[논문리뷰] The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes
링크: 논문 PDF로 바로 열기
저자: Siqi Zhu, Xuyan Ye, Hongyu Lu, Weiye Shi, Ge Liu
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- OPD (On-Policy Distillation): LLM의 자체 샘플링 궤적(trajectory)을 활용하여 교사 모델(Teacher)로부터 토큰 단위의 감독(token-level supervision)을 받는 학습 방법론입니다.
- OPSD (On-Policy Self-Distillation): 별도의 외부 모델 대신, 학생 모델 자체에 특권 정보(Privileged Information, PI)를 결합하여 교사 모델로 활용하는 기법입니다.
- TopK reverse-KL: GPU 메모리 효율을 위해 전체 어휘(full vocabulary) 대신 TopK 토큰만을 사용하여 산출하는 역방향 KL 발산 목적 함수입니다.
- RLVR (Reinforcement Learning with Verifiable Rewards): 검증 가능한 보상 체계를 통해 교사 모델의 성능을 향상시켜 학생 모델에게 더 양질의 학습 신호를 제공하는 기법입니다.
- PI (Privileged Information): 학습 시에만 모델에 주어지는 추가적인 정보로, Ground-truth, 시스템 프롬프트, 사용자 선호도 등이 포함됩니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 OPD와 OPSD가 시스템 프롬프트 및 지식 내재화에는 효과적이나, 최근 연구들에서 보고된 학습 불안정성(instability) 및 성능 저하(degradation) 문제를 근본적으로 규명하고자 합니다. 저자들은 이러한 성능 격차의 원인을 세 가지 실패 메커니즘인 '교사-학생 간 분포 불일치(distribution mismatch)', '편향된 TopK reverse-KL 그래디언트', 그리고 OPSD가 PI를 반영하지 못하고 단일 정책으로 수렴하는 제한적 특성으로 정의합니다. 특히 math reasoning 작업에서 이러한 기법들이 왜 실패하는지를 실증적으로 분석하며, 단순히 강력한 교사 모델을 사용하는 것만으로는 문제가 해결되지 않음을 [Figure 10]을 통해 증명합니다.
