[논문리뷰] From Plans to Pixels: Learning to Plan and Orchestrate for Open-Ended Image Editing
링크: 논문 PDF로 바로 열기
저자: Anirudh Sundara Rajan, Krishna Kumar Singh, Yong Jae Lee
1. Key Terms & Definitions (핵심 용어 및 정의)
- Planner: 고차원적인 지시사항(high-level instruction)을 일련의 구조화된 atomic sub-tasks로 분해하는 MLLM 기반의 모델입니다.
- Orchestrator: Planner가 생성한 계획을 바탕으로, 적절한 편집 도구(tool)와 대상 영역(region)을 선택하여 실행하는 reward-driven 정책 모델입니다.
- Checklist-Guided Self-Training: 외부의 정답 데이터 없이도, Planner가 체크리스트 기반의 프롬프트를 사용하여 스스로 계획을 생성하고 이를 통해 학습하는 기법입니다.
- Experiential Learning Framework: 학습된 judge(VLM judge)로부터 도출된 실제 편집 결과에 대한 보상(outcome-based reward)을 통해 Orchestrator의 도구 선택 정책을 최적화하는 프레임워크입니다.
- Tool-Region Composition: Planner의 sub-tasks를 실행하기 위해 사용되는 분석 도구, 전체 이미지 편집기, 영역 기반 편집기 등을 조합하는 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Diffusion-based 이미지 편집 모델들은 "모자를 추가하라"와 같은 명확하고 구체적인 작업에는 우수한 성능을 보이지만, "광고를 채식주의자 친화적으로 바꾸라"와 같은 추상적이고 다단계의 장기적인(long-horizon) 지시사항을 처리하는 데에는 한계가 있습니다. 이러한 복잡한 작업은 단순히 한 번의 편집으로 해결될 수 없으며, 이미지 테마, 텍스트, 레이아웃 등 다양한 요소를 조화롭게 수정해야 합니다. 기존의 Agent-based 연구들은 수동으로 제작된 파이프라인이나 교사 모델 모방(teacher-imitation)에 의존하여 유연성이 떨어지고 실제 편집 결과와 학습 과정이 분리되어 있다는 문제가 있습니다 [Figure 1]. 따라서 저자들은 계획과 실행을 체계적으로 분리하고, 실제 편집의 성공적인 결과를 바탕으로 학습하는 새로운 프레임워크를 제안합니다.

Figure 1 — 복잡한 광고 편집 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Experiential Learning Framework를 통해 긴 호흡의 이미지 편집 작업을 수행합니다. 첫째, Planner는 체크리스트 기반의 프롬프트를 사용하여 추상적인 목표를 원자 단위의 sub-tasks로 구조화하며, 이 과정에서 Self-Supervised Fine-Tuning을 적용하여 모델의 자체 생성 분포를 최적화합니다 [Figure 2]. 둘째, Orchestrator는 Reward-Driven Tool Selection 정책을 통해 각 단계별로 가장 적합한 도구와 영역을 선택하며, VLM judge를 통해 피드백을 받아 정책을 개선합니다 [Figure 3]. 또한 효율적인 학습을 위해 Trajectory 보상을 하위 보상의 합으로 근사하는 기법을 사용합니다. 실험 결과, 본 제안 모델은 Instruction Following 지표에서 4.196점을 기록하여, 기존 FLUX.1-Kontext-dev(High-Level Instruction 기준 2.32) 및 Qwen-Image-Edit-2511(High-Level Instruction 기준 3.355) 대비 월등히 우수한 성능을 보였습니다 [Table 1]. 추가적인 정량적 평가인 GEdit 벤치마크에서도 Overall 7.604점을 획득하며 기존 sota 모델들을 상회하는 성능을 입증하였습니다 [Table 8].

Figure 2 — 체크리스트 기반 Planner
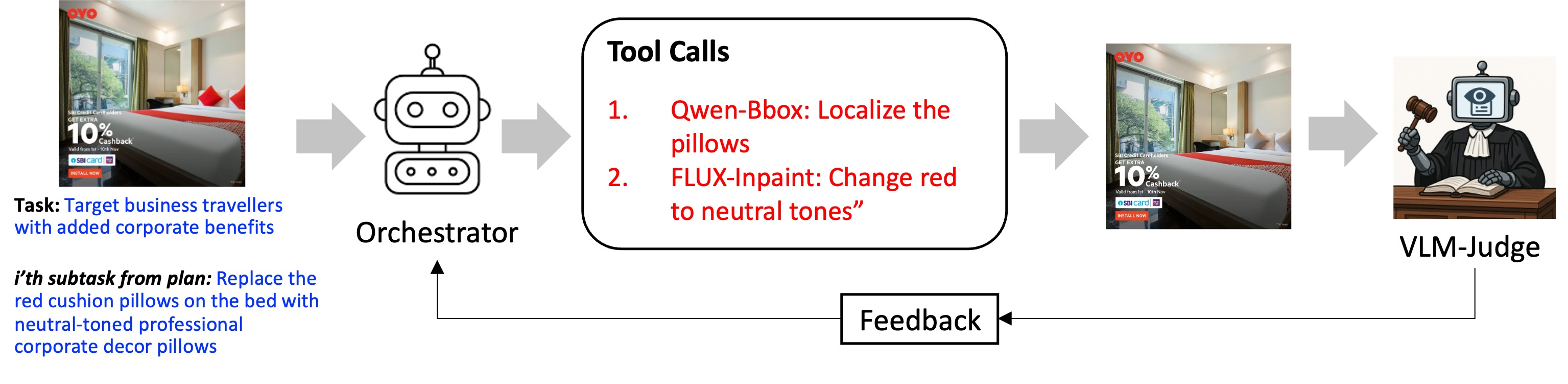
Figure 3 — 보상 기반 Orchestrator
4. Conclusion & Impact (결론 및 시사점)
본 논문은 추상적인 장기 이미지 편집 작업을 계획과 실행으로 분리하여 해결하는 Experiential Learning Framework를 성공적으로 제시하였습니다. 특히 체크리스트를 통한 계획의 구조화와 보상 기반의 오케스트레이션은 handcrafted rule 없이도 복잡한 다단계 편집을 가능하게 했습니다. 이 연구는 단순히 지시사항을 따라가는 편집을 넘어, 시각적 의도와 맥락을 이해하고 조화롭게 수정하는 AI 에이전트 개발에 큰 시사점을 줍니다. 결과적으로 학계와 산업계에서 복잡한 멀티모달 작업을 자동화하고 제어 가능한 고품질 이미지 생성 모델을 설계하는 데 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Text-Vision Co-Instructed Image Editing
- [논문리뷰] Is This Edit Correct? A Multi-Dimensional Benchmark for Reasoning-Aware Image Editing
- [논문리뷰] RewardFlow: Generate Images by Optimizing What You Reward
- [논문리뷰] DreamLite: A Lightweight On-Device Unified Model for Image Generation and Editing
- [논문리뷰] CARE-Edit: Condition-Aware Routing of Experts for Contextual Image Editing
Review 의 다른글
- 이전글 [논문리뷰] Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
- 현재글 : [논문리뷰] From Plans to Pixels: Learning to Plan and Orchestrate for Open-Ended Image Editing
- 다음글 [논문리뷰] GQLA: Group-Query Latent Attention for Hardware-Adaptive Large Language Model Decoding
댓글