 2: Media design decomposition into RGBA layers performance
Table 2: Media design decomposition into RGBA layers performance
. Ablation study 를 통해 훈련 시 가변 레이어 수를 사용함으로써 성능이 향상되며(예: Qwen3-VL 평가에서 3.78에서 3.85 로 상승), Eq. 2 에 제시된 RoPE 를 통해 레이어-프롬프트 일관성이 개선됨을 확인했습니다 [Table 3], [Figure 10].
4. Conclusion & Impact (결론 및 시사점)
LaDe 는 multi-layered media design 생성 및 분해를 위한 unified latent diffusion framework 로, LLM-based prompt expansion , 4D ROPE positional encoding 을 활용하는 Latent Diffusion Transformer , 그리고 RGBA VAE 를 통합하여 가변적인 수의 semantically meaningful layers 를 생성합니다. 이 연구는 text-to-layers generation 에서 state-of-the-art 성능을 달성하고, image-to-layers decomposition 에서도 경쟁력 있는 결과를 보여주었습니다. LaDe 는 디자이너들이 자연어 프롬프트만으로 완전 편집 가능한 다계층 디자인 문서를 생성하고 기존 이미지를 의미 있는 레이어로 분해할 수 있게 함으로써, 기존 생성 모델의 한계를 극복하고 미디어 디자인 워크플로우의 효율성과 창의적 유연성을 혁신할 잠재력을 가집니다. 이는 Generative AI 가 학계 및 산업계에서 더욱 실용적인 디자인 도구로 발전하는 데 중요한 기여를 할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] GigaWorld-Policy: An Efficient Action-Centered World--Action Model
- 현재글 : [논문리뷰] LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition
- 다음글 [논문리뷰] LoST: Level of Semantics Tokenization for 3D Shapes
댓글