[논문리뷰] Thinking in Uncertainty: Mitigating Hallucinations in MLRMs with Latent Entropy-Aware Decoding
링크: 논문 PDF로 바로 열기
저자: Zhongxing Xu, Zhonghua Wang, Zhe Qian, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multimodal Large Reasoning Models (MLRMs) : 시각 및 언어 정보를 통합하여 복합적인 추론 체인(reasoning chains)을 생성하는 대규모 모델.
- Hallucinations : MLRMs가 생성하는 내용이 시각적 증거(visual evidence)나 논리적 일관성과 모순되는 현상.
- Latent Entropy-Aware Decoding (LEAD) : MLRMs의 추론 신뢰성을 향상시키고 Hallucinations를 완화하기 위해 제안된 플러그-앤-플레이(plug-and-play) 디코딩 전략.
- Entropy-Aware Reasoning Mode Switching : 토큰 수준의 엔트로피(token-level entropy)를 기반으로 모델의 추론 모드를 동적으로 전환하는 LEAD의 핵심 메커니즘. 높은 엔트로피 상태에서는 Latent Reasoning을, 낮은 엔트로피 상태에서는 Discrete Decoding을 사용한다.
- Visual Anchor Injection : 불확실한 추론 단계에서 모델이 시각적 정보에 집중하도록 유도하기 위해, Pre-trained visual embeddings에서 파생된 가이던스 벡터(guidance vector)를 주입하는 전략.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 MLRMs는 Visual Question Answering 등 다양한 태스크에서 뛰어난 성능을 보였지만, 여전히 심각한 Hallucinations 문제에 직면해 있습니다. 저자들은 transition words (예: "because", "however")가 Hallucinations 와 밀접하게 연관되어 있으며, 이러한 단어들이 높은 엔트로피(high-entropy) 상태를 나타낸다는 것을 발견했습니다
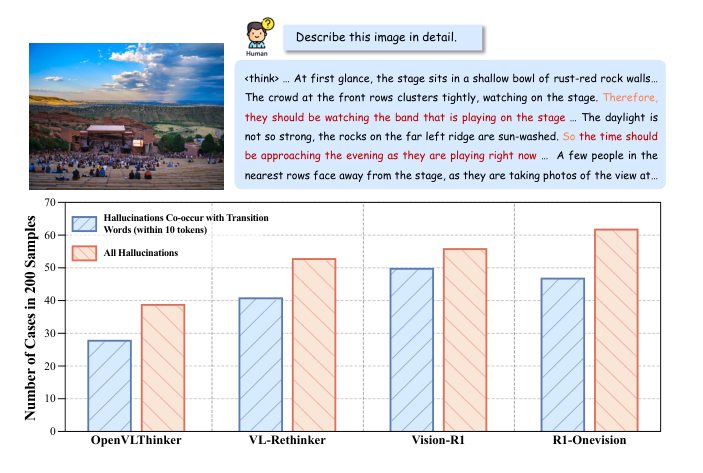 Figure 1: Illustrations of the correlation between hallucinations and transition words. In MLRMs, hallucinations tend to emerge more frequently after transition words, and these cases constitute a significant proportion of the overall hallucination occurrences.
Figure 1: Illustrations of the correlation between hallucinations and transition words. In MLRMs, hallucinations tend to emerge more frequently after transition words, and these cases constitute a significant proportion of the overall hallucination occurrences.
. 이러한 high-entropy 단계에서는 모델이 semantic divergence 와 잠재적 추론 경로(potential reasoning paths) 간의 경쟁에 직면하여 Hallucinations 발생 가능성이 높아집니다. 기존 연구들은 시각적 보상(visual reward) 설계나 데이터 증강(data augmentation)을 통해 Hallucinations 를 완화하려 했지만, 상당한 추가 비용을 초래하는 한계가 있었습니다. 본 연구는 이산적인 텍스트 입력(discrete textual inputs)에 의존하는 기존 모델이 high-entropy 추론 단계에서 밀도 높은 맥락적 단서(dense contextual cues)를 효과적으로 활용하지 못한다는 가설을 세우고, 토큰 확률 분포로부터 풍부한 의미론적 표현을 구성하여 이러한 문제를 해결하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Hallucinations 를 완화하기 위해 Latent Entropy-Aware Decoding (LEAD) 이라는 효율적인 플러그-앤-플레이 디코딩 전략을 제안합니다. LEAD 의 핵심은 Entropy-Aware Reasoning Mode Switching 으로,
