[논문리뷰] MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
링크: 논문 PDF로 바로 열기
저자: Wei Yu, Runjia Qian, Yumeng Li, et al.
1. Key Terms & Definitions
- MosaicMem : Explicit 3D 구조를 활용한 정확한 localization 및 targeted retrieval과 모델의 native conditioning을 통한 prompt-following generation을 결합한 하이브리드 공간 메모리 디자인입니다.
- Explicit Spatial Memory : 외부 3D estimation (예: point cloud, 3D Gaussians)을 사용하여 scene geometry를 캐싱하고, revisits 시 이를 queried viewpoint에 재투영하여 generation을 condition하는 방식입니다.
- Implicit Spatial Memory : 모델의 latent representation에 world state를 저장하며, attention 메커니즘을 통해 posed frame이나 frame-derived features를 retrieval하는 방식입니다.
- PROPE (Projective Positional Encoding) : DiT(Diffusion Transformer) 기반 video generation을 위한 principled camera conditioning interface로, relative camera frustum geometry를 self-attention에 직접 주입하여 viewpoint controllability를 향상시킵니다.
- Warped RoPE / Warped Latent : MosaicMem 내에서 retrieved memory patches의 alignment를 개선하기 위한 두 가지 메커니즘입니다. Warped RoPE 는 pixel-accurate correspondence를 기반으로 latent space에서 patches를 정렬하며, Warped Latent 는 feature space에서 spatial resampling을 통해 patches를 직접 변환합니다.
2. Motivation & Problem Statement
비디오 diffusion 모델은 단순한 plausible clip 생성에서 카메라 모션, revisits, 그리고 intervention 하에서 일관성을 유지하는 world simulator로 발전하고 있습니다. 그러나 spatial memory는 이러한 long-horizon, physically consistent interaction을 위한 핵심 bottleneck으로 남아 있습니다. 기존 연구의 한계점은 다음과 같습니다. Explicit Spatial Memory 는 reprojection-based consistency를 제공하지만, dynamic environment에서 움직이는 객체를 다루는 데 어려움이 있으며, 일관된 캐시를 유지하고 업데이트하기 어렵습니다. 반면, Implicit Spatial Memory 는 dynamic하고 non-rigid한 변화에 유연하게 대응하지만, 정확한 camera motion을 생성하지 못해 revisits 시 noticeable drift를 유발하며, frame-based representation이 highly redundant하여 stability 및 efficiency가 떨어집니다. 따라서, 저자들은 이 두 패러다임의 강점을 결합하여 이러한 한계를 극복하고, persistent하며 explorable한 비디오 world simulator를 구축할 필요성을 제기합니다
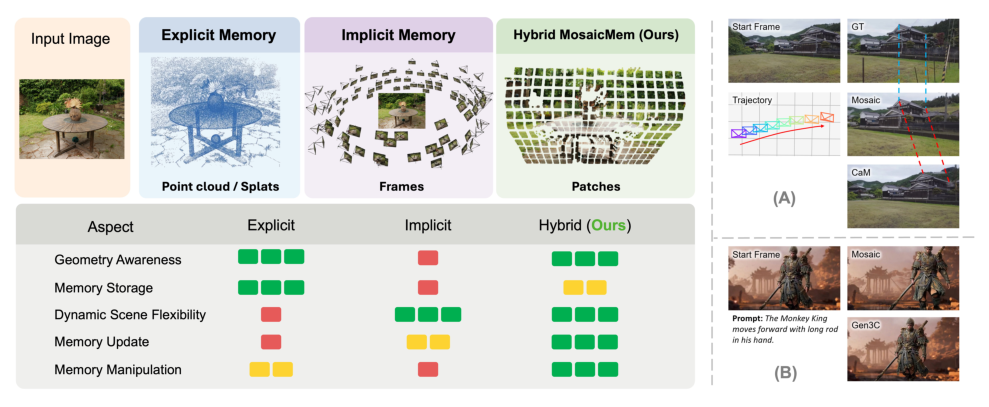 Figure 1: Memory mechanism comparison and visualization. MoscaicMem is a hybrid approach, unifies the strengths of explicit and implicit memory.
Figure 1: Memory mechanism comparison and visualization. MoscaicMem is a hybrid approach, unifies the strengths of explicit and implicit memory.
.
