[논문리뷰] GQLA: Group-Query Latent Attention for Hardware-Adaptive Large Language Model Decoding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Fanxu Meng
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLA (Multi-head Latent Attention): DeepSeek-V2/V3에서 사용된 주의 메커니즘으로, Key와 Value를 낮은 랭크의 latent로 압축하여 메모리 효율을 극대화합니다.
- GQLA (Group-Query Latent Attention): 본 논문이 제안하는 MLA의 변형으로, 동일한 가중치를 사용하여 하드웨어 특성에 따라 선택 가능한 두 가지 decoding 경로(MQA-absorb 및 GQA)를 제공합니다.
- Roofline Model: 하드웨어의 연산 능력(FLOPs)과 메모리 대역폭(BW)을 기준으로 알고리즘의 성능 한계와 최적 작동점을 분석하는 모델입니다.
- MQA-absorb path: GQLA의 decoding 경로 중 하나로, latent를 query와 output projection에 흡수시켜 H100과 같은 고성능 연산 장치에서 효율적인 메모리 사용을 가능하게 합니다.
- GQA path: GQLA의 또 다른 decoding 경로로, 그룹별로 확장된 cache를 사용하여 H20과 같이 연산 능력이 제한적인 장치에서 최적의 성능을 냅니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 MLA가 특정 하드웨어(예: NVIDIA H100)의 연산-대역폭 비율에 지나치게 종속되어 있다는 문제를 해결합니다. 기존 MLA는 오직 하나의 decoding 경로(MQA-absorb)만을 제공하여, H20처럼 연산 능력이 상대적으로 낮은 GPU에서는 성능이 심각하게 제한되는 '하드웨어 커플링' 문제가 발생합니다 [Figure 1]. 또한, 이 구조는 헤드 축을 따른 텐서 병렬화(Tensor Parallelism)를 저해하며, Multi-Token Prediction(MTP)과 같은 최신 기법 적용 시에도 성능 향상이 거의 없다는 한계가 있습니다. 따라서 하드웨어 상황에 유연하게 대응하면서도 retraining 없이 최적의 성능을 낼 수 있는 범용적인 모델 구조가 필요합니다.
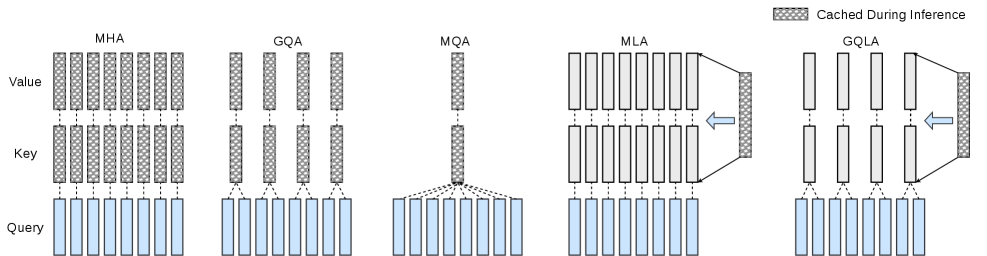
Figure 1 — MLA 및 GQLA 구조 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 기존 MLA의 latent 압축 구조를 유지하면서도, up-projection을 query head가 아닌 group 단위로 인덱싱하여 두 가지 decoding 경로를 동시에 노출하는 GQLA를 제안합니다 [Figure 2]. 제안 모델은 runtime 시 하드웨어 특성에 맞춰 MQA-absorb 경로와 GQA 경로 중 하나를 선택함으로써 retraining이나 커스텀 커널 없이 하드웨어별 최적화를 실현합니다. 실험 결과, H100 GPU에서 MQA-absorb 경로를 사용해 354K tokens/s의 성능을 달성하는 동시에, 동일한 가중치로 H20 GPU에서 GQA 경로를 선택하여 221K tokens/s라는 성능을 확보했습니다 [Table 2]. 이는 기존 MLA가 H20에서 고정된 경로로 인해 약 65K tokens/s에 머물렀던 것과 비교하여 3.4배의 처리량 개선을 달성한 것입니다 [Table 2]. 또한, TransGQLA 파이프라인을 통해 LLaMA-3-8B 기반의 GQA 모델을 단 0-token 변환만으로 성공적으로 이식하여 기존 대비 약 71.875%의 KV-cache 압축률을 달성했습니다 [Table 3].
