[논문리뷰] AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
링크: 논문 PDF로 바로 열기
저자: Yuchao Gu, Guian Fang, Yuxin Jiang, Weijia Mao, Song Han, Han Cai, Mike Zheng Shou
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Flow Map: 시간 $t$에서 $r$로의 상태 전이를 학습하는 연산자로, 기존 consistency model의 고정된 endpoint mapping($z_t \rightarrow z_0$)을 일반화하여 임의의 시간 간격 전이를 지원함.
- On-Policy Distillation: 모델이 스스로 생성한 trajectory를 기반으로 학습하는 기법으로, student 모델의 test-time 오차를 줄이기 위해 사용됨.
- Flow Map Backward Simulation: 전체 ODE rollout을 shortcut transition으로 분해하여 효율적인 훈련과 discretization error 감소를 유도하는 핵심 시뮬레이션 전략임.
- NFE (Number of Function Evaluations): 비디오 생성 시 호출되는 모델의 추론 횟수로, 영상 품질과 연산 비용 간의 trade-off를 결정하는 핵심 지표임.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존 consistency distillation 기반 모델들이 고정된 NFE budgets에 종속되어 sampling step이 증가할 때 오히려 성능이 저하되는 구조적 한계를 해결하기 위해 AnyFlow를 제안한다. 기존 방식은 $z_t \rightarrow z_0$ 형태의 고정된 매핑에 의존하기 때문에 multi-step sampling 과정에서 반복적인 re-noising이 발생하며, 이로 인해 target PF-ODE trajectory로부터 drift가 발생하는 문제가 있다. 결과적으로 기존 모델들은 제한된 소수 step에서는 성능이 나오지만, 추가적인 연산 자원을 투입해도 품질 향상이 이루어지지 않는 불균형을 보인다 [Figure 1]. 이러한 문제점을 극복하기 위해 저자들은 임의의 step budget에 대응 가능한 유연한 any-step 프레임워크가 필요함을 강조한다.

Figure 1 — AnyFlow가 sampling step 증가에 따라 성능이 향상됨을 보여주는 핵심 비교 그래프
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 고정된 endpoint 매핑 대신 arbitrary time interval 간의 전이를 학습하는 flow map formulation을 도입하고, 이를 개선하기 위해 Flow Map Backward Simulation을 제안한다. 제안된 방법론은 학습 단계에서 Interpolated Timestep Conditioning과 Guidance-Fused Training 등을 통해 안정적인 훈련 환경을 구축하며, on-policy distillation을 통해 discretization error와 exposure bias를 효과적으로 제거한다 [Figure 4].

Figure 4 — AnyFlow의 전체 파이프라인 및 핵심 훈련 흐름을 보여주는 다이어그램
실험 결과, AnyFlow는 다양한 스케일(1.3B~14B parameters)에서 consistency-based 방법론보다 월등한 성능을 입증하였다. 정량적으로 AnyFlow-FAR-14B 모델은 4 NFE에서 VBench 84.05점을 기록하여 Krea-Realtime-14B(83.25점)를 능가하였고, 32 NFE에서는 84.41점으로 성능이 개선되는 우수한 scaling 거동을 보여주었다 [Table 2]. 특히 image-to-video 생성 성능(87.87) 또한 최고 수준의 기존 모델들과 대등한 결과를 보이면서도 훨씬 적은 NFE로 높은 효율성을 달성하였다 [Table 4].
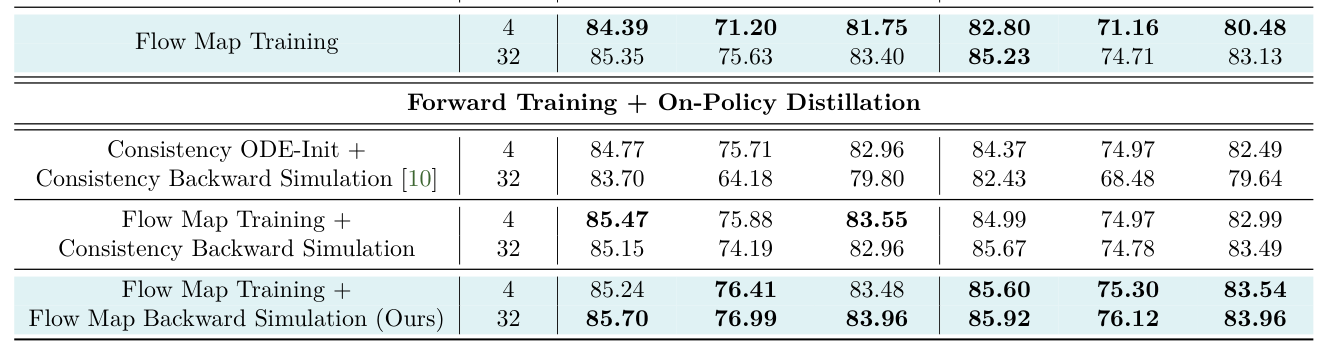
Table 2 — 제안 방법론의 ablation study 및 주요 성능 지표 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 flow map 기반의 새로운 distillation 프레임워크를 통해 비디오 확산 모델의 유연한 any-step 생성을 가능하게 함으로써 추론 품질과 latency 간의 최적의 균형을 제시하였다. AnyFlow는 고정된 step budget에 얽매이지 않고 sampling step이 증가함에 따라 품질이 정밀하게 향상되는 성질을 보장한다. 이 연구는 고해상도 비디오 생성 분야에서 대규모 모델의 실시간 배포와 고품질 요구사항을 동시에 만족시킬 수 있는 확장 가능한 경로를 제공하며, 차후 autoregressive long-video 생성 기술로의 발전 가능성을 시사한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Infinite Worlds with Versatile Interactions
- [논문리뷰] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
- [논문리뷰] The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
- [논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
Review 의 다른글
- 이전글 [논문리뷰] δ-mem: Efficient Online Memory for Large Language Models
- 현재글 : [논문리뷰] AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
- 다음글 [논문리뷰] Context Training with Active Information Seeking
댓글