[논문리뷰] ProMSA:Progressive Multimodal Search Agents for Knowledge-Based Visual Question Answering
링크: 논문 PDF로 바로 열기
메타데이터
저자: ZhengXian Wu, Hangrui Xu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- KB-VQA: 이미지 이해 능력과 Wikipedia와 같은 외부 지식 소스를 결합하여 질문에 답해야 하는 과제로, 특히 long-tail entity가 포함된 복합적 추론을 요구함.
- Progressive Multimodal Search Agent: 고정된 retrieval-then-generate 파이프라인에서 벗어나, 추론 과정 중 다중 라운드 인터랙션을 통해 필요에 따라 이미지/텍스트 검색을 수행하고 정보가 충분하면 stop하여 답변하는 에이전트 프레임워크.
- TN-GSPO (Tool-Normalized Grouped Sequence-level Policy Optimization): 에이전트의 학습 안정성을 위해 생성된 텍스트 길이뿐만 아니라 tool-interaction depth까지 고려하여 시퀀스 레벨의 보상을 정규화하는 RL 방법론.
- Deduplication: 중복 검색을 방지하기 위해 이전에 검색된 페이지 목록을 exclude 리스트로 관리하여, 에이전트가 점진적으로 새로운 증거를 확보하도록 돕는 메커니즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 KB-VQA의 고질적인 문제인 정적인 파이프라인의 한계를 극복하고, 모델이 예산 효율적으로 정보를 검색하며 스스로 추론하는 에이전트 시스템을 구축하는 것을 목적으로 한다. 기존 연구들은 고정된 top-k 설정에 의존하여 검색된 정보가 불충분하거나 잘못된 경우 이를 수정할 수 없는 고착 상태에 빠지기 쉽다 [Figure 1]. 또한, 엔티티 식별 여부나 질문의 복합성에 따라 필요한 검색 modality와 깊이가 달라짐에도 불구하고, 이를 유연하게 제어하지 못한다는 문제점이 존재한다. 따라서, 명시적인 tool-call budget 내에서 언제 검색을 수행하고 언제 멈출지 결정할 수 있는 closed-loop 시스템이 필수적이다.
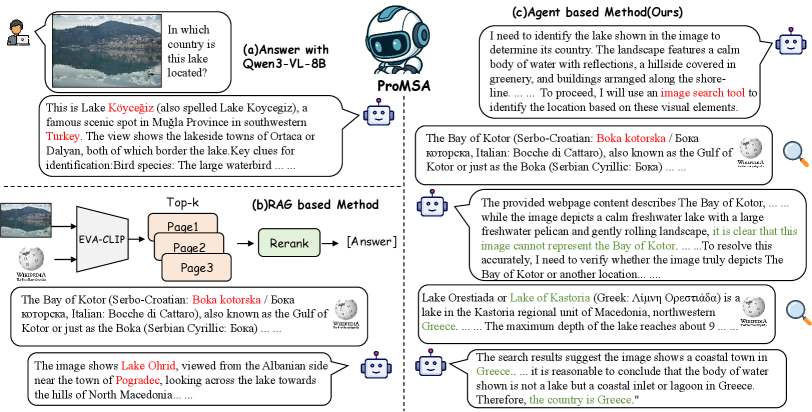
Figure 1 — 기존 방식과 ProMSA 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 ProMSA를 제안하며, 이는 Wikipedia를 대상으로 하는 다중 라운드 이미지/텍스트 검색 및 추론 프레임워크이다 [Figure 2]. 모델은 매 단계마다 현재까지 수집된 정보를 바탕으로 action(img_search, text_search, stop)을 선택하며, TN-GSPO를 통해 학습된 정책(policy)은 tool-interaction depth와 generation length를 모두 정규화하여 안정적인 최적화를 달성한다. 실험 결과, ProMSA는 E-VQA 및 InfoSeek 벤치마크에서 기존의 RAG 및 에이전트 기반 모델들을 압도하는 성능을 보였다. 구체적으로 Qwen3-VL-8B 기반의 ProMSA는 InfoSeek에서 53.4%의 정확도를 기록하여, CC-VQA(45.1%) 및 REAL(44.1%) 등 SOTA 모델 대비 유의미한 성능 향상을 입증하였다 [Table 1]. 또한, 제안하는 TN-GSPO 기법은 기존 GRPO나 GSPO보다 높은 안정성과 정량적 지표 개선을 보여주었으며, 도구 사용의 효용성을 극대화하였다 [Table 3].