3. Method & Key Results
저자들은 Mosaic Memory (MosaicMem) 를 제안합니다. 이는 video patches를 3D로 lifting하여 reliable localization 및 targeted retrieval을 가능하게 하며, 모델의 native conditioning을 활용하여 prompt-following generation을 보존하는 하이브리드 spatial memory 메커니즘입니다. MosaicMem 은 queried view에서 spatially aligned memory patches를 "patch-and-compose" interface를 통해 구성하여, 지속되어야 할 부분을 유지하면서 모델이 발전해야 할 부분을 inpaint 및 update하도록 합니다
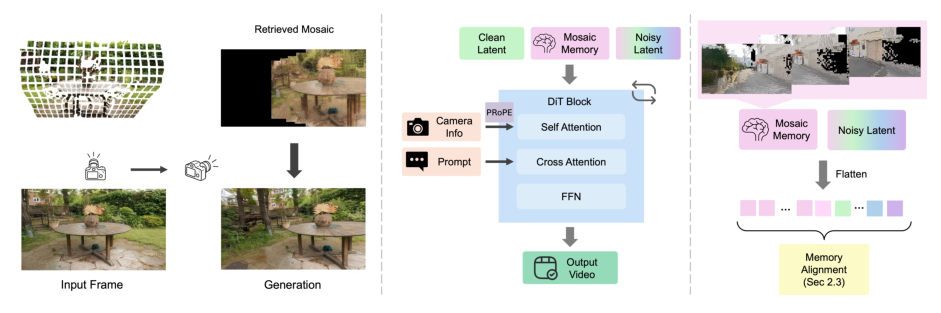 Figure 2: Method overview. Left: MosaicMem lifts patches into 3D, then gathers and stitches them in the target view like a mosaic. Middle: Architecture overview. Camera motion is controlled jointly by MosaicMem retrieval and PROPE conditioning. Right: Retrieved mosaic patches are flattened and concatenated to the token sequence as conditioning, while alignment errors were solved by warping.
Figure 2: Method overview. Left: MosaicMem lifts patches into 3D, then gathers and stitches them in the target view like a mosaic. Middle: Architecture overview. Camera motion is controlled jointly by MosaicMem retrieval and PROPE conditioning. Right: Retrieved mosaic patches are flattened and concatenated to the token sequence as conditioning, while alignment errors were solved by warping.
. 또한, PROPE 를 principled camera conditioning interface로 통합하여 viewpoint controllability를 향상시켰습니다. Spatiotemporal ambiguity와 RoPE coordinate resolution 문제를 해결하기 위해 Warped RoPE 와 Warped Latent 라는 두 가지 새로운 memory alignment 방법을 도입했습니다.
실험 결과, MosaicMem 은 다양한 metrics에서 기존 baseline 모델들을 크게 능가했습니다
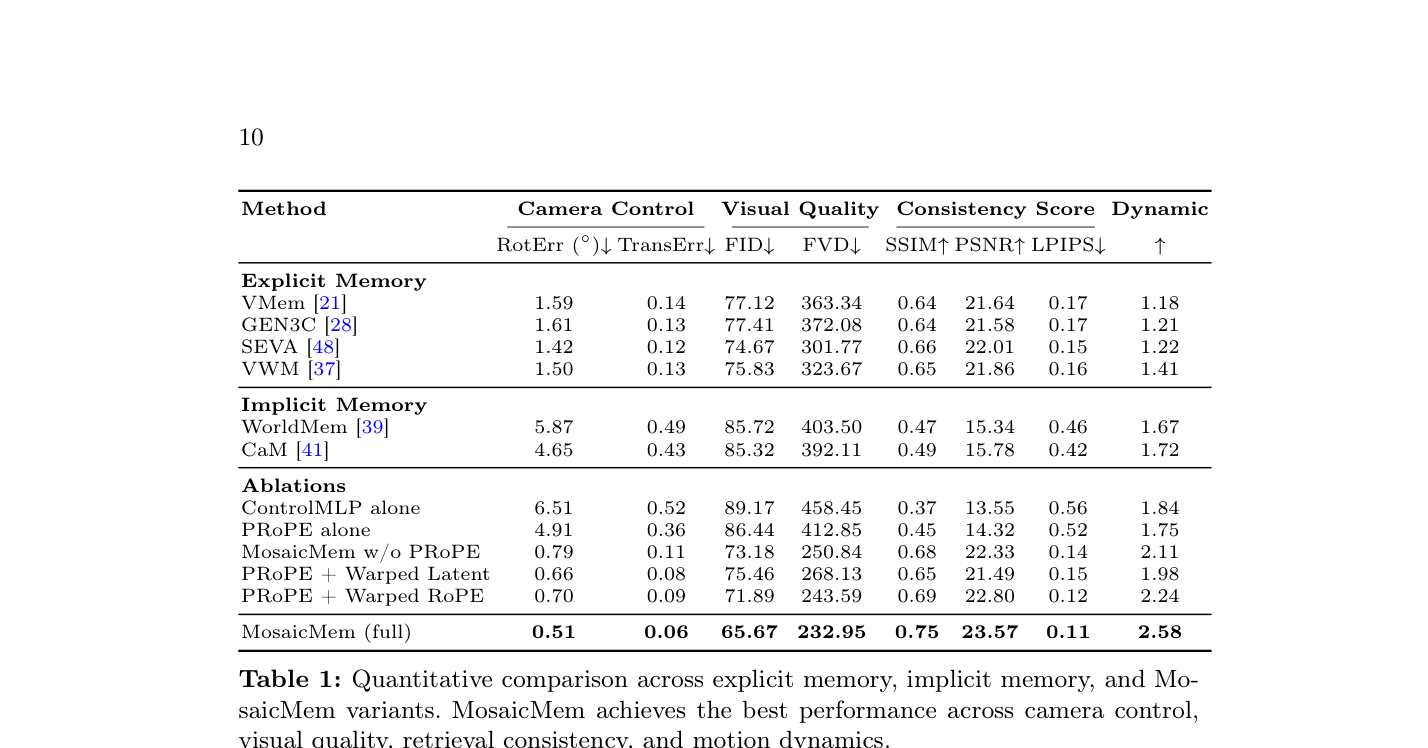 Table 1: Quantitative comparison across explicit memory, implicit memory, and MosaicMem variants. MosaicMem achieves the best performance across camera control, visual quality, retrieval consistency, and motion dynamics.