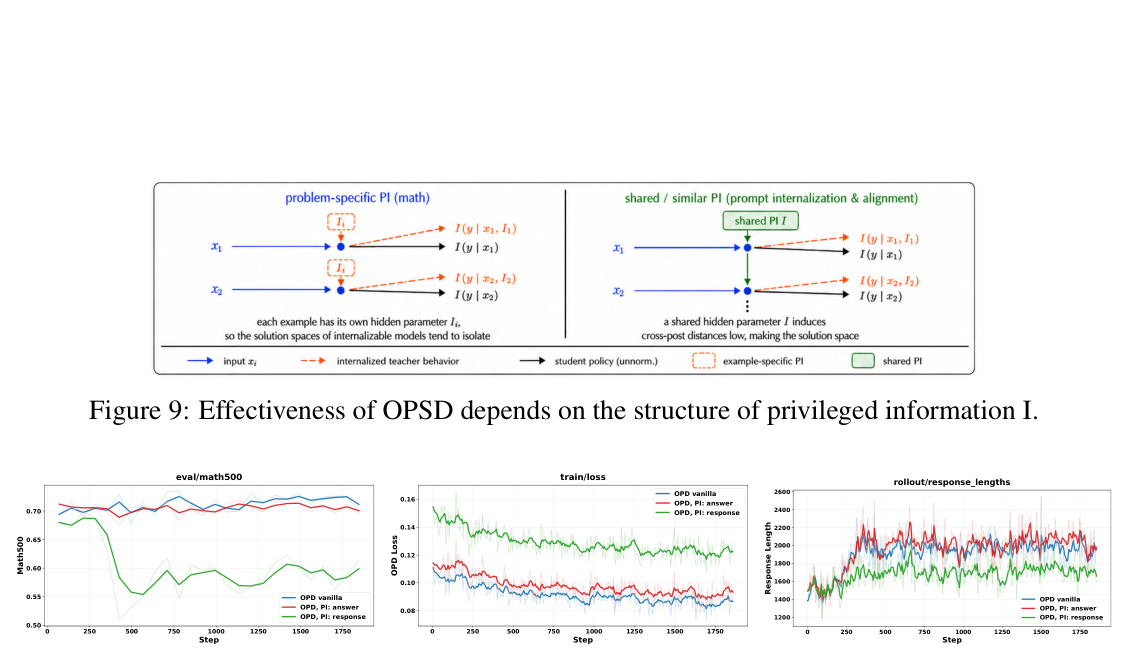
Figure 10 — 수학 추론 작업에서 PI(특권 정보)가 반드시 성능 향상을 보장하지 않는다는 점을 증명하는 핵심 실험 결과입니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 OPD 학습을 안정화하기 위한 세 가지 핵심 기술적 해결책을 제안합니다. 첫째, stop-gradient TopK 손실 함수를 도입하여 기존 TopK reverse-KL에서 발생하는 편향된 그래디언트 문제를 해결하였습니다. 둘째, RLVR을 통해 교사 모델을 훈련 데이터에 맞게 적응시킴으로써 학생 모델과의 분포 간극을 좁혔습니다. 셋째, 학습 초기 단계의 학생 모델이 garbled된 출력을 내놓는 문제를 해결하기 위해 SFT(Supervised Fine-Tuning)를 활용한 안정적인 초기화를 수행합니다. 실험 결과, 제안된 stop-gradient 기법은 [Figure 11]과 [Figure 15]에서 볼 수 있듯이 학습의 붕괴(collapse)를 방지하고 일관된 성능 향상을 보입니다. 또한, 수학 문제와 같은 사례별 특권 정보(instance-specific PI) 환경보다 시스템 프롬프트 등 공유된 잠재 규칙(shared latent rule) 환경에서 OPSD가 더 효과적임을 입증하였습니다.
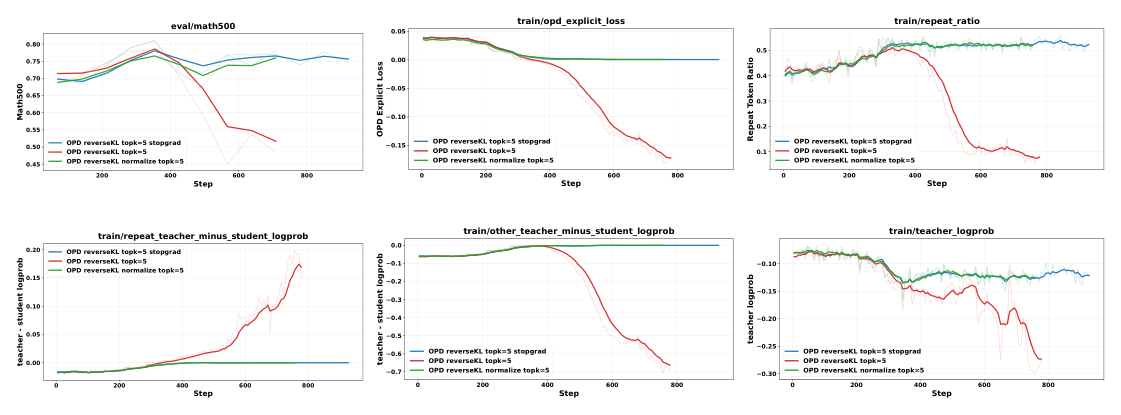
Figure 11 — 제안한 stop-gradient 기법이 학습 붕괴를 방지하는 효과를 정량적으로 보여주는 주요 그래프입니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 OPD와 OPSD의 성패가 작업 구조 및 특권 정보의 성격에 따라 결정됨을 밝히고, 실무적으로 적용 가능한 학습 안정화 가이드를 제시했습니다. 저자들은 단순한 교사 모델의 성능보다 교사와 학생 간의 분포 정렬(distributional alignment)이 토큰 단위의 감독 신호 품질에 결정적인 역할을 한다는 점을 강조합니다. 이 연구는 향후 LLM의 효율적인 지속 학습 및 자기 개선(self-improvement) 파이프라인 구축에 있어, SFT, RL, 그리고 OPD를 결합하는 표준적인 방법론을 제시했다는 점에서 중요한 학술적·산업적 가치를 지닙니다.
