[논문리뷰] PlayCoder: Making LLM-Generated GUI Code Playable
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhiyuan Peng, Wei Tao, Xin Yin, Chenhao Ying, Yuan Luo, Yiwen Guo
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- PlayEval: GUI 애플리케이션(게임 포함)의 코드 생성 성능을 평가하기 위해 저자들이 구축한 리포지토리 인식(repository-aware) 벤치마크 데이터셋입니다.
- Play@k: 단순히 컴파일이나 유닛 테스트 통과 여부가 아닌, 생성된 코드가 실제 실행 환경에서 사용자 상호작용을 통해 논리적 오류 없이 End-to-End로 작동하는지를 평가하는 행동적 정확도 지표입니다.
- PlayTester: 시각적 피드백(스크린샷)과 동적 GUI 상호작용을 사용하여 생성된 애플리케이션의 행동을 검증하고, 논리적 결함을 식별하는 자동화된 테스트 에이전트입니다.
- PlayCoder: 리포지토리 인식 기능을 갖춘 PlayDeveloper와 행동 피드백 기반의 자동 프로그램 복구(APR) 에이전트인 PlayRefiner로 구성된 다중 에이전트 프레임워크입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 코드 생성 벤치마크가 GUI 애플리케이션의 복잡하고 상호작용적인 행동을 제대로 평가하지 못하는 문제를 해결하고자 합니다. GUI 애플리케이션은 이벤트 기반 제어 흐름과 지속적인 상태 변화를 포함하지만, 현재의 Pass@k 평가는 주로 유닛 테스트에 의존하여 "행동적 결함(silent behavioral failures)"을 감지하지 못합니다. 예를 들어, 컴파일은 성공하지만 게임 내 충돌 탐지 로직이 깨져서 발생하는 치명적인 논리 오류를 전통적인 단위 테스트로는 잡아낼 수 없습니다 [Figure 1]. 따라서 저자들은 GUI의 동적이고 상태 의존적인 요구사항을 검증할 수 있는 새로운 벤치마크와 프레임워크의 필요성을 제기합니다.
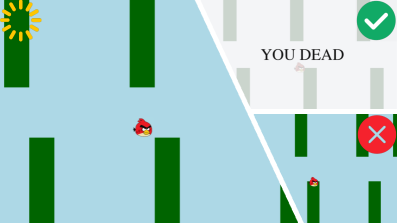
Figure 1 — GUI 코드 생성 시 발생하는 논리 오류 예시
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 GUI 행동의 정확성을 검증하고 이를 기반으로 코드를 반복적으로 수정하는 다중 에이전트 프레임워크인 PlayCoder를 제안합니다 [Figure 4]. PlayDeveloper는 리포지토리 문맥을 활용하여 초기 코드를 생성하고, PlayTester는 GUI를 직접 실행하며 시각적/기능적 결함을 진단합니다. 진단 결과를 바탕으로 PlayRefiner는 단계적인 코드 수정을 수행하여 행동적 정확성을 확보합니다. 실험 결과, PlayCoder는 기존의 최고 성능 Baseline(DeepCode) 대비 Exec@3 성능을 최대 20.2%p, Play@3 성능을 최대 11.0%p 향상시키는 성과를 거두었습니다. 구체적으로 Claude-Sonnet-4 모델 기반 환경에서 PlayCoder는 36.8% Exec@3 및 20.3% Play@3를 기록하며 높은 기능적 정확성을 입증하였습니다 [Table 3].
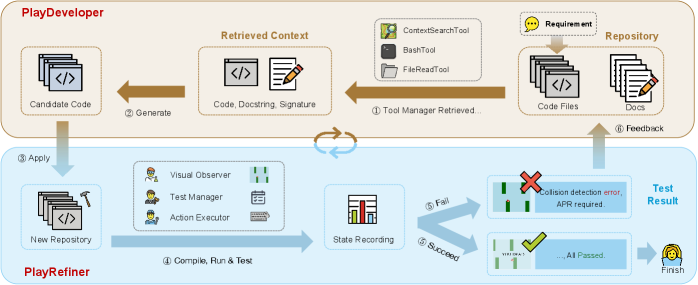
Figure 4 — PlayCoder의 전체 아키텍처
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 GUI 애플리케이션 생성의 핵심은 컴파일 성공이 아닌 행동적 정확도(behavioral fidelity)에 있음을 확인하고 이를 달성하기 위한 구체적인 방법론을 정립했습니다. PlayCoder 프레임워크는 자동화된 GUI 행동 테스트와 프로그램 복구를 통합함으로써 기존 LLM 기반 방법론의 한계인 '행동적 환각'을 효과적으로 완화했습니다. 이 연구는 복잡한 소프트웨어 엔지니어링 환경에서 모델의 코딩 능력을 넘어선 실제 '기능적 검증'의 중요성을 부각시켰으며, 향후 인터랙티브 시스템의 자동화된 개발에 중대한 이정표를 제시합니다.
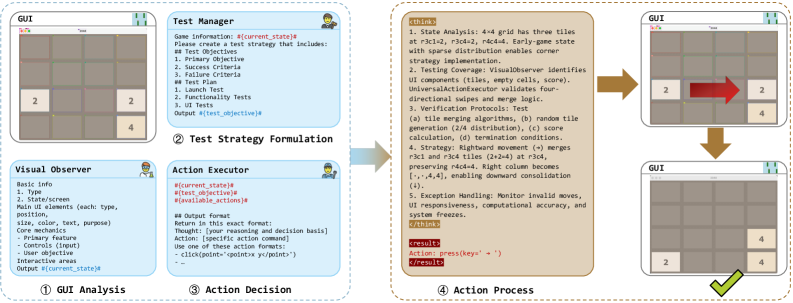
Figure 5 — 2048 게임에 대한 PlayCoder의 테스트 예시
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From Runnable to Shippable: Multi-Agent Test-Driven Development for Generating Full-Stack Web Applications from Requirements
- [논문리뷰] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
- [논문리뷰] Do Coding Agents Deceive Us? Detecting and Preventing Cheating via Capped Evaluation with Randomized Tests
- [논문리뷰] Why Muon Outperforms Adam: A Curvature Perspective
- [논문리뷰] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
Review 의 다른글
- 이전글 [논문리뷰] MoVE: Translating Laughter and Tears via Mixture of Vocalization Experts in Speech-to-Speech Translation
- 현재글 : [논문리뷰] PlayCoder: Making LLM-Generated GUI Code Playable
- 다음글 [논문리뷰] ShadowPEFT: Shadow Network for Parameter-Efficient Fine-Tuning
댓글