[논문리뷰] RewardFlow: Generate Images by Optimizing What You Reward
링크: 논문 PDF로 바로 열기
저자: Onkar Susladkar, Dong-Hwan Jang, Tushar Prakash, Adheesh Juvekar, Vedant Shah, Ayush Barik, Nabeel Bashir, Muntasir Wahed, Ritish Shrirao, Ismini Lourentzou
1. Key Terms & Definitions (핵심 용어 및 정의)
- RewardFlow : 사전 학습된 flow-matching 또는 diffusion 모델을 inference 시점에 다중 보상(multi-reward)으로 조절하여 이미지를 생성 및 편집하는 training-free 및 inversion-free 프레임워크입니다.
- Langevin Dynamics : 사전 학습된 생성 모델의 score function을 기반으로 보상(reward)의 경사도를 추가하여 원하는 방향으로 잠재 변수(latent variable)를 업데이트하는 샘플링 전략입니다.
- Semantic Primitives (SP) : 프롬프트에서 추출된 atomic한 의미 단위들로, 각각 독립적인 generative objective를 할당하여 복합적인 편집 명령을 효율적으로 수행하도록 돕는 메커니즘입니다.
- KL Tether : 원본 이미지의 잠재 공간(latent space)을 기준으로 KL divergence를 최소화하여 편집 과정에서 발생할 수 있는 내용 변형(content drift)이나 구조적 붕괴를 방지하는 정규화 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존의 diffusion 기반 이미지 편집 모델들이 요구하는 고비용의 fine-tuning 또는 불안정한 inversion 과정을 극복하고, zero-shot 설정에서 보다 정교하고 일관된 편집을 수행하는 것을 목적으로 합니다. 기존의 training-free 편집 방식들은 원본 잠재 표현(latent representation)을 재구성하는 과정에서 layout 왜곡이나 identity 손실이 발생하기 쉽고, 단순한 보상 기반 접근법은 의미적 정밀도나 공간적 제어 능력이 부족하다는 한계가 있습니다. 이러한 문제를 해결하기 위해 본 논문은
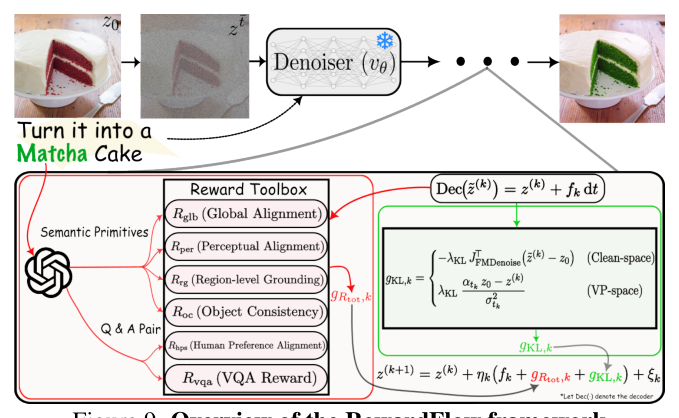
와 같이 다양한 보상을 결합하고 이를 동적으로 조절할 수 있는 새로운 Langevin-based 최적화 프레임워크를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
RewardFlow는 의미론적 정렬, 공간적 grounding, 객체 일관성, 인간 선호도, VQA 기반의 fine-grained 감독 신호를 통합한 다중 보상 Langevin dynamics를 통해 샘플링 궤적을 제어합니다. 핵심은 [Figure 9]에 명시된 prompt-aware adaptive policy로, 프롬프트에서 semantic primitives를 파싱하고 편집 의도에 따라 보상 가중치(reward weights)와 step size를 실시간으로 조절합니다. 특히 SAM2 기반의 object reward와 VQA reward를 사용하여 고도로 국소화된(localized) 편집이 가능하며, KL tether를 통해 원본 구조를 유지합니다.
