[논문리뷰] RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
링크: 논문 PDF로 바로 열기
메타데이터
저자: Gaotang Li, Bhavana Dalvi Mishra, Zifeng Wang, Jun Yan, Yanfei Chen, Chun-Liang Li, Long T. Le, Rujun Han, George Lee, Hanghang Tong, Chen-Yu Lee, Tomas Pfister
1. Key Terms & Definitions
- Rubric: 에이전트의 작업 성공 여부를 판단하는 다차원적 평가 지표로, RubricEM에서는 단순히 결과 평가를 넘어 계획, 연구, 검토 등 작업 전 과정을 안내하는 공유 인터페이스로 활용됨.
- Structured Reasoning Scaffold: 작업을 Plan, Research, Review, Answer의 4단계로 구조화하여 에이전트의 long-horizon 추론을 안정화하는 프레임워크.
- SS-GRPO (Stage-Structured GRPO): 단계별 Rubric 기반 판단을 통해 보상을 산출하는 Reinforcement Learning 기법으로, 기존의 단일 터미널 보상보다 더 정교하고 밀도 있는 크레딧 할당(Credit Assignment)을 수행.
- Reflection Meta-Policy: 이전 작업에서 도출된 Rubric 기반의 성찰(Reflection)을 통해 향후 유사 작업의 성능을 향상시키는 공유 백본 모델.
2. Motivation & Problem Statement
