[논문리뷰] Mind's Eye: A Benchmark of Visual Abstraction, Transformation and Composition for Multimodal LLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Rohit Sinha, Aditya Kanade, Sai Srinivas Kancheti, Vineeth N Balasubramanian, Tanuja Ganu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Mind’s Eye: 본 연구에서 제안하는 8개의 visuo-cognitive 작업으로 구성된 multiple-choice 벤치마크입니다.
- ART Taxonomy: fluid intelligence의 구성 요소인 Abstraction, Relation, Transformation의 약자로, 시각적 추론 능력을 평가하기 위한 분류 체계입니다.
- Visuospatial Reasoning: 시각적 정보를 사용하여 멘탈 시뮬레이션, 회전, 조립 등 공간적 조작을 수행하는 고차원 인지 능력입니다.
- Diagnostic Distractors: 모델의 특정 추론 오류 유형(예: 미러링 오류, 패리티 실수)을 진단하기 위해 의도적으로 설계된 오답 선택지입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 Multimodal Large Language Models (MLLMs)가 객체 인식이나 장면 묘사와 같은 표면적 시각 인지에서는 뛰어난 성과를 보이나, 인간의 핵심 인지 능력인 visuo-cognitive 및 visuospatial reasoning 역량은 여전히 부족하다는 문제의식에서 출발합니다. 기존 벤치마크들은 주로 일반적인 Visual QA에 치중되어 있거나, 인지적 심리학 기반의 멘탈 시뮬레이션(mental rotation, paper folding 등)을 체계적으로 측정하지 못한다는 한계가 있습니다. 