[논문리뷰] FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jangho Park, Geon Yeong Park, Gihyun Kwon, Jong Chul Ye, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Flow Matching: 단순한 소스 분포에서 타겟 데이터 분포로 데이터를 직선 경로를 통해 변환하는 연속 정규화 흐름(Continuous Normalizing Flow) 학습 기법입니다.
- Tweedie Matching: 인접한 비디오 청크(Chunk) 사이의 오버랩 영역에서 예측된 클린 샘플(Clean Samples)을 블렌딩하여 시간적 일관성과 매니폴드 제약(Manifold Constraint)을 강제하는 기법입니다.
- Stochastic Early-Phase Sampling: 샘플링 초기 단계에서 노이즈를 주입하여 각 청크의 결정론적(Deterministic) ODE 경로 의존성을 깨고, 청크 간의 혼합을 촉진하는 하이브리드 샘플링 전략입니다.
- Inference-time Framework: 추가적인 모델 학습이나 fine-tuning 없이, 추론 과정에서만 동작하여 모델의 기능을 확장하는 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 비디오 Diffusion 모델의 생성 범위를 학습된 문맥 길이 이상으로 확장하는 과정에서 발생하는 품질 저하와 시간적 일관성 문제를 해결하고자 합니다. 기존의 bidirectional 모델은 긴 시퀀스에서 아티팩트가 축적되는 한계가 있으며, autoregressive 모델은 KV-cache 재사용으로 인한 exposure bias와 모션의 반복성(Repetitive Motion) 문제에 직면해 있습니다. 또한, 이러한 방법들은 아키텍처에 종속적이거나 복잡한 distillation 과정이 필수적이라는 제약이 있습니다. 저자들은 모델 구조를 수정하지 않고도 긴 비디오를 일관성 있게 생성할 수 있는 범용적인 추론 프레임워크가 필요하다고 판단하였습니다 [Figure 1].

Figure 1 — FlowLong의 적용 범위
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 긴 비디오 생성을 매니폴드 제약이 부여된 역문제(Inverse Problem)로 재정의하여 청크 간의 일관성을 확보하는 FlowLong을 제안합니다. 제안 방법론은 오버랩되는 슬라이딩 윈도우를 동시에 샘플링하고, 각 샘플링 단계에서 Tweedie matching을 통해 인접 청크의 클린 추정치를 정렬합니다 [Figure 2]. 또한, 샘플링 초기 단계에서 확률적 노이즈를 주입하는 Stochastic Early-Phase Sampling을 통해 결정론적 ODE 경로의 경직성을 극복하고 청크 간의 유연한 결합을 유도합니다 [Figure 3]. 실험 결과, FlowLong은 기존의 학습 기반 혹은 autoregressive 베이스라인 모델들과 비교하여 VBench 지표상에서 Dynamic Degree와 Overall 점수가 현저히 높았으며, 특히 60초 이상의 긴 비디오 생성에서 뛰어난 성능을 보였습니다 [Table 1]. 또한, 별도의 fine-tuning 없이 오디오-비디오 공동 생성 및 text-to-3DGS 생성으로 확장 가능함을 입증하였습니다 [Figure 5].
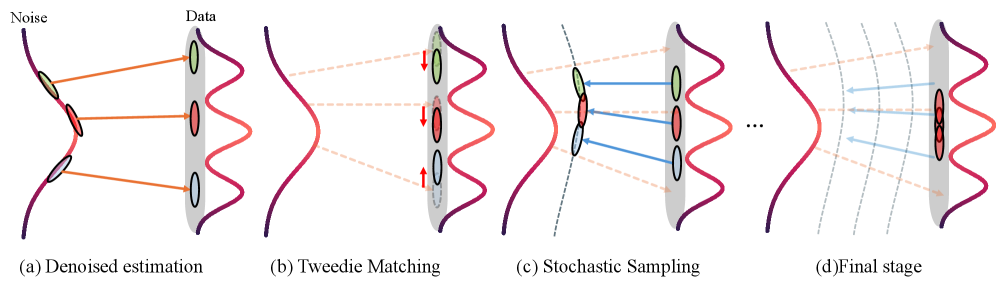
Figure 2 — FlowLong 메인 파이프라인

Figure 3 — 30초 비디오 생성 정성 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Tweedie matching과 Stochastic early-phase sampling을 핵심으로 하는 학습이 필요 없는 아키텍처 독립적 프레임워크 FlowLong을 성공적으로 제시하였습니다. 이 연구는 기존 비디오 생성 모델의 시간적 확장성 한계를 획기적으로 개선하며, 비디오 생성 분야뿐만 아니라 3D 생성 등 다양한 생성형 AI 태스크에 범용적으로 적용 가능하다는 강력한 시사점을 제공합니다. 연구진은 향후 로컬 제약 조건을 넘어선 전체적인 의미적 일관성 강화 문제를 후속 연구 과제로 제안합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Mode Seeking meets Mean Seeking for Fast Long Video Generation
- [논문리뷰] Multi-Resolution Flow Matching: Training-Free Diffusion Acceleration via Staged Sampling
- [논문리뷰] Qwen-Image-2.0-RL Technical Report
- [논문리뷰] Memento: Reconstruct to Remember for Consistent Long Video Generation
- [논문리뷰] Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
Review 의 다른글
- 이전글 [논문리뷰] Diversed Model Discovery via Structured Table Discovery
- 현재글 : [논문리뷰] FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching
- 다음글 [논문리뷰] From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
댓글