[논문리뷰] Talker-T2AV: Joint Talking Audio-Video Generation with Autoregressive Diffusion Modeling
링크: 논문 PDF로 바로 열기
메타데이터
저자: Guangyan Zhang, Hongzhan Lin, Aoxiong Yin, Xu Tan, Zhen Ye, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Talker-T2AV: 텍스트로부터 오디오와 비디오를 공동 생성하고, 오디오 기반 talking head 생성 및 비디오 더빙까지 하나의 아키텍처로 수행하는 autoregressive diffusion 프레임워크.
- Dual-branch diffusion transformer (dual-DiT): 기존의 일반적인 오디오-비디오 공동 생성 방식으로서, 두 개의 독립적인 DiT tower가 cross-attention을 통해 상호 작용하는 구조.
- Autoregressive (AR) Backbone: 텍스트, 음성, 비디오 latent를 통합적으로 추론하여 고수준의 temporal structure를 계획하는 causal language model 기반 모듈.
- Modality-specific decoding: AR backbone에서 도출된 hidden state를 입력받아 각 modality(오디오, 비디오)의 특성에 맞춰 세부적인 신호를 생성하는 독립적인 두 개의 diffusion transformer head.
- Element-wise summation: 서로 다른 modality의 latent patch embedding을 시각적으로 정렬된 동일한 위치에서 합산하여 통합 토큰을 형성하는 융합 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 dual-branch diffusion transformer 구조가 갖는 talking head 생성에서의 한계를 해결하고자 한다. 저자들은 기존 모델들이 denoising 과정 전반에서 pervasive attention을 사용해 고수준의 의미론적 모듈링과 저수준의 신호 렌더링을 완전히 결합(entangled)함으로써 비효율적인 모델링을 초래한다고 지적한다. 또한, 이러한 모델들은 본질적으로 non-autoregressive하여 사전 설정된 출력 길이에 제약을 받으며, 자연스러운 가변 길이 생성이 어렵다는 단점이 있다 [Figure 1]. 따라서 저자들은 고수준의 cross-modal 계획은 공동 모델링하되, 저수준의 렌더링은 modality-specific하게 분리하는 효율적인 설계 원칙을 제안한다.
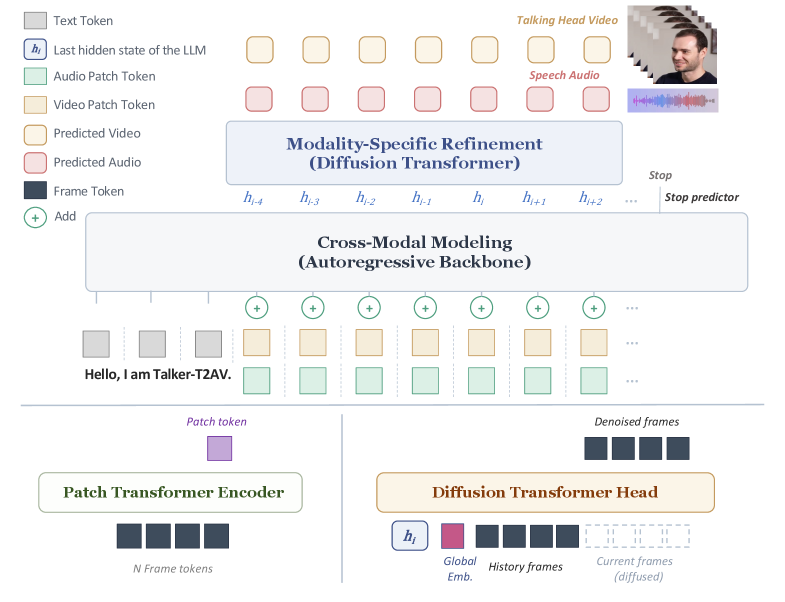
Figure 1 — Talker-T2AV의 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Talker-T2AV를 통해 세대 과정을 고수준 cross-modal 모듈링과 저수준 modality-specific 렌더링으로 이원화한다. Autoregressive backbone은 텍스트 조건 하에서 오디오와 비디오 patch를 autoregressive하게 예측하며, 각 patch는 element-wise summation을 통해 융합되어 temporal coherence를 보장한다 [Figure 1]. 각 modality-specific diffusion head는 동일한 shared hidden state를 입력받아 최적의 optimal-transport conditional flow matching (OT-CFM)을 수행한다. 실험 결과, Talker-T2AV는 기존 dual-DiT 기반 베이스라인 대비 중국어 및 영어 벤치마크에서 뛰어난 성능을 보였다. 구체적으로, joint audio-video 생성에서 가장 낮은 CER (Chinese) 및 WER (English)를 기록하며 발화 이해도를 크게 개선하였다. 또한, SyncNet 지표에서 최고 수준의 Confidence를 달성하여 Lip-sync accuracy 면에서도 우수한 정량적 결과를 입증하였다 [Table 1, Table 2, Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 오디오와 비디오의 생성을 고수준 계획과 저수준 렌더링으로 명확히 구분함으로써 생성 품질과 효율성을 동시에 확보한 Talker-T2AV를 제시하였다. 단일 모델로 세 가지 서로 다른 생성 작업을 아키텍처 수정 없이 수행할 수 있는 범용성을 입증했으며, 이는 향후 멀티모달 생성 연구의 아키텍처 설계에 중요한 방향성을 제시한다. 특히 autoregressive한 생성 방식의 도입은 자연스러운 speaking rate와 variable-length 출력을 가능하게 하여, 실시간 서비스 및 고도화된 콘텐츠 생성 분야에 큰 기여를 할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Online Self-Calibration Against Hallucination in Vision-Language Models
- 현재글 : [논문리뷰] Talker-T2AV: Joint Talking Audio-Video Generation with Autoregressive Diffusion Modeling
- 다음글 [논문리뷰] Trees to Flows and Back: Unifying Decision Trees and Diffusion Models
댓글