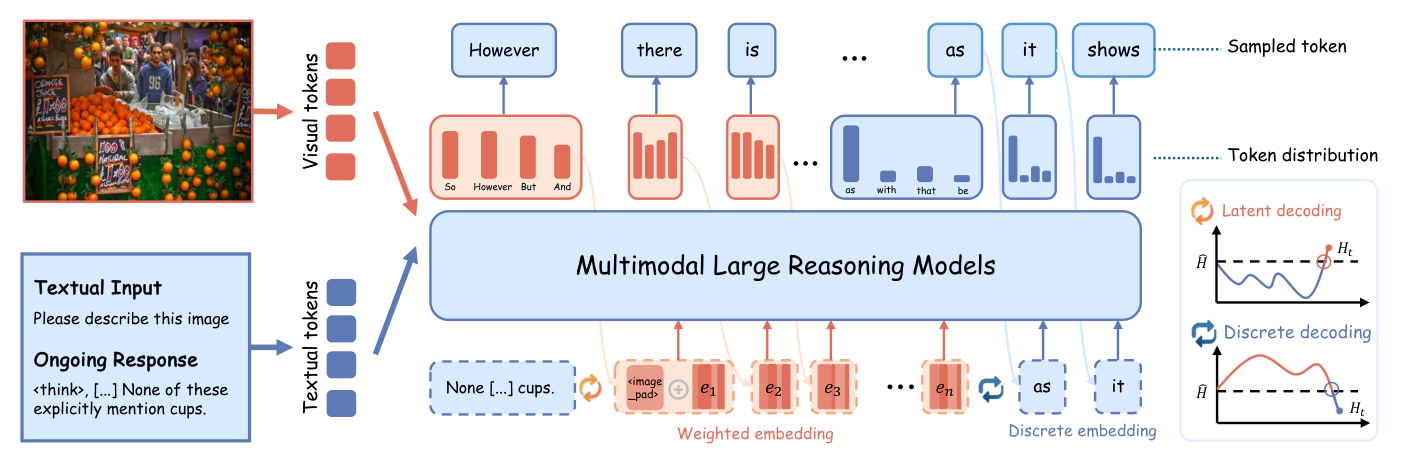 Figure 4: Illustration of multimodal reasoning and entropy-aware decoding. The model receives both visual and textual tokens (left) and generates responses by integrating contextual information. During reasoning, token-level entropy Ht measures model confidence and is compared with the reference entropy H. High-entropy states (orange) trigger latent decoding, using probability-weighted embeddings to preserve semantic diversity, while low-entropy states (blue) activate discrete decoding, using sampled tokens for precise semantic convergence. This adaptive switching mechanism balances exploration and commitment in multimodal reasoning.
Figure 4: Illustration of multimodal reasoning and entropy-aware decoding. The model receives both visual and textual tokens (left) and generates responses by integrating contextual information. During reasoning, token-level entropy Ht measures model confidence and is compared with the reference entropy H. High-entropy states (orange) trigger latent decoding, using probability-weighted embeddings to preserve semantic diversity, while low-entropy states (blue) activate discrete decoding, using sampled tokens for precise semantic convergence. This adaptive switching mechanism balances exploration and commitment in multimodal reasoning.
에 설명된 바와 같이 모델의 엔트로피 수준에 따라 추론 모드를 동적으로 전환합니다. 모델이 high-entropy 상태에 진입하면, probability-weighted continuous embeddings 를 사용하여 잠재된 의미론적 다양성(semantic diversity)을 유지하는 Latent Reasoning Decoding 을 활성화합니다. 반대로 엔트로피가 감소하면 모델은 discrete token embeddings 를 사용하는 일반적인 Discrete Decoding 으로 전환하여 안정적인 수렴을 달성합니다. 또한, LEAD 는 high-entropy 단계의 첫 토큰에 prior-guided visual anchor injection strategy 를 도입하여 모델이 시각 정보에 집중하도록 유도함으로써 visual grounding 을 강화합니다.
광범위한 실험 결과, LEAD 는 다양한 MLRMs 에서 Hallucinations 완화에 탁월한 성능을 보였습니다. 특히, R1-Onevision-7B 에 플러그인으로 통합했을 때, General Reasoning 및 Understanding 태스크에서 평균 +3.6% 의 성능 향상을 보였으며, MMHalu 및 Bingo 와 같은 Hallucination 지표에서는 각각 +4.7% 및 +3.8% 상승했습니다