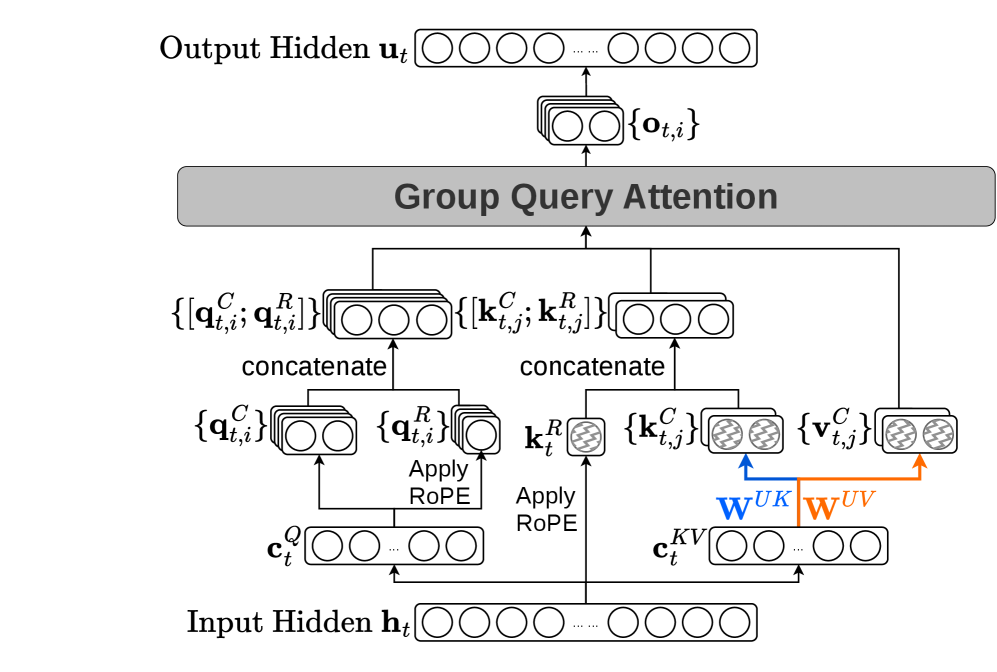
Figure 2 — GQLA의 두 decoding 경로
4. Conclusion & Impact (결론 및 시사점)
본 논문은 동일한 가중치로 하드웨어별 최적화된 decoding 경로를 제공하는 GQLA를 통해 LLM 추론의 하드웨어 종속성 문제를 해결합니다. 이 연구는 대규모 모델 배포 시 하드웨어 인프라 구성에 관계없이 단일 모델 가중치로 최대 처리량을 확보할 수 있게 함으로써 학계와 산업계의 추론 비용 절감에 기여합니다. 특히, 고성능 플래그십 GPU뿐만 아니라 범용 inference accelerator에서도 최상의 효율을 끌어낼 수 있는 아키텍처 원칙을 제시했다는 점에서 중요한 시사점을 가집니다. 향후 다양한 모델 크기와 도메인으로의 확장을 통해 하드웨어 적응형 AI 추론 생태계에 큰 영향을 미칠 것으로 기대됩니다.
