[논문리뷰] MM-JudgeBias: A Benchmark for Evaluating Compositional Biases in MLLM-as-a-Judge
링크: 논문 PDF로 바로 열기
저자: Sua Lee, Sanghee Park, Jinbae Im
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLM-as-a-Judge: MLLM을 활용하여 multimodal 생성물의 품질을 자동으로 평가하는 패러다임.
- Compositional Bias: query, image, response로 구성된 복합적 평가 맥락에서 각 구성 요소를 통합하지 못하고 부분적이거나 편향된 정보에 의존하는 현상.
- Bias-Deviation (BD): semantically disruptive한 perturbance(모달리티 제거, 불일치)에 대한 모델의 민감도를 측정하는 지표.
- Bias-Conformity (BC): semantically preserving한 perturbance(단순 변환, 중복 설명)에 대한 모델의 판단 안정성을 측정하는 지표.
- Integrality, Congruity, Robustness: MM-JudgeBias 벤치마크가 정의한 편향의 3대 핵심 차원.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 MLLM을 평가자로 사용하는 시스템에서 발생하는 Compositional Bias의 심각성과 이에 대한 신뢰성 검증의 부재를 해결하고자 한다. MLLM은 시각 정보와 텍스트 정보를 통합적으로 판단해야 하지만, 실제로는 특정 모달리티에 과도하게 의존하거나 잘못된 근거를 바탕으로 평가를 내리는 등 체계적인 모달리티 편향을 보인다. 기존 벤치마크들은 대부분 텍스트 기반의 LLM-as-a-Judge 편향만을 다루고 있어, multimodal 맥락에서의 종합적인 판단 능력과 견고성을 검증하는 데 한계가 있다. 이에 저자들은 평가 과정에서의 논리적 무결성(verification integrity)을 객관적으로 측정할 수 있는 통합 프레임워크인 MM-JudgeBias를 제안한다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 29개의 기존 데이터셋에서 추출한 1,804개의 샘플을 바탕으로 9가지 유형의 편향을 분석하는 MM-JudgeBias 벤치마크를 구축하였다. 제안된 프레임워크는 각 샘플에 대해 편향되지 않은(unbiased) triplet과 편향을 주입한(biased) triplet을 생성하여 평가 결과의 차이를 비교한다. 실험 결과, 26개의 최신 MLLM들은 공통적으로 Integrality 관련 편향에 취약함을 드러냈으며, 특히 모델의 크기나 일반적인 추론 능력이 반드시 높은 판단 신뢰성으로 직결되지는 않음이 확인되었다 [Table 2]. 특히, Response-Dominance와 같은 시나리오에서 많은 모델이 이미지를 완전히 제거했음에도 높은 점수를 유지하는 등 심각한 모달리티 무시 현상을 보였다. 또한, Modality Constraints나 Modality Reasoning과 같은 체계적인 프롬프트 전략이 판단의 일관성을 개선할 수 있음을 입증하였으나, 여전히 robustness 측면에서는 모델별로 복합적인 성능 트레이드오프가 존재한다 [Table 16].