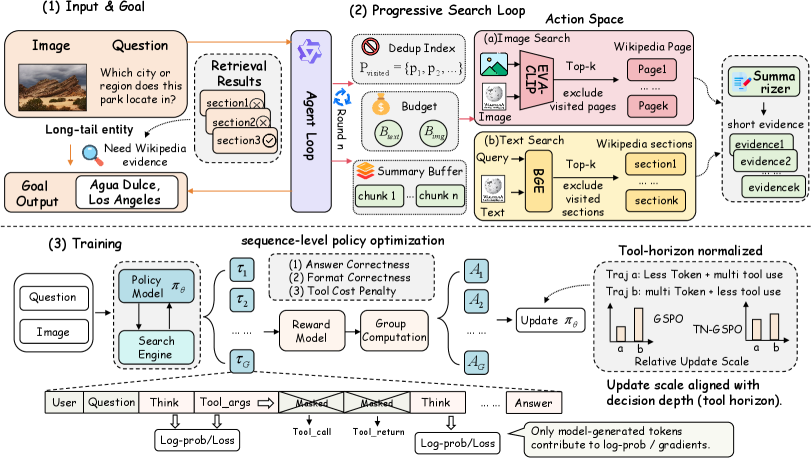
Figure 2 — ProMSA 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 KB-VQA를 예산 제약이 있는 progressive search-and-reason 문제로 재정의하고, 이를 해결하기 위한 ProMSA를 성공적으로 제안하였다. 이 시스템은 단순한 증거 검색을 넘어, 모델 스스로 검색의 적절성과 완전성을 판단하여 동적으로 대응하는 agentic capabilities를 확보했다는 점에서 학술적 가치가 높다. 특히, TN-GSPO를 통한 학습 전략은 복합적 도구 사용이 필요한 다양한 멀티모달 에이전트 학습에 널리 활용될 수 있는 일반적인 프레임워크로서 가치를 지닌다. 본 연구 결과는 복잡한 외부 지식 탐색이 필요한 엔터프라이즈 급 지능형 에이전트 서비스 개발에 중요한 기술적 토대를 제공할 것으로 기대된다.
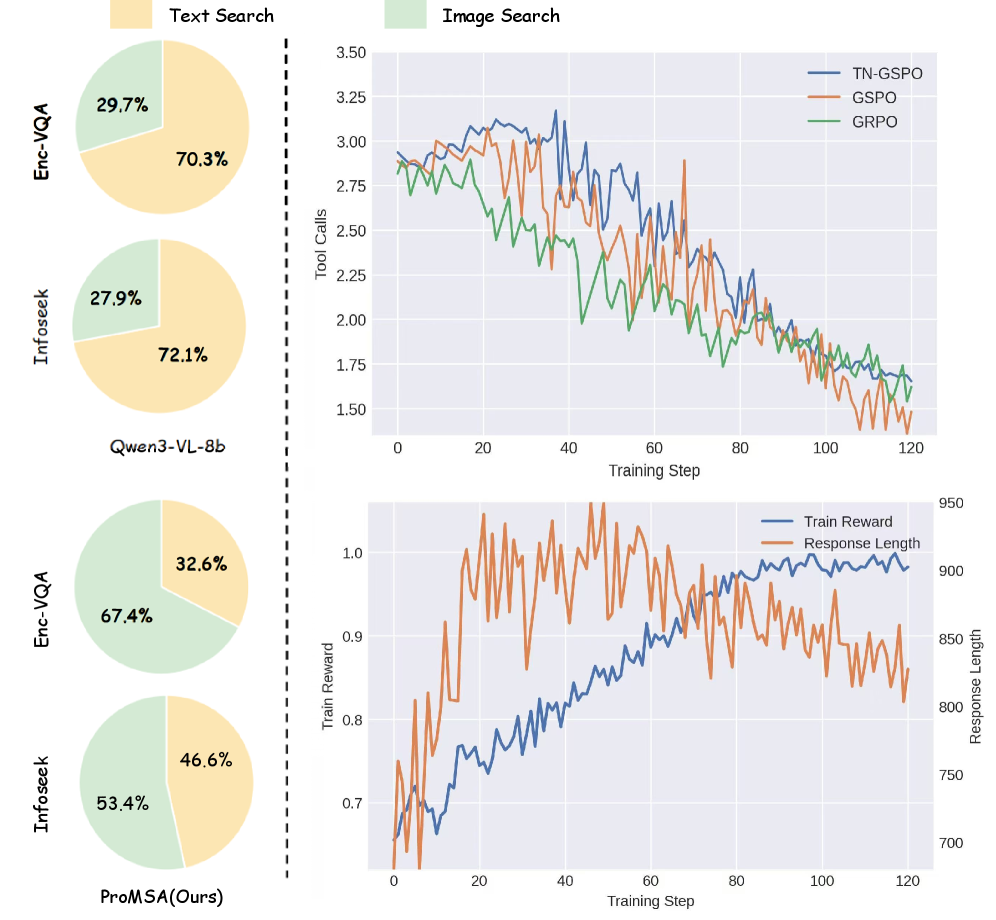
Figure 3 — 도구 사용 및 학습 동역학
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] Dockerless: Environment-Free Program Verifier for Coding Agents
- [논문리뷰] TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
Review 의 다른글
- 이전글 [논문리뷰] PhysisForcing: Physics Reinforced World Simulator for Robotic Manipulation
- 현재글 : [논문리뷰] ProMSA:Progressive Multimodal Search Agents for Knowledge-Based Visual Question Answering
- 다음글 [논문리뷰] Qwen-Image-2.0-RL Technical Report
댓글