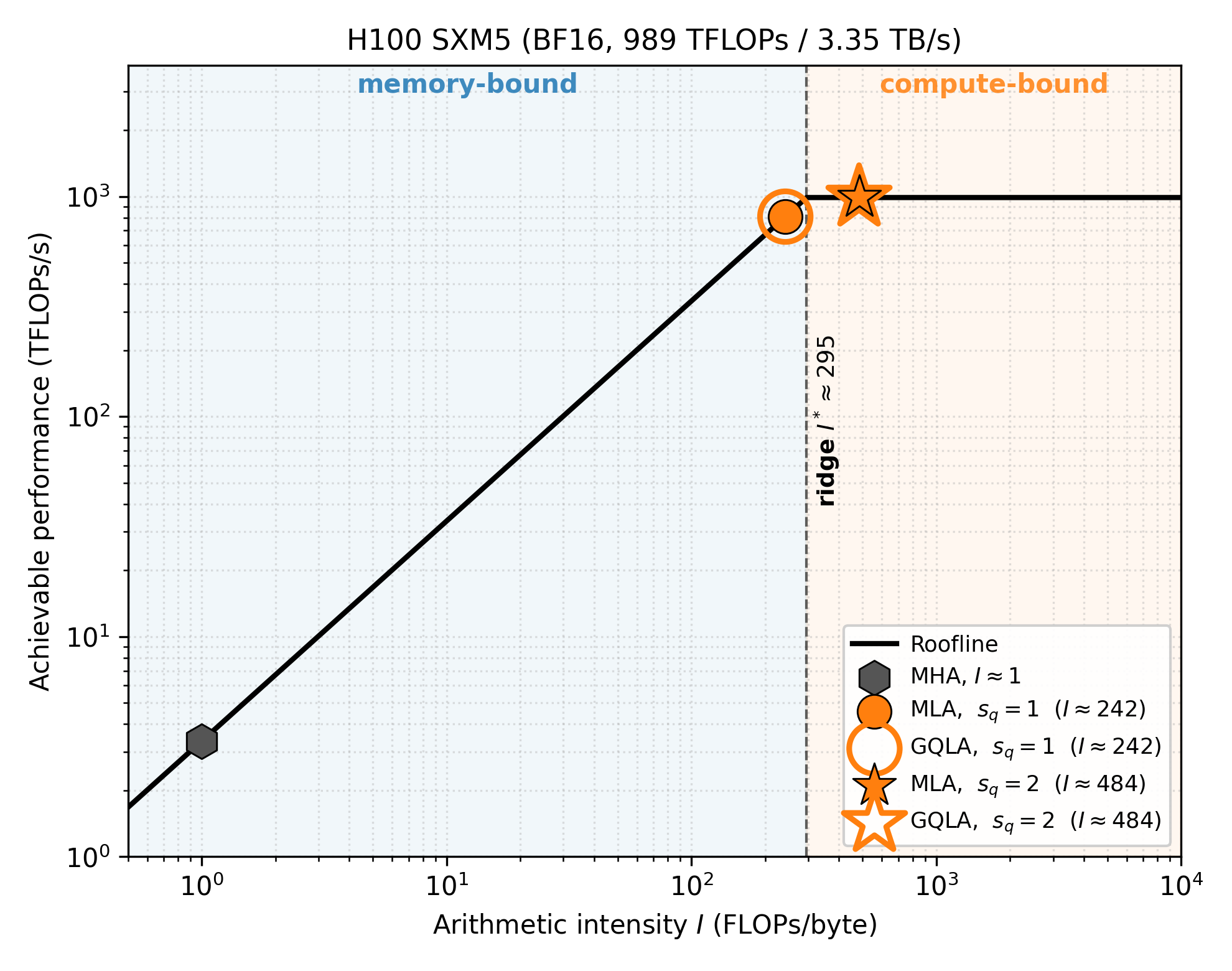
Figure 3 — H100/H20 Roofline 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
- [논문리뷰] DOPD: Dual On-policy Distillation
- [논문리뷰] AsyncOPD: How Stale Can On-Policy Distillation Be?
- [논문리뷰] Why Muon Outperforms Adam: A Curvature Perspective
- [논문리뷰] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
Review 의 다른글
- 이전글 [논문리뷰] From Plans to Pixels: Learning to Plan and Orchestrate for Open-Ended Image Editing
- 현재글 : [논문리뷰] GQLA: Group-Query Latent Attention for Hardware-Adaptive Large Language Model Decoding
- 다음글 [논문리뷰] HodgeCover: Higher-Order Topological Coverage Drives Compression of Sparse Mixture-of-Experts
댓글