Table 1: Quantitative comparison across explicit memory, implicit memory, and MosaicMem variants. MosaicMem achieves the best performance across camera control, visual quality, retrieval consistency, and motion dynamics.
. MosaicMem 은 explicit memory baseline (GEN3C, VWM 등) 대비 Dynamic Score 가 월등히 높아 (예: 2.58 vs. 1.18 ~ 1.41 ) 동적인 객체 모델링에 강점을 보였으며, implicit memory baseline (WorldMem, CaM) 대비 RotErr ( 0.51 ° vs. 4.65 °~ 5.87 °) 및 TransErr ( 0.06 vs. 0.43 ~ 0.49 )이 현저히 낮아 카메라 모션 정확도와 memory retrieval consistency가 크게 개선되었습니다. FID ( 65.67 ) 및 FVD ( 232.95 ) 점수에서도 가장 낮은 값을 기록하여 전반적인 visual quality가 우수함을 입증했습니다. Ablation study 결과, PROPE 와 Warped RoPE/Latent 의 조합이 전체 모델 성능에 critical한 기여를 하며, 특히 두 warping 전략의 혼합 학습이 가장 robust한 memory conditioning을 제공하는 것으로 나타났습니다. MosaicMem 은 또한 autoregressive video generation (Mosaic Forcing)에서도 16 FPS 의 real-time 성능을 달성하며, Table 2 에서 기존 AR 시스템들 (RELIC, Matrix-Game 2.0)보다 모든 quality 및 consistency metrics에서 우수한 성능을 보였습니다.
4. Conclusion & Impact
MosaicMem 은 explicit 및 implicit spatial memory 패러다임의 강점을 성공적으로 결합한 하이브리드 spatial memory 메커니즘입니다. 이 연구는 비디오 패치를 3D로 lifting하여 정확한 localization 및 retrieval을 가능하게 하고, 동시에 attention 기반 conditioning을 통해 dynamic한 scene evolution을 유지함으로써, 정확한 egomotion과 풍부한 prompt-driven dynamics를 제공합니다. PROPE 를 통한 정교한 viewpoint control과 동적인 변화를 포함하는 새로운 benchmark의 도입은 이 연구의 중요한 기여입니다.
이러한 결과는 MosaicMem 이 long-horizon, 카메라 제어 비디오 생성, memory 기반 scene editing, 그리고 autoregressive rollout generation 등 다양한 controllable capabilities를 가능하게 함을 시사합니다. 이는 generative video를 단순한 synthesis를 넘어, decision-making 및 reinforcement learning을 위한 actionable substrate로 전환시키는 실질적인 길을 제시하며, 미래의 persistent하고 explorable한 비디오 world simulator 개발에 중요한 발판을 마련합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Infinite Worlds with Versatile Interactions
- [논문리뷰] Imagined Rollouts are Kinematic, Not Dynamic: A Diagnosis of Long-Horizon World-Model Failure
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
- [논문리뷰] AlayaWorld: Long-Horizon and Playable Video World Generation
- [논문리뷰] The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
Review 의 다른글
- 이전글 [논문리뷰] MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
- 현재글 : [논문리뷰] MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
- 다음글 [논문리뷰] RAMP: Reinforcement Adaptive Mixed Precision Quantization for Efficient On Device LLM Inference
댓글