[논문리뷰] Online Self-Calibration Against Hallucination in Vision-Language Models
링크: 논문 PDF로 바로 열기
저자: Minghui Chen, Chenxu Yang, Hengjie Zhu, Dayan Wu, Zheng Lin, Qingyi Si
1. Key Terms & Definitions (핵심 용어 및 정의)
- Supervision-Perception Mismatch: 강력한 Teacher 모델의 데이터로 학습할 때, Student 모델의 인식 역량을 넘어서는 세부 사항까지 학습하게 되어 hallucination이 오히려 심화되는 현상.
- Generative-Discriminative Gap: LVLM이 오픈 엔디드 생성(Generation) 시에는 언어 관성으로 hallucination을 범하지만, 특정 객체 존재 여부 확인과 같은 판별(Discriminative) 작업에서는 훨씬 높은 정확도를 보이는 현상.
- OSCAR (Online Self-CAlibRation): MCTS와 Dual-Granularity Reward Mechanism을 사용하여 online으로 신뢰성 있는 선호도 데이터를 구축하고, 이를 통해 모델을 iteratively 업데이트하는 프레임워크.
- Dual-Granularity Reward Mechanism: 문장 단위의 hallucination 확인(Process Reward)과 전체 응답의 충실도 평가(Gated Outcome Reward)를 결합한 보상 체계.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 offline 선호도 정렬 방식이 LVLM의 hallucination 문제를 해결하는 데 오히려 역효과를 낼 수 있다는 Supervision-Perception Mismatch 문제를 제기한다. 기존 연구들은 GPT와 같은 더 강력한 Teacher 모델로부터 데이터를 distillation하여 Student를 학습시키지만, 이 과정에서 Student는 자신의 시각적 인식 한계를 넘어선 세부 묘사를 강요받아 '보는 것'이 아닌 '추측'하는 방식을 학습하게 된다 [Figure 1]. 이러한 offline 데이터셋으로 인한 성능 저하는 실제 pilot 실험을 통해서도 확인되었으며, 모델의 고유한 인식 경계 내에서 학습할 수 있는 새로운 online 학습 패러다임의 필요성이 대두되었다 [Figure 2].

Figure 1 — Supervision-Perception Mismatch 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 LVLM 내부의 Generative-Discriminative Gap을 활용하여 신뢰성 있는 자체 검증(self-verification) 데이터를 얻고, 이를 통해 모델을 지속적으로 정교화하는 OSCAR 프레임워크를 제안한다 [Figure 3]. OSCAR는 Monte Carlo Tree Search(MCTS)를 통해 생성 공간을 탐색하며, 학습 과정에서 사전 정의된 Dual-Granularity Reward를 사용하여 각 생성 경로의 품질을 평가한다 [Figure 4]. 노드 수준에서는 해당 문장에 대한 판별 모델의 응답 확률(Process Reward)을, 전체 궤적 수준에서는 시각적 충실도가 보장될 경우에만 품질 점수를 부여하는 Gated Outcome Reward를 적용한다. 이를 통해 추출된 선호도 쌍은 Direct Preference Optimization (DPO) 를 통해 모델 업데이트에 활용된다. 실험 결과, OSCAR를 적용한 LLaVA-1.5-7B는 Object-HalBench의 CHAIR_S_ 지표에서 baseline 대비 약 43.7% 수준으로 hallucination을 감소시켰으며(49.0 → 27.6), AMBER 벤치마크의 Hal score 또한 현저히 개선하는 성과를 보였다 [Table 1]. 특히, 3회의 반복 학습(Iter1~3)을 통해 성능이 점진적으로 향상되는 과정을 보이며 online self-improvement의 효과를 입증하였다.

Figure 3 — Generative-Discriminative Gap 예시
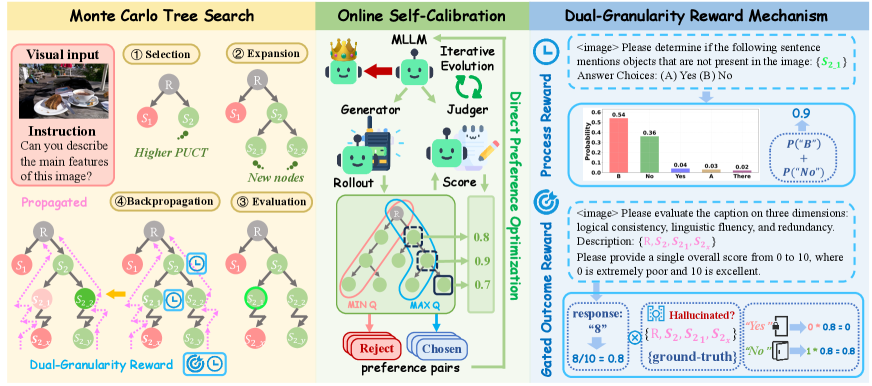
Figure 4 — OSCAR 전체 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LVLM의 hallucination을 완화하기 위해 외부 데이터 의존성을 줄이고 모델 고유의 판별 역량을 활용하는 online 학습 프레임워크인 OSCAR를 제시한다. MCTS를 활용한 lookahead 전략과 dual-granularity 보상 체계는 모델이 생성 과정에서 발생할 수 있는 잠재적 hallucination을 사전에 억제하도록 유도한다. 이 연구는 vision-language 모델의 학습 방식이 단순한 모방 학습에서 모델의 인식 한계를 존중하는 능동적 자기 교정(self-calibration)으로 전환되어야 함을 시사한다. 이러한 접근 방식은 의료, 자율주행 등 factual grounding이 필수적인 분야에서 LVLM의 신뢰성을 크게 향상시킬 수 있는 핵심 기법이 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ELV-Halluc: Benchmarking Semantic Aggregation Hallucinations in Long Video Understanding
- [논문리뷰] When Classic Cache Policies Fail: Learning-Augmented Replacement for Semantic Retrieval Buffers
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
Review 의 다른글
- 이전글 [논문리뷰] Map2World: Segment Map Conditioned Text to 3D World Generation
- 현재글 : [논문리뷰] Online Self-Calibration Against Hallucination in Vision-Language Models
- 다음글 [논문리뷰] Talker-T2AV: Joint Talking Audio-Video Generation with Autoregressive Diffusion Modeling
댓글