[논문리뷰] ShadowPEFT: Shadow Network for Parameter-Efficient Fine-Tuning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xianming Li, Zongxi Li, Tsz-fung Andrew Lee, Jing Li, Haoran Xie, Qing Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- ShadowPEFT: frozen backbone에 중앙 집중식 shadow network를 결합하여 layer-level에서 task-specific refinement를 수행하는 PEFT 프레임워크.
- Shadow State: Transformer 각 layer의 base hidden state와 평행하게 진화하며, 다음 layer로 정보를 전달하는 task-adaptive reference trajectory.
- Detached Shadow Mode: base model 없이 shadow module만 독립적으로 inference에 사용하여 경량화된 배포를 가능하게 하는 배포 모드.
- Gated Residual Update: 이전 layer의 shadow state와 현재 base output 사이의 정보를 조절하여 shadow state를 업데이트하는 GRU 기반의 메커니즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 LoRA 스타일의 PEFT 방식이 가진 파편화된 적응(fragmented adaptation) 구조를 극복하기 위해 ShadowPEFT를 제안한다. 기존 연구들은 개별적인 linear layer마다 독립적인 low-rank perturbation을 삽입하여 적응을 수행하므로, layer 간 명시적인 정보 공유가 부족하고 backbone과의 구조적 결합도가 높다는 한계가 있다. 이러한 방식은 고정된 backbone 내부의 weight 구조에 강하게 종속되어 모듈러 배포나 경량화된 엣지 컴퓨팅 환경에서의 활용이 어렵다 [Figure 1]. 따라서 본 연구는 layer-level에서 통합적으로 동작하는, 독립적으로 재사용 가능한 중앙 집중식 adaptation 메커니즘을 탐구하고자 한다.
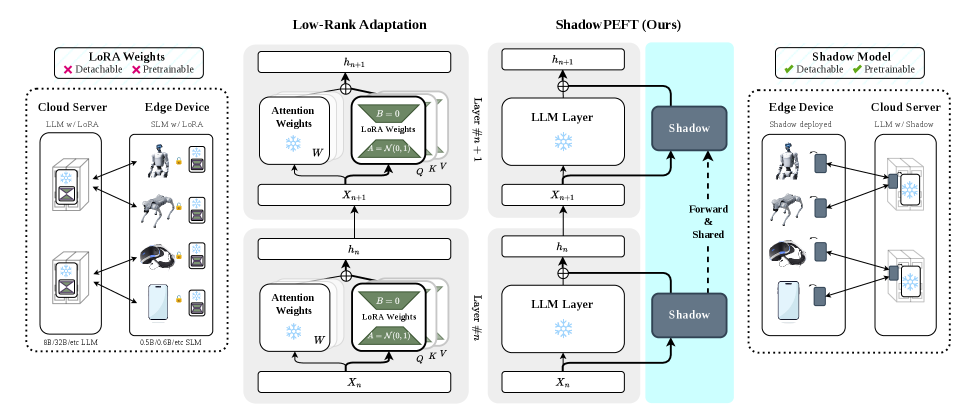
Figure 1 — 기존 LoRA와 ShadowPEFT 아키텍처 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 frozen backbone에 Shadow Injection Module과 Shadow Update Module을 결합한 중앙 집중식 shadow network를 제안하여, 고정된 backbone hidden state를 layer 단위에서 점진적으로 정교화한다 [Figure 2]. Shadow Injection Module은 base-shadow 간의 차이(discrepancy)를 통해 task-specific correction을 생성하며, Shadow Update Module은 Gated Residual Update를 통해 shadow state를 업데이트하여 깊이에 따른 최적의 적응 신호를 유지한다. 실험 결과, ShadowPEFT는 Qwen3 backbone(0.6B, 4B, 8B) 전반에서 LoRA 및 DoRA 대비 적은 파라미터 예산으로도 더 우수한 평균 성능을 기록하였다 [Table 1]. 예를 들어 Qwen3 8B 모델에서 ShadowPEFT는 76.92의 평균 점수를 기록하며 LoRA(76.51)와 DoRA(75.99)를 상회하였다. 또한, 이 모델은 엣지 디바이스에서 Detached Shadow-only 모드로 동작 가능하며, 시스템 레벨 평가에서 기존 방법들보다 향상된 추론 정확도와 실시간 응답성을 제공한다 [Figure 4].
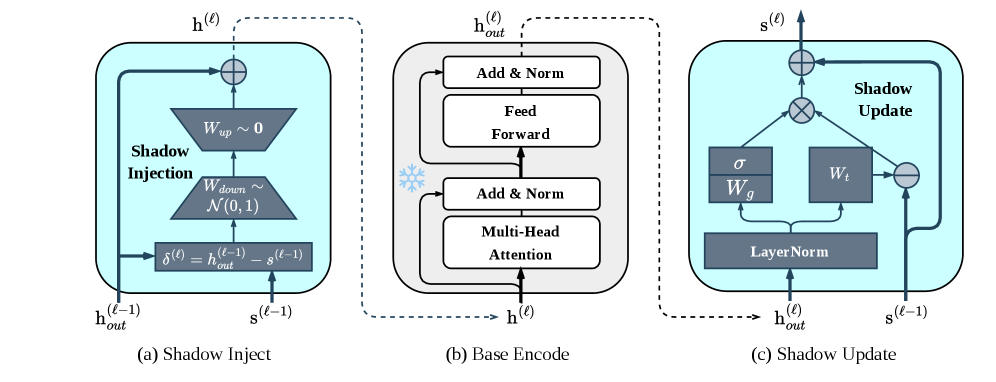
Figure 2 — ShadowPEFT의 상세 아키텍처 및 모듈 구성
4. Conclusion & Impact (결론 및 시사점)
본 논문은 adaptation을 단순한 가중치 주입(weight injection)이 아닌 stateful한 기능적 오버레이(functional overlay)로 재정의하는 ShadowPEFT를 성공적으로 제시하였다. 본 연구는 적응 모듈의 모듈러 배포와 Shadow-only inference를 가능하게 함으로써 LLM의 배포 유연성을 대폭 확장하였다. 이러한 접근 방식은 특히 컴퓨팅 자원이 제한된 환경에서 대규모 모델의 지능을 효율적으로 활용할 수 있게 하여, 산업 현장에서의 실질적인 LLM 적용 가능성을 높이는 중요한 이정표가 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Path Not Taken: RLVR Provably Learns Off the Principals
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
Review 의 다른글
- 이전글 [논문리뷰] PlayCoder: Making LLM-Generated GUI Code Playable
- 현재글 : [논문리뷰] ShadowPEFT: Shadow Network for Parameter-Efficient Fine-Tuning
- 다음글 [논문리뷰] Speculative Decoding for Autoregressive Video Generation
댓글