[논문리뷰] TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas
링크: 논문 PDF로 바로 열기
저자: Ai Jian, Xiaoyun Zhang, et al.
1. Key Terms & Definitions
- Full Schema Assumption : 기존 Text-to-SQL 연구에서 데이터베이스의 전체 스키마가 모델 입력 컨텍스트에 미리 로드되어 있다고 가정하는 premise입니다.
- Unknown Schema Setting : 실제 엔터프라이즈 환경에서 수백 개의 테이블과 방대한 noisy metadata를 포함하는 데이터베이스에 대해 에이전트가 관련 스키마 서브셋을 능동적으로 식별하고 검증해야 하는 새로운 Text-to-SQL 시나리오입니다.
- TRUST-SQL : 본 논문에서 제안하는 프레임워크 (Truthful Reasoning with Unknown Schema via Tools)로, Unknown Schema Setting 을 해결하기 위해 multi-turn tool-integrated 의사결정 프로세스를 채택합니다.
- Partially Observable Markov Decision Process (POMDP) : Unknown Schema Setting 하의 Text-to-SQL 태스크를 공식화한 것으로, 에이전트가 불완전한 환경 관측을 통해 의사결정을 수행합니다.
- Four-phase Interaction Protocol : TRUST-SQL의 핵심 요소로, Explore, Propose, Generate, Confirm의 네 가지 단계로 구성된 structured protocol입니다. 검증된 metadata에 기반한 추론을 강화하고 hallucination을 방지합니다.
- Dual-Track GRPO : TRUST-SQL의 새로운 훈련 전략으로, Group Relative Policy Optimization(GRPO)을 기반으로 합니다. Token-level masked advantages를 적용하여 schema exploration reward와 execution outcome reward를 분리하여 schema grounding과 SQL generation을 동시에 최적화합니다.
2. Motivation & Problem Statement
기존 Text-to-SQL 파싱 방법론들은 Full Schema Assumption 하에서 Large Language Models (LLMs) 의 발전과 함께 remarkable progress를 이루었습니다. 그러나 이 가정은 수백 개의 테이블과 방대한 양의 noisy metadata를 포함하며 끊임없이 변화하는 실제 엔터프라이즈 데이터베이스 환경에서는 실패합니다. 이러한 massive하고 잠재적으로 outdated된 metadata를 upfront로 주입하는 것은 finite context window에 비효율적이며, irrelevant하거나 stale한 정보로 인해 모델의 집중을 방해하여 오히려 해로울 수 있습니다.
저자들은 이러한 문제를 해결하기 위해 에이전트가 passive한 metadata 소비를 넘어 능동적으로 데이터베이스를 탐색하고 필요한 metadata만을 식별 및 검증해야 하는 Unknown Schema Setting 을 제안합니다 [Figure 1]. 기존 single-turn methods는 interactive한 기능이 부족하며, 최근 등장한 multi-turn agentic frameworks는 긴 상호작용 궤적(trajectory) 전반에 걸쳐 coherent reasoning을 유지하는 데 어려움을 겪고, exploration에 대한 explicit한 grounding mechanism이 없어 parametric prior에 기반한 non-existent schema element를 fabricat하는 경향이 있습니다. 또한, 단일 terminal reward에 의존하거나 중간 신호를 naive하게 aggregate하여 schema exploration의 품질과 SQL generation을 conflate하여 특정 action에 대한 credit assignment가 불가능하다는 한계가 있습니다.
3. Method & Key Results
본 논문에서는 Unknown Schema Setting 하의 Text-to-SQL 태스크를 Partially Observable Markov Decision Process (POMDP) 로 공식화하고, TRUST-SQL 프레임워크를 제안합니다. TRUST-SQL은 Explore, Propose, Generate, Confirm으로 구성된 four-phase interaction protocol 을 사용하여 검증된 metadata에 기반한 추론을 수행합니다. 특히 Propose 단계는 mandatory cognitive checkpoint 역할을 하여 에이전트가 verified metadata에 commit하도록 강제함으로써 hallucination을 방지합니다.
