[논문리뷰] Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
링크: 논문 PDF로 바로 열기
저자: Yulin Luo, Hao Chen, et al.
키워: Vision-Language-Action (VLA) models, Vision-Language Mixture-of-Transformers (VL-MoT), Action-Guided Visual Pruning (AGVP), Vision Expert, Robotic Manipulation, Visual Grounding, Large Language Models (LLM)
1. Key Terms & Definitions
- Vision-Language-Action (VLA) models : 로봇 조작을 위해 시각적 관찰과 언어 지침을 로봇 Action에 직접 매핑하는 모델.
- Vision-Language Mixture-of-Transformers (VL-MoT) : VLA 모델의 LLM backbone 에 Vision Foundation Model (Vision Expert)의 다중 레벨 시각적 Feature를 주입하여 시각적 Grounding을 강화하는 제안된 프레임워크.
- Action-Guided Visual Pruning (AGVP) : VLA 모델 의 얕은 Layer Attention을 활용하여 Task-relevant 시각적 Token을 보존하고 관련 없는 Token을 Pruning하여 계산 오버헤드를 최소화하면서 중요한 시각적 단서를 강화하는 전략.
- Vision Expert : DINOv3 와 같은 Vision Foundation Model로, VLA 모델 에 주입될 정교하고 의미론적으로 풍부한 시각적 Feature를 제공하는 데 사용됨.
- Visual Grounding : 시각적 정보가 Action 생성에 어떻게 통합되고 활용되는지를 의미하며, 모델이 Task-relevant 객체에 효과적으로 Attention을 집중하는 능력.
2. Motivation & Problem Statement
Vision-Language-Action (VLA) 모델은 로봇 조작에서 유망한 Paradigm으로 부상했지만, 신뢰할 수 있는 Action Prediction은 시각적 관찰과 언어 지침을 정확하게 해석하고 통합하는 데 크게 의존합니다. 기존 연구들은 VLA 모델의 시각적 능력을 향상시키려 노력했지만, 대부분 LLM backbone 을 Black Box로 취급하여 시각적 정보가 Action 생성에 어떻게 Grounding되는지에 대한 제한적인 Insight만을 제공했습니다. 본 연구는 여러 VLA 모델 에 대한 체계적인 분석을 통해 Action 생성 과정에서 시각적 Token에 대한 민감도가 더 깊은 Layer에서 점진적으로 감소한다는 중요한 현상을 발견했습니다 [Figure 1 (a), Figure 2]. 이는 현재 VLA 모델 의 직렬 아키텍처에서 시각적 정보가 첫 번째 LLM Layer 에서만 주입되고 Transformer Layer를 통해 전파될수록 점진적으로 감쇠되어, 깊은 Layer에서 Task-relevant 시각적 단서들이 제대로 활용되지 못함을 시사합니다. 이러한 한계는 정밀하고 복잡한 조작에서 Action Prediction의 신뢰성을 저해합니다.
3. Method & Key Results
저자들은 깊은 VLA Layer 의 Task-relevant 시각적 ROI에 대한 민감도를 높여 Action Prediction 정확도를 개선하기 위해 Vision-Language Mixture-of-Transformers (VL-MoT) 프레임워크와 Action-Guided Visual Pruning (AGVP) 전략을 제안합니다 [Figure 1 (b), Figure 3 (a)]. VL-MoT 는 기존 시각 Encoder 외에 전용 Vision Expert (DINOv3) 를 통합하고, 이 Vision Expert의 Feature를 MoT Mechanism 을 통해 VLA backbone 과 융합합니다. 특히, Vision Expert 의 마지막 몇 개의 Transformer Layer에서 추출된 다중 레벨 시각적 Feature를 VLA 모델 의 깊은 Layer에 선택적으로 주입하여, Vision Expert 의 고수준의 의미론적 Feature가 VLA 모델 의 Task-relevant, Action-conditioned Feature와 더 잘 호환되도록 합니다. 또한, AGVP 는 얕은 VLA Layer 의 Action-to-Vision Attention Map을 활용하여 Saliency Map을 계산하고, 이를 통해 가장 Task-relevant한 시각적 영역을 식별합니다 [Figure 3 (b)]. 이 Saliency Map은 Vision Expert 의 Transformer Layer에서 Query, Key, Value를 Pruning하여 관련 없는 Feature를 제거하고, 더 높은 해상도의 입력을 처리하면서도 계산 오버헤드를 최소화하여 핵심 시각적 정보를 깊은 VLA Layer 에 주입하는 데 사용됩니다.
