[논문리뷰] MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
링크: 논문 PDF로 바로 열기
저자: Peng Xia, Jianwen Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MetaClaw : 배포된 LLM agent 가 정상적인 사용을 통해 지속적으로 meta-learn 하고 evolve 할 수 있도록 하는 continual meta-learning framework .
- Skill-driven fast adaptation : 실패 trajectory 를 분석하여 새로운 행동 instruction ( skill )을 합성하고 즉시 agent 의 prompt 에 주입하여 zero service downtime 으로 적용하는 gradient-free skill evolution 메커니즘.
- Opportunistic policy optimization : user-inactive window 동안 process reward model (PRM) 을 사용하여 cloud LoRA fine-tuning 을 통해 agent 의 기본 LLM policy weight 를 gradient-based 로 업데이트하는 메커니즘.
- Opportunistic Meta-Learning Scheduler (OMLS) : user 의 sleep hours , system keyboard inactivity , Google Calendar occupancy 를 모니터링하여 opportunistic policy optimization 을 위한 user-inactive window 를 식별하고 RL training 을 트리거하는 스케줄러.
- Skill generation versioning : policy optimization 이 stale reward contamination 을 방지하고 항상 agent 의 post-adaptation behavior 를 반영하는 query data 에 대해서만 학습하도록 support data 와 query data 를 엄격하게 분리하는 메커니즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large language model (LLM) agent 는 복잡한 multi-step task 에서 강력한 성능을 보여왔지만, 실제 배포 환경에서 사용되는 agent 는 한 번 훈련되면 user 의 요구사항 변화에 관계없이 고정된 상태로 제공됩니다. 이러한 정적인 특성은 task distribution 이 변화함에 따라 agent 의 capability 가 뒤떨어지고 반복적인 실패를 초래하는 근본적인 문제를 야기합니다. 기존 agent adaptation 접근 방식들은 memory-based method 가 방대한 trajectory 를 저장하지만 행동 패턴을 추출하지 못하거나, skill-based method 가 skill library 를 weight optimization 과 분리하여 다루거나, RL-based method 가 retraining 시 service downtime 을 발생시키는 등의 한계를 가집니다. 특히, skill 이 발전한 후 이전 skill context 에서 수집된 trajectory 가 stale reward 로 gradient update 를 오염시킬 수 있는 중요한 data validity 문제를 해결하지 못했습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 MetaClaw 라는 continual meta-learning framework 를 제안합니다. 이는 기본 LLM policy 와 재사용 가능한 행동 instruction 의 skill library 를 jointly 유지하고 개선합니다. MetaClaw 는 두 가지 보완적인 메커니즘을 통해 작동합니다. 첫째, Skill-driven fast adaptation 은 실패 trajectory 를 분석하고 LLM evolver 를 통해 새로운 skill 을 합성하여 zero service downtime 으로 즉시 적용합니다. 둘째, Opportunistic policy optimization 은 process reward model (PRM) 과 cloud LoRA fine-tuning 을 사용하여 post-adaptation trajectory 에 대한 gradient-based weight update 를 수행합니다. 이 업데이트는 OMLS 에 의해 user-inactive window 동안에만 트리거됩니다. Skill generation versioning 메커니즘은 stale reward contamination 을 방지하기 위해 skill evolution 에 사용되는 support data 와 RL update 에 사용되는 query data 를 엄격히 분리합니다.
MetaClaw-Bench (934개 질문, 44일 simulated workdays ) 및 AutoResearchClaw (23단계 autonomous research pipeline )에 대한 실험 결과는 MetaClaw 의 일관된 개선 효과를 입증합니다.
- Skill-driven adaptation 은 MetaClaw-Bench 에서 전체 accuracy 를 상대적으로 최대 32.2% 향상시켰습니다.