훈련 전략으로는 Dual-Track GRPO 를 도입했습니다
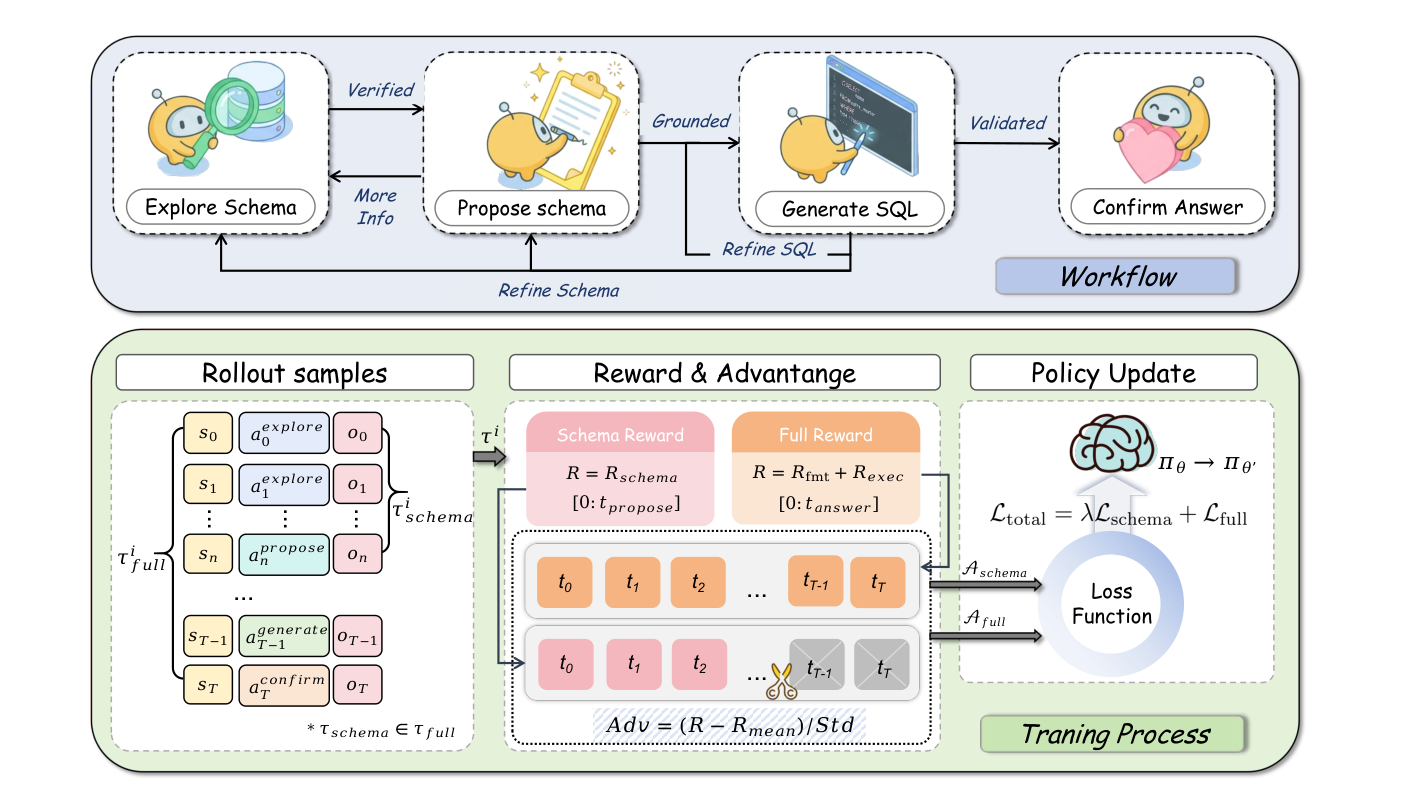 Figure 2: Overview of the TRUST-SQL framework. (Top) The four-phase workflow comprising Explore, Propose, Generate, and Confirm, with non-linear transitions enabling iterative schema refinement. (Bottom) The Dual-Track GRPO training pipeline, where trajectories are decomposed into a Schema Track Tschema and a Full Track Tfull, each optimized with independent rewards and masked advantages.