또한, 많은 연구가 시각적 증거와 언어적 사전 지식을 혼동하여 모델의 진정한 시각적 추론 능력을 분리해내지 못합니다. 이에 저자들은 인지 심리학에 기반하여 visuospatial transformation을 분리하고 체계적으로 평가할 수 있는 새로운 벤치마크인 Mind’s Eye를 제안합니다 [Figure 1].
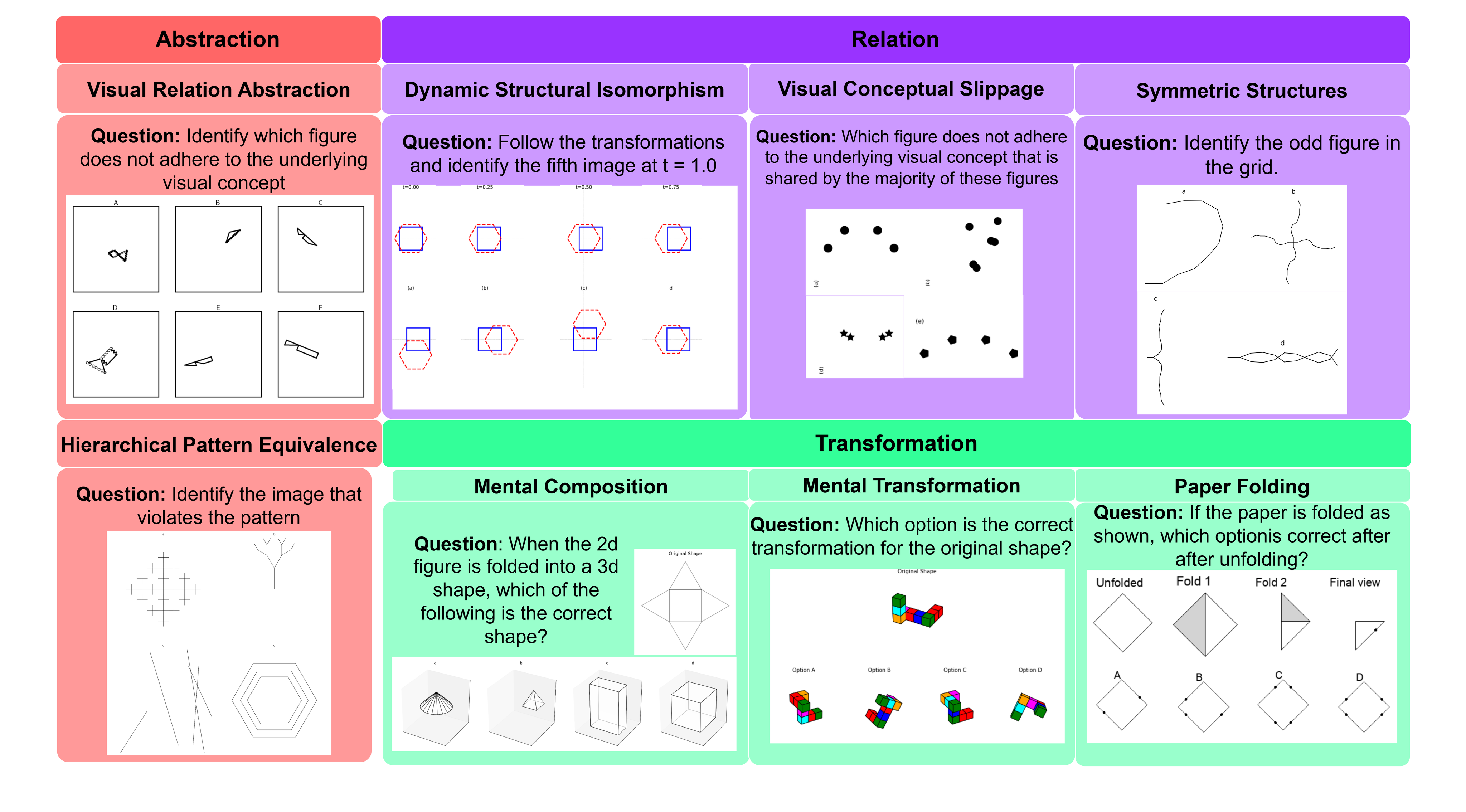
Figure 1 — Mind's Eye 벤치마크 8개 작업 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Carroll의 fluid intelligence 이론을 바탕으로 한 ART (Abstraction–Relation–Transformation) 분류 체계를 정의하고, 이를 기반으로 8개의 visuo-cognitive 작업을 programmatically generate하여 벤치마크를 구축했습니다. 각 작업은 언어적 편향을 최소화하기 위해 SVG 형식의 합성 데이터를 사용하였으며, 추론 오류를 세밀하게 분석할 수 있는 진단용 distractor가 포함되어 있습니다. 실험 결과, 인간 피험자는 전체 평균 80%의 높은 정확도를 기록한 반면, 18개의 최신 MLLM(closed-source 및 open-source 포함)은 모두 50% 미만의 정확도를 보여 큰 성능 격차를 확인했습니다 [Table 2]. 특히, 어려운 문제일수록 정확도가 급격히 떨어지는 인간과 달리, MLLM은 난이도와 상관없이 성능이 평탄하게 낮은 분포를 보여 기초적인 visuo-cognitive 연산이 결여되어 있음을 시사합니다 [Figure 3]. 또한, Chain-of-Thought (CoT)를 포함한 다양한 prompting 전략은 Abstraction 작업에는 다소 도움을 주었으나, 멘탈 시뮬레이션을 요하는 Transformation 작업에서는 오히려 성능을 저하시키는 dimension-dependent한 효과를 나타냈습니다 [Figure 2].
