[논문리뷰] SimFoundry: Modular and Automated Scene Generation for Policy Learning and Evaluation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Nadun Ranawaka, Josiah Wong, Wei-Lin Pai, Wei-Teng Chu, Tianyuan Dai, Masoud Moghani, Hang Yin, Yunfan Jiang, Wesley Durbano, Brandon Huynh, Yu Fang, Linxi Fan, Danfei Xu, Ruohan Zhang, Li Fei-Fei, Bowen Wen, Ajay Mandlekar, Yuke Zhu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Digital Twins: 입력된 실제 환경의 시각적 형태, 물리적 특성, 배치를 시뮬레이션 내에 정밀하게 복제한 가상 환경.
- Digital Cousins: 원본 환경의 작업 관련 의미론적 정보를 유지하면서 물체 인스턴스, 배치, 작업 조건을 변형하여 생성한 다양한 시뮬레이션 환경.
- Real-to-Sim Evaluation: 실제 환경에서 수행된 로봇 정책(Policy)의 성능을 시뮬레이션 환경에서 평가하여, 비용 효율적으로 정책의 적합성을 사전에 검증하는 방식.
- MMRV (Mean Maximum Rank Violation): 실제 환경과 시뮬레이션 환경에서의 정책 순위 불일치를 측정하는 지표로, 낮을수록 시뮬레이션 평가가 실제 성능을 잘 예측함을 의미.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 로봇 정책 학습 및 평가를 위한 대규모 데이터 확보의 어려움과 복잡한 환경에서의 시뮬레이션 구축 비용 문제를 해결하기 위해 SimFoundry를 제안한다. 기존 연구들은 환경 구축을 위한 수동 작업이 많이 필요하거나, 실제 환경과 시뮬레이션 간의 물리적·시각적 불일치로 인해 Sim2Real 전이가 어렵다는 한계가 있다. 또한, 단순히 3D 장면을 재구성하는 모델들은 로봇의 물리적 상호작용이나 정책 평가를 위한 체계적인 데이터 생성 기법이 결여되어 있다. 저자들은 이러한 Bottleneck을 극복하고자 단일 비디오를 통해 대화형(Interactive) 시뮬레이션 환경을 자동으로 구축하고 확장하는 통합 프레임워크를 개발하였다 [Figure 1].
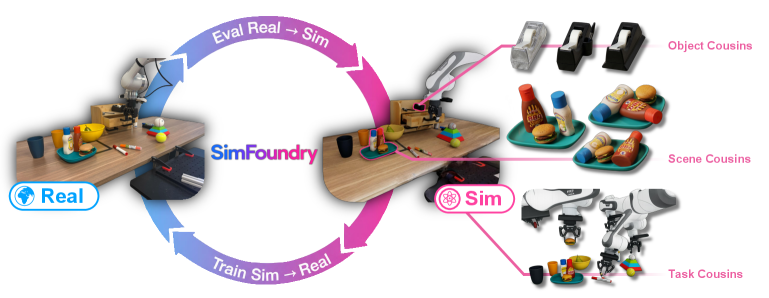
Figure 1 — SimFoundry 시스템 전체 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
SimFoundry는 Extraction, Generation, Augmentation이라는 3단계의 모듈형 파이프라인을 통해 실제 장면을 sim-ready digital twin으로 변환한다 [Figure 2]. Extraction 단계에서는 비디오에서 객체를 분할하고, Generation 단계에서는 Mesh 생성, 포즈 정렬, 물리 파라미터 주석(Annotation)을 수행하며, Augmentation 단계에서는 digital cousins를 생성하여 학습 데이터의 다양성을 확보한다 [Figure 3]. 7개의 조작 작업과 5개의 정책 아키텍처를 대상으로 실험한 결과, SimFoundry의 시뮬레이션 평가 지표는 실제 환경 성능과 높은 상관관계를 보였으며, Pearson correlation 0.911, MMRV 0.018을 달성하여 기존 SOTA 모델을 큰 폭으로 상회하였다. 또한, object cousins, scene cousins, task cousins를 사용하여 학습된 정책은 실제 환경에서 평균 성공률이 각각 17%, 21%, 40% 향상되는 정량적 우위를 확인하였다.
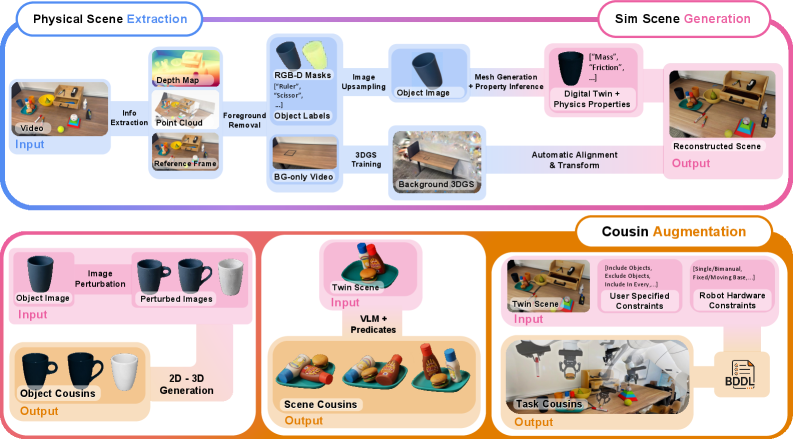
Figure 2 — 방법론 단계별 파이프라인

Figure 3 — 디지털 커즌 생성 샘플
4. Conclusion & Impact (결론 및 시사점)
본 논문은 단일 비디오에서 물리적으로 정확한 시뮬레이션 환경을 자동 생성하고, 이를 통해 정책 평가 및 학습을 모두 수행할 수 있는 SimFoundry의 효과성을 입증하였다. 특히, digital cousins 기법을 통해 적은 데이터로도 복잡한 조작 작업과 다중 임무에 대해 높은 수준의 Sim2Real 전이를 가능하게 함으로써 로봇 학습의 확장성 문제를 해결했다는 점에서 큰 의의가 있다. 이 연구는 향후 로봇 연구자들이 수동 환경 구축 비용을 획기적으로 줄이고, 더욱 다양한 시나리오에서 강건한 범용 정책을 개발할 수 있도록 기여할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
- [논문리뷰] Learning Transferable Dynamics Priors from Action to World Modeling
- [논문리뷰] Guava: An Effective and Universal Harness for Embodied Manipulation
- [논문리뷰] Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
- [논문리뷰] FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
Review 의 다른글
- 이전글 [논문리뷰] Qwen-Image-2.0-RL Technical Report
- 현재글 : [논문리뷰] SimFoundry: Modular and Automated Scene Generation for Policy Learning and Evaluation
- 다음글 [논문리뷰] SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
댓글