[논문리뷰] Qwen-Image-2.0-RL Technical Report
링크: 논문 PDF로 바로 열기
저자: Yixian Xu, Kaiyuan Gao, Yuxiang Chen, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- RLHF (Reinforcement Learning from Human Feedback): 인간의 선호도를 반영하여 모델의 생성 결과물을 정렬하는 강화학습 기법.
- GRPO (Group Relative Policy Optimization): 환경과의 상호작용 그룹 내에서 보상을 정규화하여 학습의 효율성과 안정성을 높이는 강화학습 프레임워크.
- OPD (On-Policy Distillation): 서로 다른 Task별로 훈련된 여러 Teacher 모델의 능력을 단일 Student 모델로 통합하는 학습 전략.
- Pointwise Reward Modeling: 이미지 쌍 비교 방식(Pairwise)과 달리, 단일 이미지에 대해 인간이 매긴 절대적인 점수를 회귀 학습하여 모델을 평가하는 방식.
- Hybrid CFG (Classifier-Free Guidance): 학습 시에는 무조건부 분기를 배제하여 안정적인 그래디언트 업데이트를 돕고, Rollout 단계에서는 성능을 극대화하기 위해 CFG를 적용하는 전략.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 Qwen-Image-2.0 diffusion 모델이 가진 생성 품질과 지시 이행 능력 사이의 간극을 좁히고, 복잡한 편집 태스크에서 일관된 성능을 확보하기 위해 수행되었다. 기존의 지도 학습 기반 diffusion 모델은 인간의 미적 기대치나 복잡한 지시 사항을 정확히 포착하는 데 한계가 있으며, 특히 T2I(Text-to-Image)와 편집 태스크를 동시에 최적화할 때 발생하는 성능 간섭(seesaw effect) 문제가 주요한 해결 과제였다. 이를 위해 저자들은 태스크별로 전문화된 보상 모델과 효율적인 학습 파이프라인을 설계한 [Figure 1]을 도입하여, 개별 모델의 성능을 유지하면서 하나의 Unified 모델로 통합하고자 하였다.
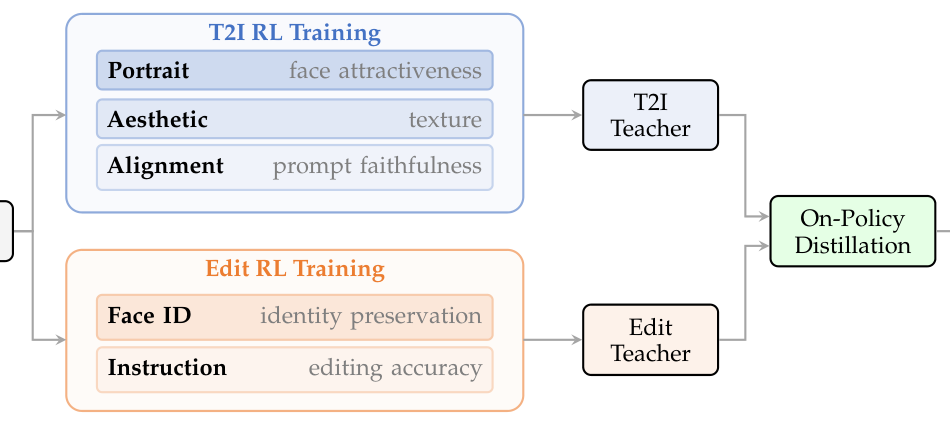
Figure 1 — T2I 및 Edit 태스크별 보상 모델 설계와 최종 On-Policy Distillation 구조를 설명하는 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Pointwise 방식의 VLM 기반 보상 모델과 GRPO 기반의 강화학습 파이프라인을 결합하여 모델 성능을 개선하였다. 학습 효율을 위해 Hybrid CFG 전략을 도입하여 학습 중 모델 붕괴를 방지하였고, Asynchronous reward pipeline을 통해 여러 보상 모델을 사용함에 따른 지연 시간을 최소화하였다. 최종적으로 OPD를 통해 T2I와 편집 태스크 각각에서 학습된 Teacher 모델들의 지식을 단일 모델로 정교하게 이전하였다. 평가 결과, Qwen-Image-2.0-RL은 Qwen-Image-Bench에서 베이스 모델 대비 2.61점 향상된 57.84의 Overall Score를 달성하였으며, T2I Arena와 Image Edit Arena에서 각각 1193점(+78)과 1349점(+93)의 Elo rating을 기록하며 탁월한 비교 우위를 입증하였다 [Table 1].