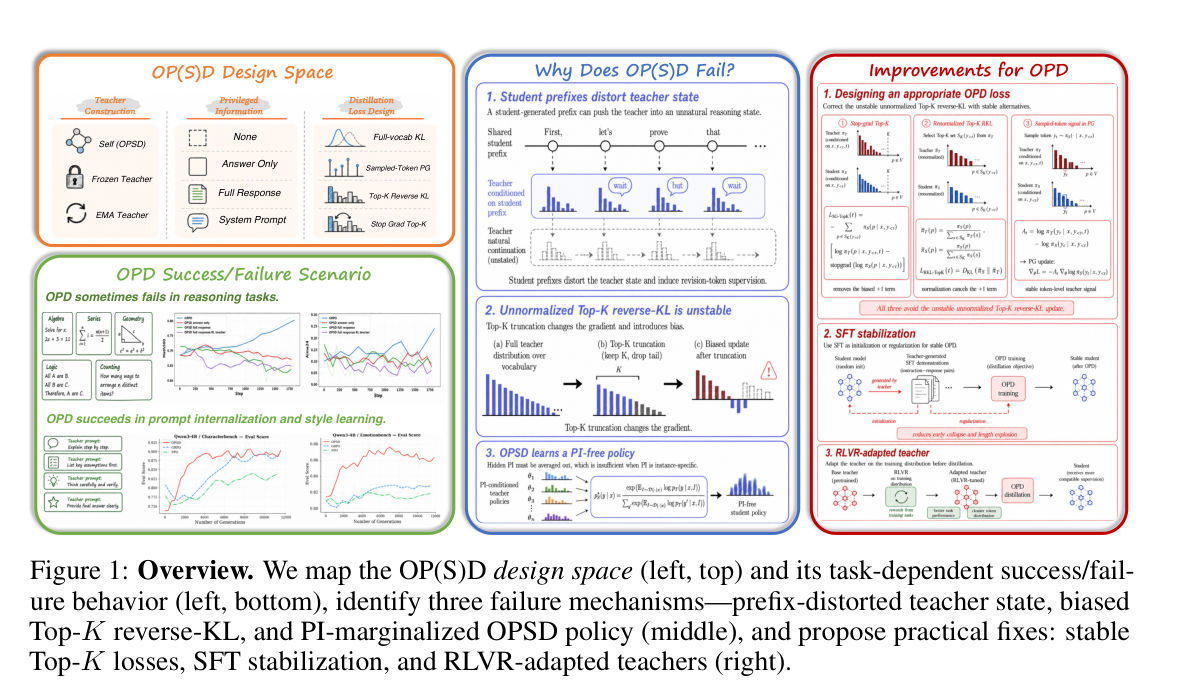
Figure 1 — 본 연구에서 다루는 OP(S)D의 전체적인 설계 공간과 실패 메커니즘을 요약한 핵심 다이어그램입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
- [논문리뷰] Trust Region On-Policy Distillation
- [논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
- [논문리뷰] MixSD: Mixed Contextual Self-Distillation for Knowledge Injection
- [논문리뷰] Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing
Review 의 다른글
- 이전글 [논문리뷰] RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
- 현재글 : [논문리뷰] The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes
- 다음글 [논문리뷰] WildRelight: A Real-World Benchmark and Physics-Guided Adaptation for Single-Image Relighting
댓글