본 논문은 Verifiable Reward(검증 가능한 보상)가 부재한 Open-ended 환경에서 Deep Research 에이전트를 효율적으로 학습시키는 문제를 해결하고자 한다. 기존의 Post-training 방식은 복잡한 long-horizon 작업에서 sparse한 보상으로 인해 효과적인 크레딧 할당이 어렵고, 과거의 경험을 재사용 가능한 지식으로 변환하는 메커니즘이 부족하다는 한계가 있다. 이에 저자들은 에이전트의 추론 구조를 명시화하고, 학습 전반에 걸쳐 Rubric을 공유 인터페이스로 사용하는 새로운 프레임워크를 제안한다 [Figure 1].
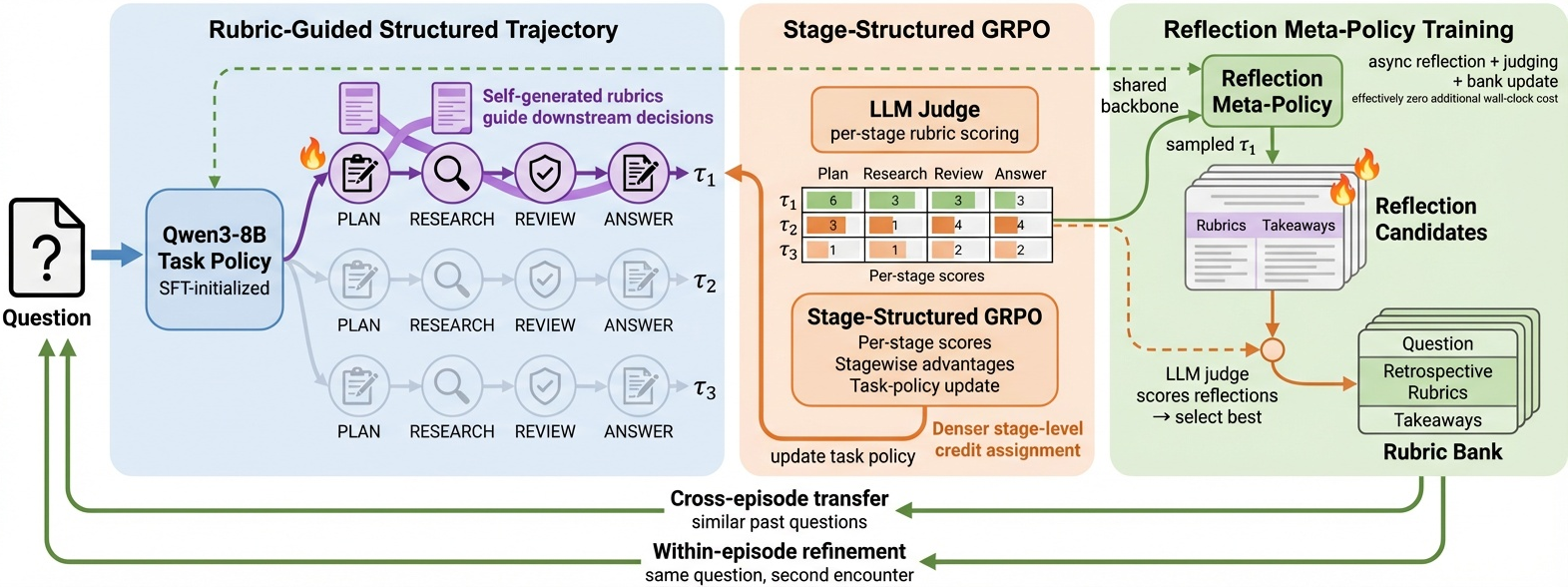
Figure 1 — RubricEM 전체 아키텍처
3. Method & Key Results
RubricEM은 크게 세 가지 핵심 구성 요소로 이루어진다. 첫째, Structured Reasoning Scaffold를 통해 에이전트가 작업 단계별로 스스로 Rubric을 생성하고 이에 따라 사고하도록 유도한다 [Figure 3]. 둘째, SS-GRPO를 활용하여 각 단계(Plan, Research, Review, Answer)별로 세분화된 보상을 계산함으로써 학습 신호를 밀도 있게 제공한다 [Figure 4]. 마지막으로, 공유 백본 기반의 Reflection Meta-Policy가 judged trajectory를 분석하여 재사용 가능한 Rubric-grounded 지식을 생성하고, 이를 Rubric Bank에 저장하여 향후 작업에 활용한다. 실험 결과, RubricEM-8B는 기존의 오픈 소스 모델들을 상회하는 성능을 기록했으며, 특히 1,400단계의 Reinforcement Learning만으로도 DR Tulu 대비 더 적은 학습 자원으로 높은 성과를 달성하였다 [Table 1]. 또한, 학습에 사용되지 않은 short-form 벤치마크에서도 일반화 성능이 우수함을 입증하였다 [Table 2].
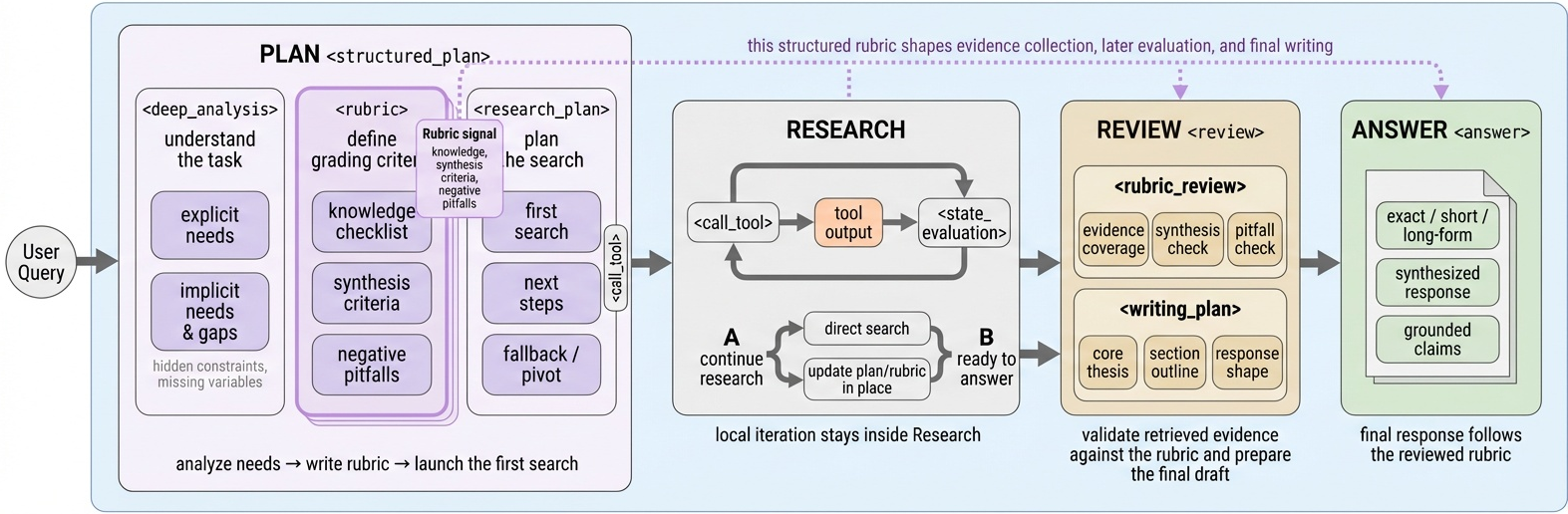
Figure 3 — 구조화된 추론 스캐폴드