Figure 2: Overview of the TRUST-SQL framework. (Top) The four-phase workflow comprising Explore, Propose, Generate, and Confirm, with non-linear transitions enabling iterative schema refinement. (Bottom) The Dual-Track GRPO training pipeline, where trajectories are decomposed into a Schema Track Tschema and a Full Track Tfull, each optimized with independent rewards and masked advantages.
. 이 전략은 trajectory를 Schema Track과 Full Track으로 분해하고, 각각에 독립적인 reward와 token-level masked advantages를 적용하여 schema grounding과 SQL generation의 학습 신호를 분리합니다. Schema Reward (Rschema) 는 schema exploration 단계의 품질을 평가하며, Execution Reward (Rexec) 는 최종 SQL의 실행 정확도를 평가합니다. Rexec는 ground truth와 정확히 일치하면 1.0 , 실행 가능하지만 부정확하면 0.2 , 실행 불가하면 0.0 을 부여합니다. Token-level masking을 통해 schema advantage는 Explore 및 Propose 단계의 token에만, full advantage는 전체 단계의 token에만 적용되어 credit assignment 문제를 해결합니다.
주요 실험 결과는 다음과 같습니다:
- TRUST-SQL은 Unknown Schema Setting 에서 base model 대비 4B variant에서 평균 30.6% , 8B variant에서 평균 16.6% 의 absolute improvement를 달성했습니다.
- TRUST-SQL-4B 는 BIRD-Dev 벤치마크에서 greedy decoding으로 64.9% , majority voting으로 67.2% 의 execution accuracy를 기록하며 강력한 MTIR-SQL-4B baseline을 능가했습니다. 또한, Spider-DK 및 Spider-Realistic과 같은 robustness 벤치마크에서 consistently top position을 차지했습니다
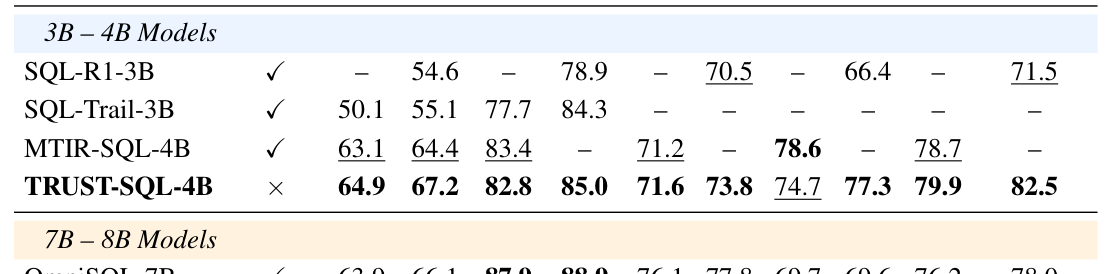 Table 1: Execution Accuracy (EX%) across multiple benchmarks. Gre denotes single-sample performance; Maj denotes majority voting. Bold indicates the best result and underline indicates the second best within each group.
Table 1: Execution Accuracy (EX%) across multiple benchmarks. Gre denotes single-sample performance; Maj denotes majority voting. Bold indicates the best result and underline indicates the second best within each group.
.