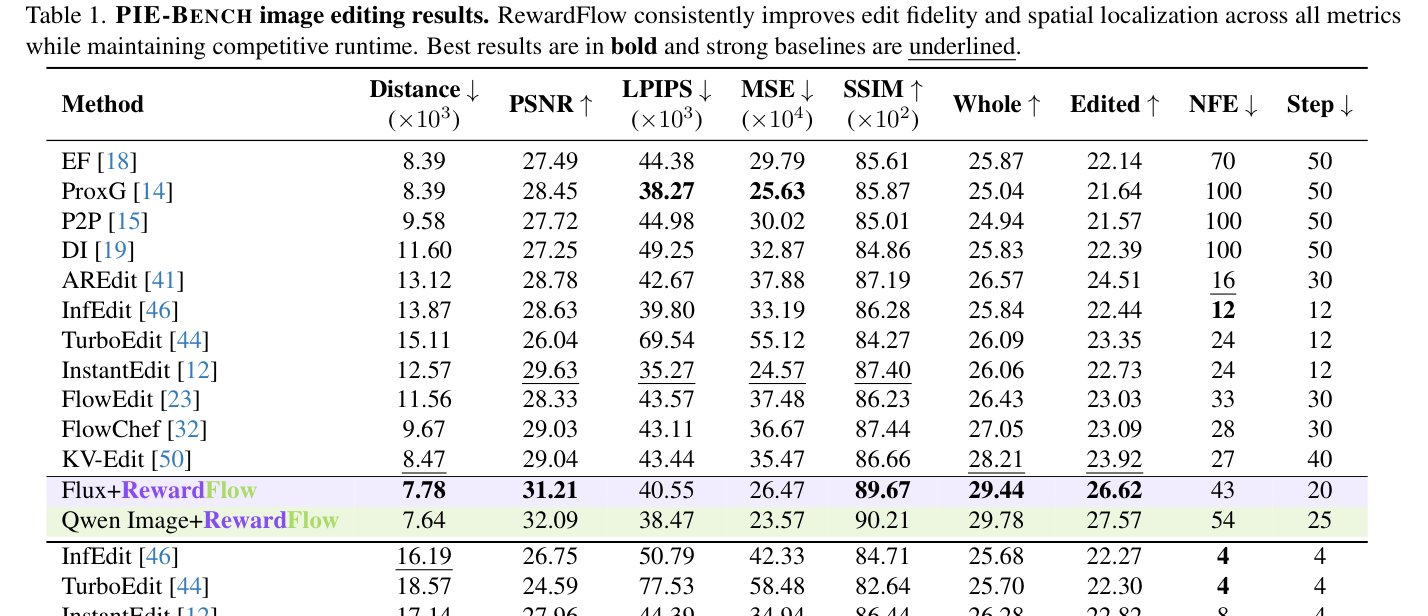
의 PIE-BENCH 벤치마크 결과에 따르면, RewardFlow는 기존의 최신 editing 모델들(e.g., InfEdit, FlowEdit, TurboEdit) 대비 Distance 지표를 7.3% 개선하고, 편집 정밀도(Edited accuracy)를 8.6% 향상시키는 등 압도적인 성능을 보였습니다. 이는 대규모 fine-tuning 없이도 복잡한 속성 변경과 공간적 제약 조건을 효과적으로 충족함을 정량적으로 증명합니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고정된 모델 가중치를 수정하지 않고도 inference 시점에 복합적인 보상을 활용해 정밀한 이미지 생성 및 편집이 가능함을 입증하였습니다. RewardFlow는 다양한 생성 모델 backbone(Flux, Qwen, PixArt-α 등)에 범용적으로 적용 가능한 강력한 zero-shot alignment 프레임워크로, 향후 비디오 편집 및 대규모 생성 모델의 제어 가능성을 높이는 핵심 기술로 자리 잡을 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Multi-Resolution Flow Matching: Training-Free Diffusion Acceleration via Staged Sampling
- [논문리뷰] Qwen-Image-2.0-RL Technical Report
- [논문리뷰] ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
- [논문리뷰] Text-Vision Co-Instructed Image Editing
- [논문리뷰] Is This Edit Correct? A Multi-Dimensional Benchmark for Reasoning-Aware Image Editing
Review 의 다른글
- 이전글 [논문리뷰] Rethinking Generalization in Reasoning SFT: A Conditional Analysis on Optimization, Data, and Model Capability
- 현재글 : [논문리뷰] RewardFlow: Generate Images by Optimizing What You Reward
- 다음글 [논문리뷰] SIM1: Physics-Aligned Simulator as Zero-Shot Data Scaler in Deformable Worlds
댓글