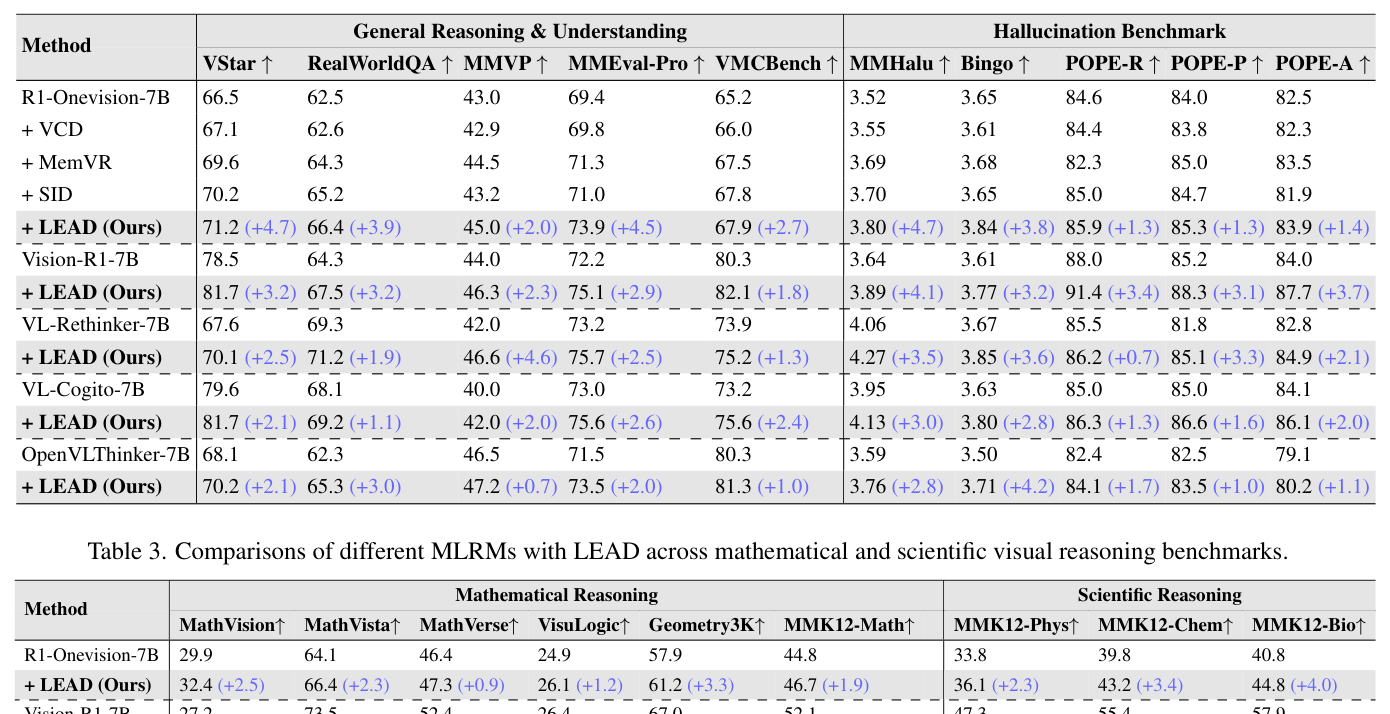 Table 2: Comparisons of different MLRMs with LEAD across general reasoning and hallucination benchmarks. Scores are reported for MMHalu (ranging from 0 to 6) and Bingo (ranging from 1 to 5), while accuracy is reported for all other benchmarks.
Table 2: Comparisons of different MLRMs with LEAD across general reasoning and hallucination benchmarks. Scores are reported for MMHalu (ranging from 0 to 6) and Bingo (ranging from 1 to 5), while accuracy is reported for all other benchmarks.
. Entropy Threshold 에 대한 실험에서 동적 임계값 설정은 R1-Onevision 및 Vision-R1 모델의 MMHalu 점수를 각각 +4.7% 및 +4.1% 향상시키며 최적의 성능을 달성했습니다 [Figure 5]. Visual Anchor Injection 강도 실험에서는 λ=0.4 에서 모든 데이터셋에 걸쳐 가장 좋은 성능을 보였습니다 [Table 1]. MathVision 데이터셋에서 평가된 추론 효율성 측면에서, LEAD 는 높은 정확도를 유지하면서도 기존 Baseline 대비 더 짧은 추론 길이(reasoning length)를 생성하는 것으로 나타났습니다 [Figure 9].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 transition words 가 high-entropy 추론 상태와 자주 일치하며, 이는 Hallucinations 경향이 있는 행동과 강한 연관성이 있음을 밝혀냈습니다. 또한, Hallucinations 와 관련된 high-entropy 토큰들은 현저히 낮은 시각적 주의(visual attention)를 받는 경향이 있어, 모델이 불확실성 조건에서 시각 정보를 간과함을 시사합니다. 이러한 관찰을 바탕으로 저자들은 Latent Entropy-Aware Decoding (LEAD) 을 제안합니다. LEAD 는 entropy-aware reasoning mode switching 과 visual anchor injection 메커니즘을 통해 MLRMs 의 추론 신뢰성을 강화하고 다중 모드 Hallucinations 를 효과적으로 완화합니다. LEAD 는 일반 및 과학적 벤치마크 모두에서 일관되게 우수한 성능을 입증하며, MLRMs 의 Hallucinations 문제에 대한 효과적인 해결책을 제시합니다. 이 연구는 MLRMs 의 불확실성 관리에 대한 새로운 시각을 제공하며, 모델의 신뢰성과 안전성을 높이는 데 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
- [논문리뷰] Multimodal Continuous Reasoning via Asymmetric Mutual Variational Learning
- [논문리뷰] GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
- [논문리뷰] GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents
- [논문리뷰] V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
Review 의 다른글
- 이전글 [논문리뷰] TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas
- 현재글 : [논문리뷰] Thinking in Uncertainty: Mitigating Hallucinations in MLRMs with Latent Entropy-Aware Decoding
- 다음글 [논문리뷰] WiT: Waypoint Diffusion Transformers via Trajectory Conflict Navigation
댓글