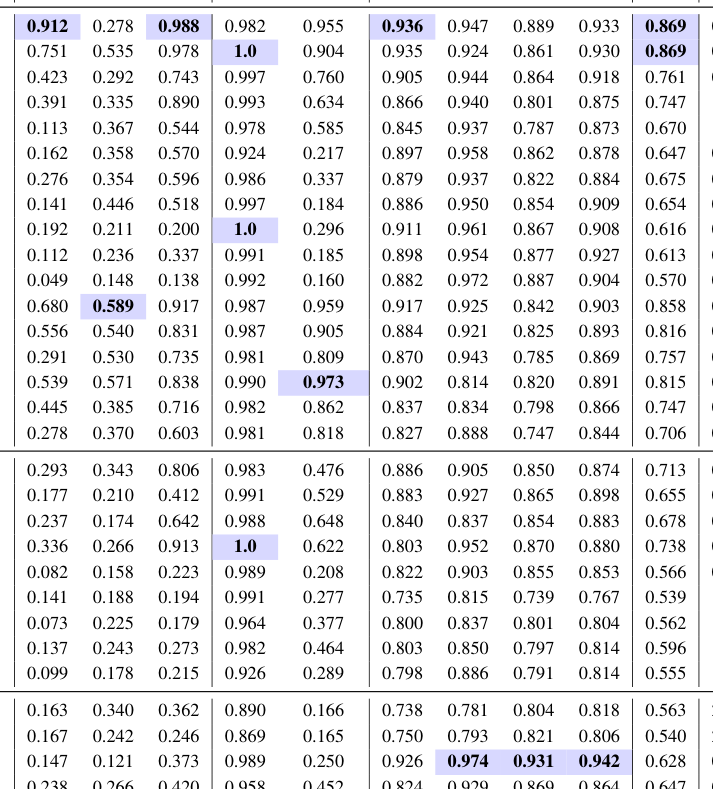
Table 2 — 제안한 벤치마크에 대한 26개 모델의 실험 결과(BD, BC 지표 포함)를 보여주는 핵심 테이블
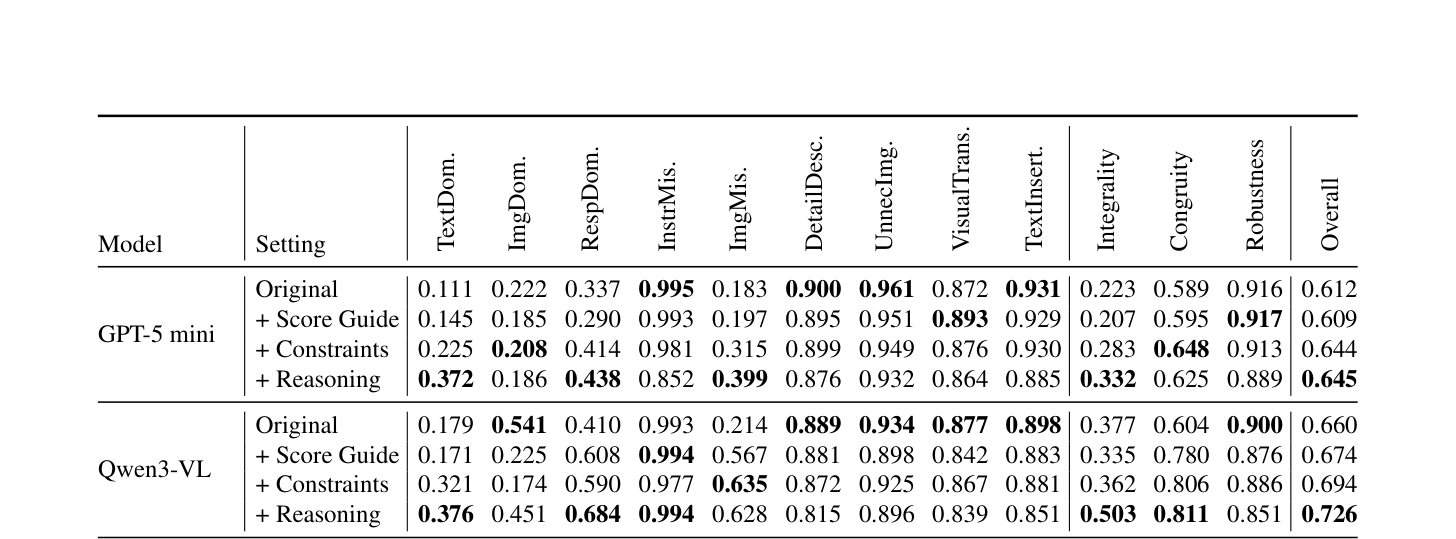
Table 16 — 다양한 프롬프트 전략을 적용했을 때의 모델별 성능 개선 효과를 비교한 결과
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 현대의 고성능 multimodal 모델조차 종합적인 판단을 수행하는 과정에서 본질적인 Compositional Bias를 가지고 있음을 체계적으로 규명하였다. 연구 결과는 단순한 모델 크기 확장만으로는 judgment reliability를 보장할 수 없음을 시사하며, 평가자의 판단 과정을 제어할 수 있는 구조화된 프롬프트와 specialized critic 모델의 필요성을 강조한다. 본 벤치마크는 향후 신뢰할 수 있는 MLLM-as-a-Judge 평가 시스템 개발을 위한 기초 지표로서, multimodal AI 모델의 검증 분야에 중요한 방향성을 제시한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Benchmarking Visual State Tracking in Multimodal Video Understanding
- [논문리뷰] Omni-DuplexEval: Evaluating Real-time Duplex Omni-modal Interaction
- [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- [논문리뷰] Exploring Spatial Intelligence from a Generative Perspective
- [논문리뷰] Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Review 의 다른글
- 이전글 [논문리뷰] LoopCTR: Unlocking the Loop Scaling Power for Click-Through Rate Prediction
- 현재글 : [논문리뷰] MM-JudgeBias: A Benchmark for Evaluating Compositional Biases in MLLM-as-a-Judge
- 다음글 [논문리뷰] Mind's Eye: A Benchmark of Visual Abstraction, Transformation and Composition for Multimodal LLMs
댓글