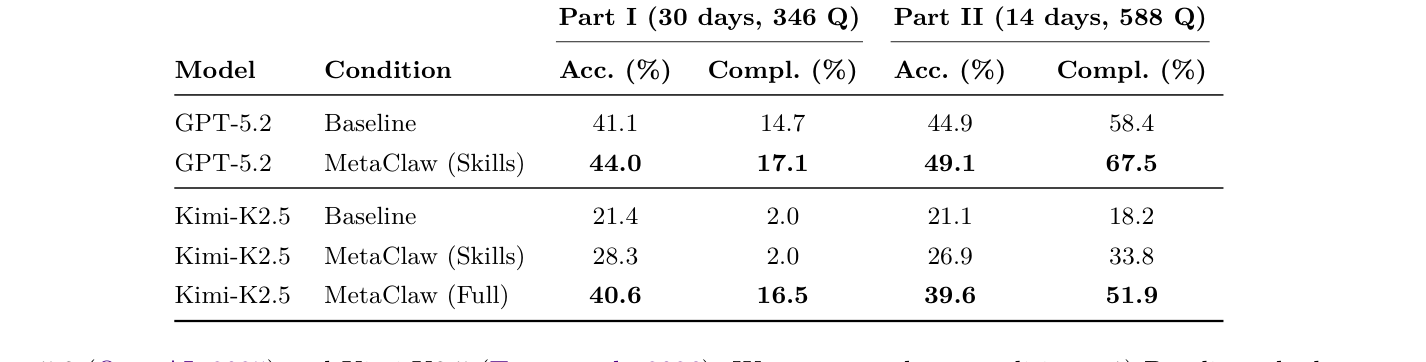 Table 1: Main results on MetaClaw-Bench Parts I and II. Acc.: mean per-question accuracy. Compl.: file-check completion rate. MetaClaw (Full) is evaluated for Kimi-K2.5 only. Best result per model per part is bolded.
Table 1: Main results on MetaClaw-Bench Parts I and II. Acc.: mean per-question accuracy. Compl.: file-check completion rate. MetaClaw (Full) is evaluated for Kimi-K2.5 only. Best result per model per part is bolded.
- MetaClaw (Full) 은 Kimi-K2.5 의 accuracy 를 21.4% 에서 40.6% 로, end-to-end task completion 을 8.25배 향상시켰으며, GPT-5.2 baseline 에 근접한 성능을 달성했습니다. [Table 1]
- AutoResearchClaw 에서 skill injection 만으로 composite robustness score 가 18.3% 향상되어, MetaClaw 의 adaptation mechanism 이 cross-domain 으로 generalize 됨을 보여주었습니다.
 Table 2: MetaClaw (Skills-Only) on AutoResearchClaw, a 23-stage autonomous research pipeline. Skill injection alone yields consistent improvements across all robustness metrics without requiring RL weight updates.
Table 2: MetaClaw (Skills-Only) on AutoResearchClaw, a 23-stage autonomous research pipeline. Skill injection alone yields consistent improvements across all robustness metrics without requiring RL weight updates.
4. Conclusion & Impact (결론 및 시사점)
MetaClaw 는 배포된 LLM agent 가 정상적인 사용을 통해 자율적으로 개선될 수 있도록 하는 continual meta-learning framework 입니다. 이 framework 는 fast , inference-time skill injection 과 slow , gradient-based policy optimization 이라는 두 가지 보완적인 adaptation mechanism 을 통합합니다. 특히, proxy-based architecture 를 통해 로컬 GPU 없이도 작동하며 기존 personal agent 및 LLM provider 와 투명하게 통합됩니다. MetaClaw-Bench 및 AutoResearchClaw 에 대한 평가는 부분적인 execution quality 와 end-to-end task completion 모두에서 MetaClaw 의 일관된 개선 효과를 보여주었습니다. 이 연구는 agent 가 wild 환경에서 진정으로 학습하고 evolve 할 수 있는 원칙적인 기반을 구축하며, 이는 production scale 에서 state-of-the-art 는 아니지만 유능한 model 을 효과적으로 배포하는 데 특히 중요합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
- 현재글 : [논문리뷰] MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
- 다음글 [논문리뷰] MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
댓글