[논문리뷰] MoVE: Translating Laughter and Tears via Mixture of Vocalization Experts in Speech-to-Speech Translation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Szu-Chi Chen, I-Ning Tsai, Yi-Cheng Lin, Sung-Feng Huang, Hung-yi Lee
1. Key Terms & Definitions (핵심 용어 및 정의)
- S2ST (Speech-to-Speech Translation): ASR, MT, TTS를 통합하여 언어 간 음성을 직접 변환하는 기술.
- NVs (Non-verbal Vocalizations): 웃음이나 울음과 같이 언어적 내용을 넘어 감정적 의도를 전달하는 비언어적 발성.
- AudioLLMs: 음성 및 텍스트를 처리하도록 대규모 사전 학습된 생성형 인공지능 모델.
- MoE (Mixture of Experts): 복잡한 태스크를 여러 전문 모듈(Experts)로 분할하여 효율적으로 처리하는 아키텍처.
- LoRA (Low-Rank Adaptation): 대규모 모델의 파라미터를 고정한 채 경량 어댑터만을 학습시키는 효율적인 파인튜닝 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 S2ST 시스템이 의미론적 정확도는 높으나, 웃음이나 울음 같은 NVs를 보존하지 못해 실질적인 대화의 정서적 맥락을 상실하는 문제를 해결한다. 기존 시스템들은 고품질 NVs 데이터의 부족과, 복잡한 다중 감정 상태를 처리하기 어려운 모델 구조적 한계로 인해 표현력이 부족하다. 특히 파라미터 공유 환경에서 서로 충돌하는 감정 정보가 상호 간섭을 일으키는 것이 주요 장애물이다. 이러한 문제를 극복하기 위해 저자들은 확장 가능한 데이터 합성 파이프라인과 감정 특화형 아키텍처인 MoVE를 제안한다 [Figure 1].
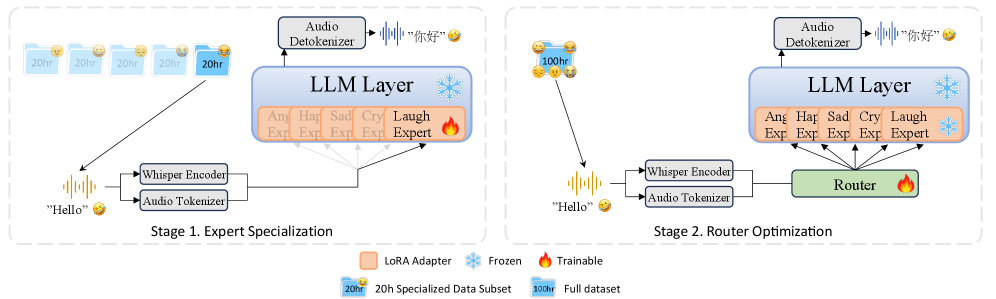
Figure 1 — MoVE 2단계 학습 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 AudioLLM을 기반으로 Mixture-of-LoRA-Experts 구조를 도입하여 표현력을 극대화한 MoVE 프레임워크를 제안한다. 제안 방법론은 5개의 독립적인 LoRA 어댑터(Happy, Sad, Angry, Laughing, Crying)를 병렬로 배치하고, 토큰 단위로 감정 비중을 동적으로 조절하는 Dynamic Soft-Weighting Router를 활용하여 하이브리드 감정 상태를 정교하게 생성한다. 실험 결과, MoVE는 English-Chinese S2ST 태스크에서 NVs 재현율 76%를 기록하며 기존 시스템(최대 14%)을 압도했다 [Table 1]. 또한, 단 30분의 정제된 데이터만으로도 전체 데이터 학습 대비 95% 수준의 정서적 충실도(Emotional Fidelity)를 달성하는 우수한 데이터 효율성을 입증했다. 라우터 분석 결과, 모델은 감정 레이블 없이도 문맥과 음성 단서만으로 감정 상태를 자율적으로 disentangle하는 능력을 보여주었다 [Figure 3].