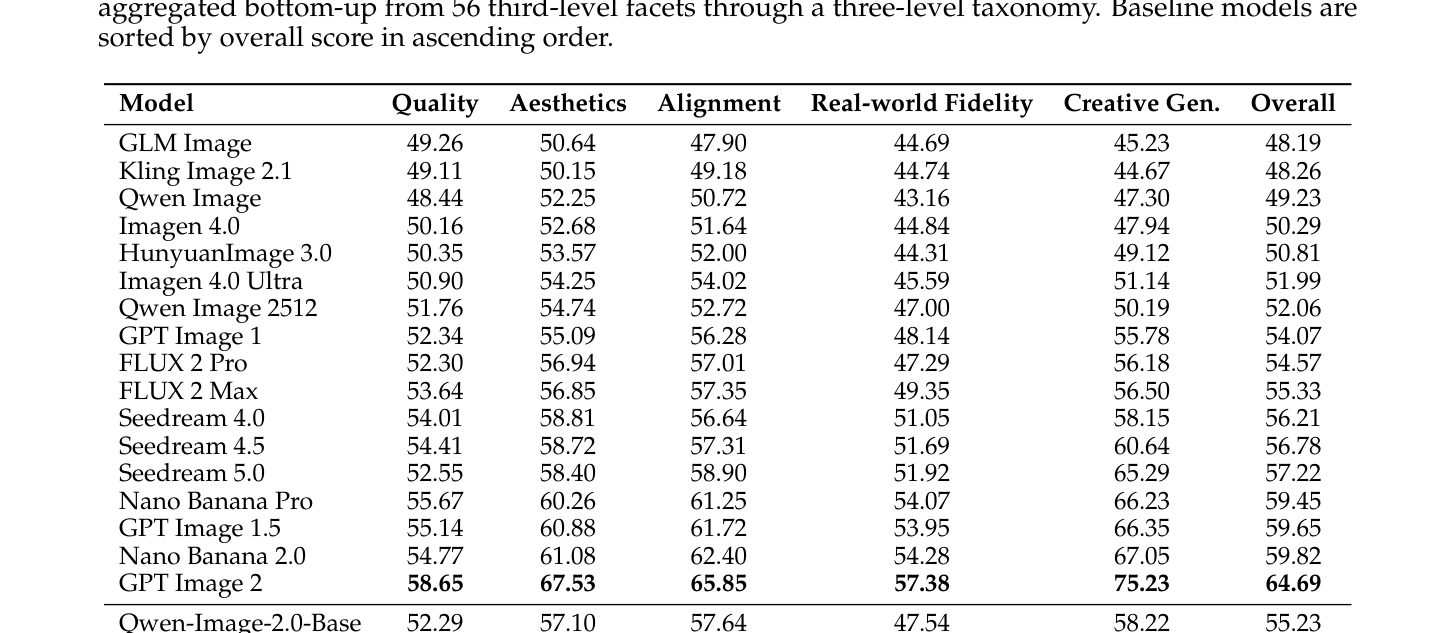
Table 1 — 모델의 성능 개선을 정량적으로 증명하는 핵심 벤치마크 비교 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 RLHF와 OPD를 결합하여 diffusion 모델의 시각적 품질과 지시 이행 능력을 비약적으로 향상시킨 Qwen-Image-2.0-RL 파이프라인을 제안하였다. 본 시스템은 복잡한 다중 보상 체계 하에서도 Hybrid CFG와 OPD를 통해 안정적인 학습과 태스크 간 간섭 없는 모델 통합을 가능하게 하였다. 이러한 접근 방식은 향후 멀티모달 생성 모델의 강화학습 정렬 연구에 있어 효율적이고 확장 가능한 베이스라인으로 활용될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Kandinsky 5.0: A Family of Foundation Models for Image and Video Generation
- [논문리뷰] Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
- [논문리뷰] Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
- [논문리뷰] Mitigating Perceptual Judgment Bias in Multimodal LLM-as-a-Judge via Perceptual Perturbation and Reward Modeling
- [논문리뷰] FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching
Review 의 다른글
- 이전글 [논문리뷰] ProMSA:Progressive Multimodal Search Agents for Knowledge-Based Visual Question Answering
- 현재글 : [논문리뷰] Qwen-Image-2.0-RL Technical Report
- 다음글 [논문리뷰] SimFoundry: Modular and Automated Scene Generation for Policy Learning and Evaluation
댓글