제안된 DeepVision-VLA 프레임워크는 QwenVLA-OFT baseline을 기반으로 구현되었으며, 시뮬레이션 및 Real-World Task에서 SOTA 성능을 달성했습니다. RLBench 시뮬레이션 환경에서 DeepVision-VLA 는 평균 성공률 83% 를 기록하며, 기존 최강 baseline인 HybridVLA 의 74% 대비 9.0% 향상된 성능을 보였습니다
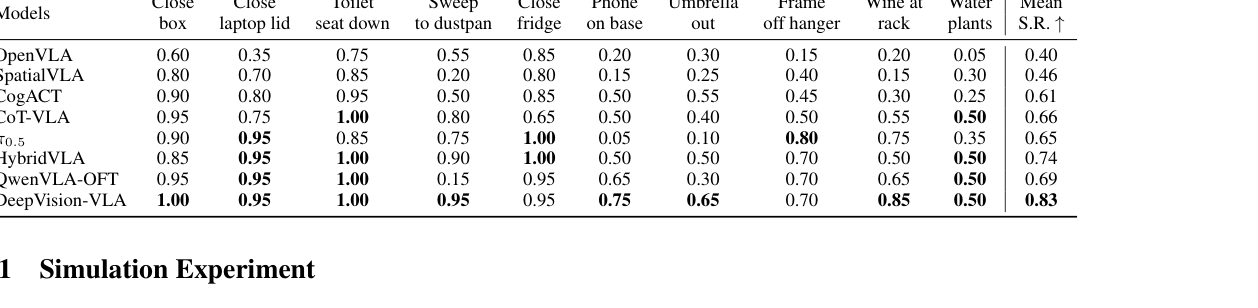 Table 1: Comparison of DeepVision-VLA and baselines on RLBench simulated manipulation tasks, reporting mean success rates.
Table 1: Comparison of DeepVision-VLA and baselines on RLBench simulated manipulation tasks, reporting mean success rates.
. 특히, QwenVLA-OFT baseline의 69% 대비 14% 개선된 성능을 보였습니다. Real-World Task에서도 DeepVision-VLA 는 평균 성공률 91.7% 를 달성하여, π0.5 (84.2%) 대비 7.5% 향상된 성능을 입증했습니다. Ablation Study 결과, VL-MoT 프레임워크가 88% 의 성공률로 다른 Vision Feature 통합 방식 ( Early Fusion 73% , Aligned DINOv3 67% )을 크게 상회하며, AGVP 의 Action-to-Vision Attention Guidance 역시 88% 로 가장 효과적인 Guidance 메커니즘임을 확인했습니다.
4. Conclusion & Impact
이 연구는 VLA 모델 에서 시각적 표현의 역할을 체계적으로 분석하고, 깊은 Layer에서 시각적 Token에 대한 민감도가 점진적으로 감소하는 문제를 해결했습니다. 저자들은 이 문제를 해결하기 위해 VL-MoT 아키텍처와 AGVP 전략을 결합한 DeepVision-VLA 를 제안했습니다. VL-MoT 는 Vision Expert 의 다중 레벨 시각적 Feature를 깊은 VLA Layer 에 주입하여 시각적 표현을 강화하고 Perception의 Grounding을 개선합니다. AGVP 는 얕은 Layer의 Attention을 기반으로 관련 없는 시각적 Token을 선택적으로 제거하여 Task-relevant 시각적 단서를 보존합니다. 광범위한 시뮬레이션 및 Real-World 로봇 조작 Task를 통해 DeepVision-VLA 는 기존 SOTA 방법론들을 지속적으로 능가하는 성능을 보여주며, 탁월한 일반화 능력과 로버스트함을 입증했습니다. 이 연구는 시각적으로 향상된 VLA 모델 설계에 대한 새로운 Insight를 제공하고, Foundation Vision Model과 로봇 조작의 통합에 대한 미래 연구를 위한 영감을 줄 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] LoST: Level of Semantics Tokenization for 3D Shapes
- 현재글 : [논문리뷰] Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
- 다음글 [논문리뷰] MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
댓글