- 파일럿 스터디 결과, Propose 단계가 hallucination을 9.4배 감소시키는 데 결정적인 역할을 함을 보였습니다
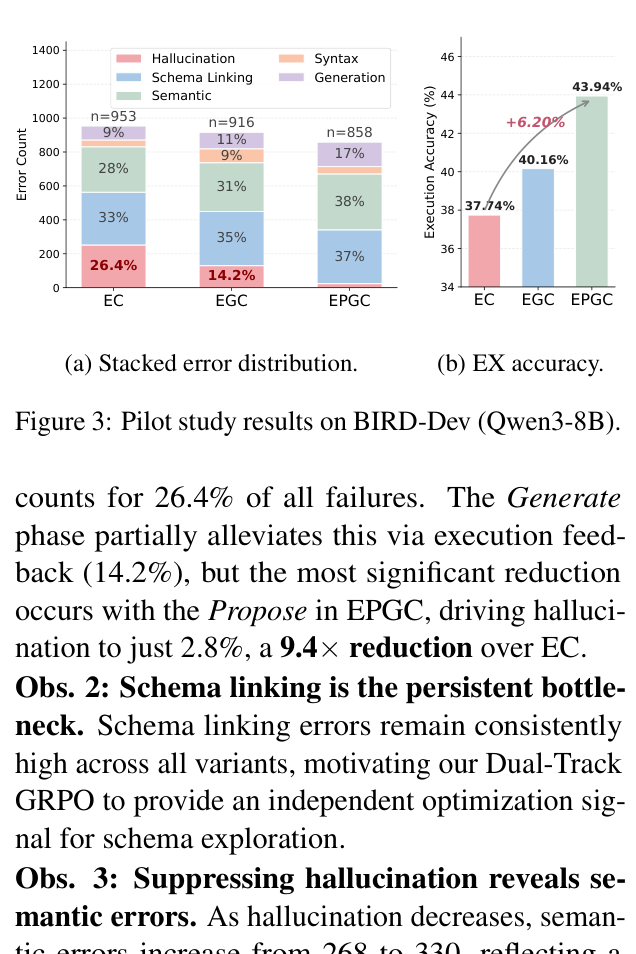 Figure 3: Pilot study results on BIRD-Dev (Qwen3-8B).
Figure 3: Pilot study results on BIRD-Dev (Qwen3-8B).
.
- Dual-Track GRPO 는 standard GRPO 대비 BIRD-Dev에서 execution accuracy에서 9.9% 의 relative improvement를 보였습니다 [Figure 4].
- Full schema prefilling이 TRUST-SQL의 성능에 미치는 영향 분석 결과, TRUST-SQL-4B 는 Spider-DK에서 2.4% , TRUST-SQL-8B 는 Spider-Realistic에서 1.6% 성능이 하락하는 등, schema prefilling이 오히려 robustness 벤치마크에서 성능 저하를 가져옴을 확인했습니다 [Table 2]. 이는 iterative policy가 이미 필요한 metadata를 높은 precision으로 retrieve하고 있음을 시사합니다 [Figure 7].
4. Conclusion & Impact
TRUST-SQL은 Unknown Schema Setting 하에서 Text-to-SQL 태스크에 대한 새로운 패러다임을 제시하며, autonomous database exploration이 방대하고 noisy하며 끊임없이 evolving하는 schemas를 가진 환경에서 feasible하고 effective함을 입증했습니다. 제안된 four-phase interaction protocol 은 에이전트의 추론을 actively verified metadata에 grounding하여 hallucination을 방지하며, Dual-Track GRPO 는 credit assignment bottleneck을 해결하여 schema grounding과 SQL generation을 효율적으로 최적화합니다.
이 연구는 기존 Full Schema Assumption 의 한계를 극복하고, LLM 기반 에이전트가 현실 세계의 복잡한 데이터베이스 환경에서 더욱 신뢰할 수 있고 증거 기반의 추론 프로세스를 수행할 수 있는 길을 열었다는 점에서 학계 및 산업계에 큰 시사점을 제공합니다. TRUST-SQL은 metadata의 passive한 소비 대신 능동적인 tool-integrated exploration을 통해 LLM 에이전트의 견고성과 일반화 능력을 향상시키는 데 기여합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Hallucination in World Models is Predictable and Preventable
- [논문리뷰] Native Active Perception as Reasoning for Omni-Modal Understanding
- [논문리뷰] SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
- [논문리뷰] AURA: Action-Gated Memory for Robot Policies at Constant VRAM
- [논문리뷰] OmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
Review 의 다른글
- 이전글 [논문리뷰] SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
- 현재글 : [논문리뷰] TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas
- 다음글 [논문리뷰] Thinking in Uncertainty: Mitigating Hallucinations in MLRMs with Latent Entropy-Aware Decoding
댓글