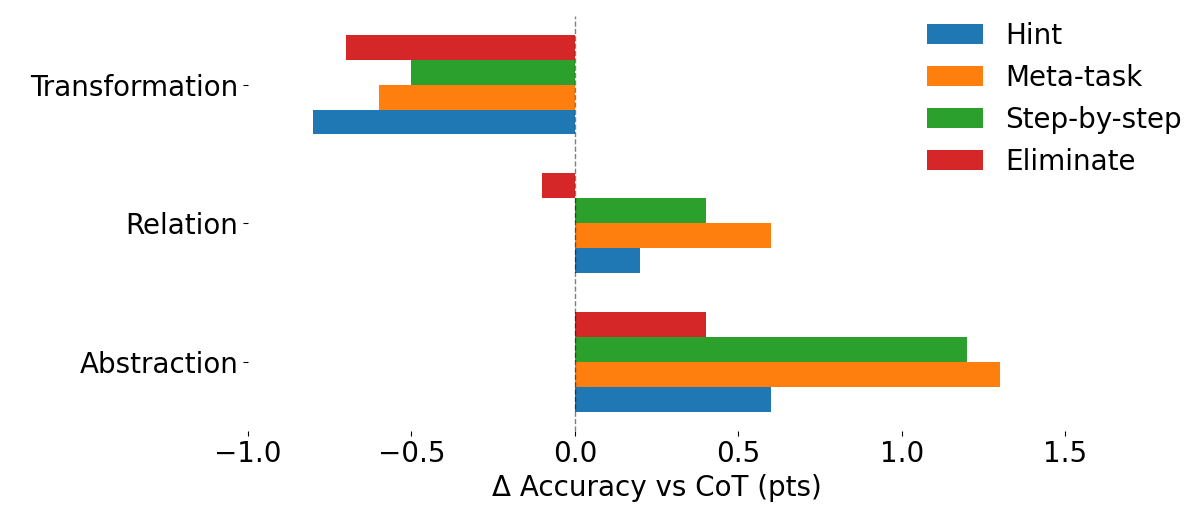
Figure 2 — 프롬프트 변화에 따른 성능 차이(Δ Accuracy)
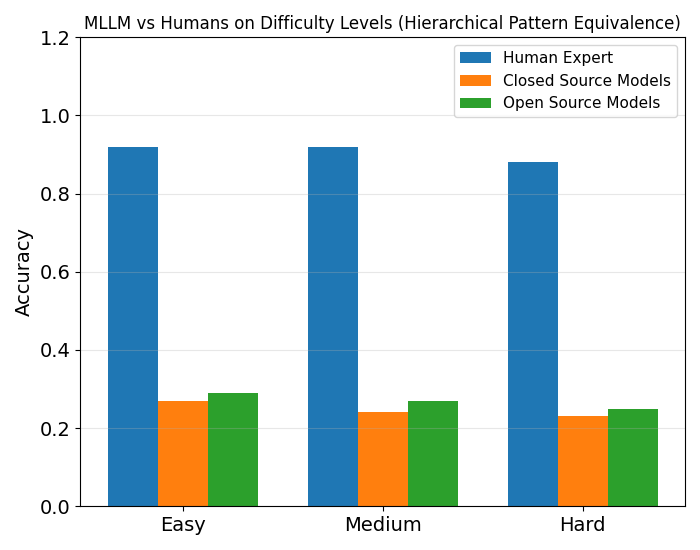
Figure 3 — 난이도별 인간-모델 성능 격차(HPE)
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MLLMs가 시각적 정보를 localize하는 데는 성공할지라도, 해당 정보를 바탕으로 신뢰성 있는 인지적 추론을 수행하는 능력이 현저히 부족함을 입증했습니다. 연구진은 성능 향상을 위해 단순히 모델 크기를 키우거나 데이터를 늘리는 것보다, grounded attention, 공간적 작업 기억(spatial working memory), transformation-aware 표현 학습과 같은 구조적 혁신이 필요하다고 제안합니다. 이 벤치마크는 학계가 일반적인 지능을 넘어 인간 수준의 visuospatial reasoning 능력을 갖춘 AI 시스템을 개발하는 데 중요한 평가 도구로 활용될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OVO-S-Bench: A Hierarchical Benchmark for Streaming Spatial Intelligence in Multimodal LLMs
- [논문리뷰] HakushoBench: A Japanese Chart and Table VQA Benchmark from Governmental White Papers
- [논문리뷰] Toward Native Multimodal Modeling: A Roadmap
- [논문리뷰] OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understanding
- [논문리뷰] Reading, Not Thinking: Understanding and Bridging the Modality Gap When Text Becomes Pixels in Multimodal LLMs
Review 의 다른글
- 이전글 [논문리뷰] MM-JudgeBias: A Benchmark for Evaluating Compositional Biases in MLLM-as-a-Judge
- 현재글 : [논문리뷰] Mind's Eye: A Benchmark of Visual Abstraction, Transformation and Composition for Multimodal LLMs
- 다음글 [논문리뷰] MoVE: Translating Laughter and Tears via Mixture of Vocalization Experts in Speech-to-Speech Translation
댓글