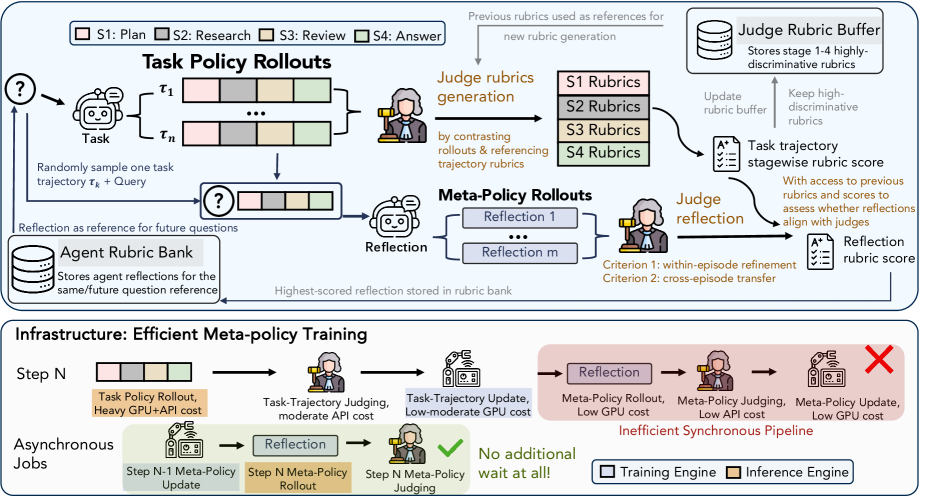
Figure 4 — RubricEM의 상세 RL 학습 파이프라인
4. Conclusion & Impact
RubricEM은 정답이 명확하지 않은 복잡한 연구 작업에서도 Reinforcement Learning이 효과적으로 작동할 수 있음을 입증하였다. 본 연구는 명시적인 단계 구조와 성찰 기반의 경험 재사용이 에이전트의 지능을 확장하는 데 핵심적인 역할을 함을 시사한다. 이러한 접근 방식은 향후 데이터 분석, 과학적 리뷰, 복잡한 워크플로우 자동화 등 정량적 검증이 어려운 다양한 분야로 확장되어 학계 및 산업계의 에이전트 학습 패러다임을 혁신할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Vision-DeepResearch: Incentivizing DeepResearch Capability in Multimodal Large Language Models
- [논문리뷰] Meta-RL Induces Exploration in Language Agents
- [논문리뷰] DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
- [논문리뷰] Tongyi DeepResearch Technical Report
- [논문리뷰] Open Data Synthesis For Deep Research
Review 의 다른글
- 이전글 [논문리뷰] MoCam: Unified Novel View Synthesis via Structured Denoising Dynamics
- 현재글 : [논문리뷰] RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
- 다음글 [논문리뷰] The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes
댓글