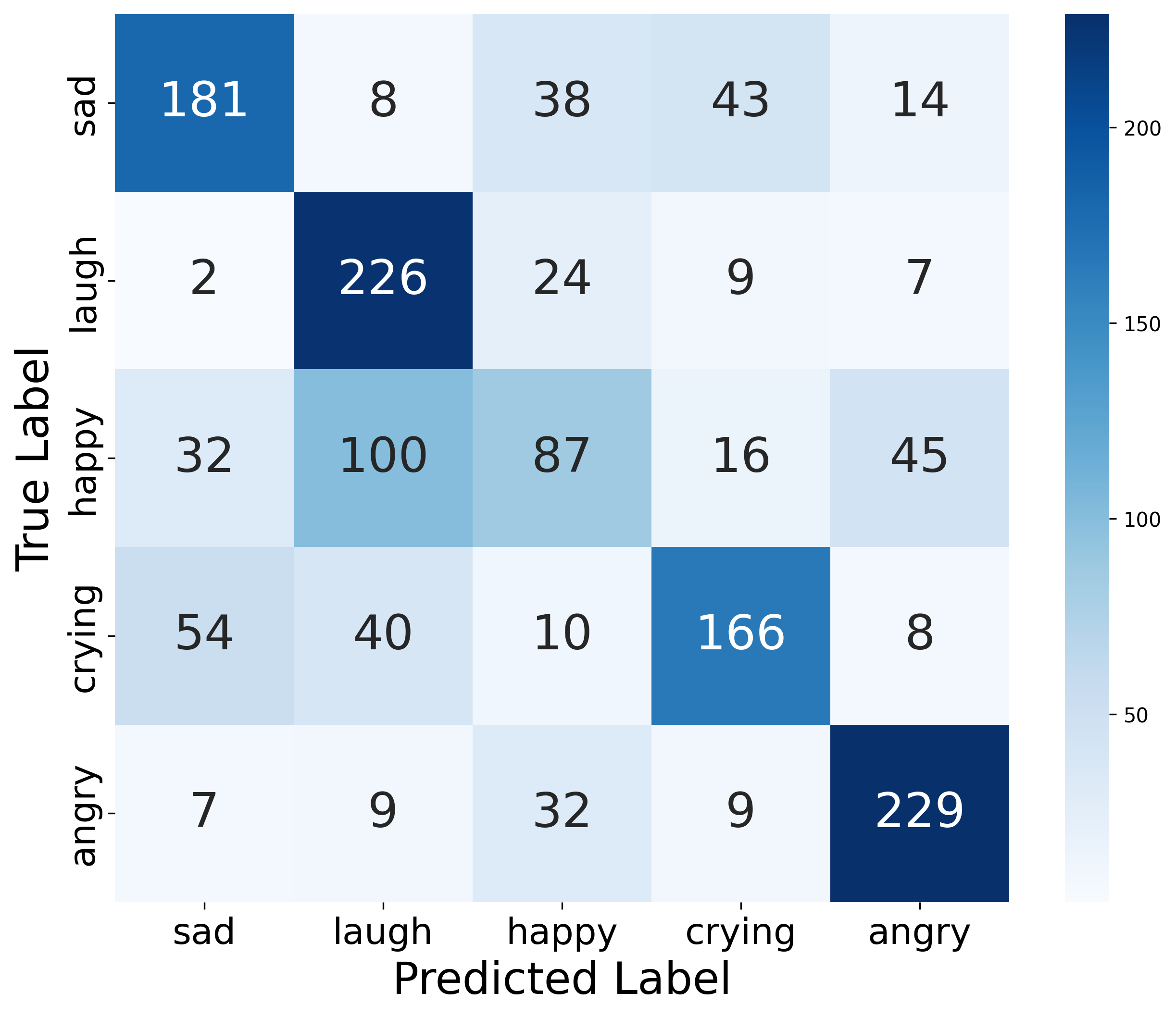
Figure 3 — 라우터 동작 혼동 행렬
4. Conclusion & Impact (결론 및 시사점)
본 논문은 AudioLLM의 잠재력을 최대한 이끌어내어 S2ST 분야에서 감정 보존 및 표현 성능의 획기적인 발전을 이루어냈다. 저자들이 제안한 데이터 합성 파이프라인과 MoVE 구조는 기존 시스템의 한계를 효과적으로 극복하며, 향후 실시간 통번역 서비스의 실재감과 정서적 교감을 크게 향상할 것으로 기대된다. 특히 사전 학습된 foundation 모델의 지식을 효율적으로 활용하는 접근 방식은 데이터 효율성 측면에서 학계와 산업계에 중요한 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Decoupled Residual Denoising Diffusion Models for Unified and Data Efficient Image-to-Image Translation
- [논문리뷰] RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
- [논문리뷰] MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference
- [논문리뷰] CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
- [논문리뷰] On Token's Dilemma: Dynamic MoE with Drift-Aware Token Assignment for Continual Learning of Large Vision Language Models
Review 의 다른글
- 이전글 [논문리뷰] Mind's Eye: A Benchmark of Visual Abstraction, Transformation and Composition for Multimodal LLMs
- 현재글 : [논문리뷰] MoVE: Translating Laughter and Tears via Mixture of Vocalization Experts in Speech-to-Speech Translation
- 다음글 [논문리뷰] PlayCoder: Making LLM-Generated GUI Code Playable
댓글