[논문리뷰] BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hao Zhang, Yiming Hu, Yong Wang, Mingqiao Mo, Xin Xiao, Xiangxiang Chu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Speculative Decoding: Lightweight draft model이 다수의 토큰을 병렬로 생성하고, Target model이 이를 한 번에 검증하여 가속화하는 추론 프레임워크입니다.
- Diffusion-based Speculative Decoding: Draft model로 Diffusion Language Model(dLLM)을 사용하여, block-level diffusion을 통해 더 긴 토큰 시퀀스를 병렬로 생성하는 방식입니다.
- Block Size: Speculative decoding 과정에서 draft model이 한 번의 forward pass를 통해 생성하는 토큰의 개수입니다.
- Acceptance Length ($\tau$): Draft model이 생성한 후보 토큰들 중 Target model에 의해 최종적으로 수락된 토큰의 평균 개수입니다.
- Instance-Adaptive Policy: 입력 샘플의 특성에 따라 최적의 Block Size를 동적으로 결정하여 추론 효율성을 극대화하는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Diffusion-based Speculative Decoding 방식이 모든 입력 데이터에 대해 동일한 Block Size를 사용하는 정적(static) 전략에 의존하고 있어 비효율적이라는 점을 지적합니다. 각 샘플은 예측 가능성과 문맥적 제약이 다르기 때문에 고정된 Block Size는 병렬성 활용을 저해하거나 오류 누적을 발생시킵니다 [Figure 1]. 저자들은 Block Size가 단순한 하이퍼파라미터가 아니라 입력 데이터의 특성에 따라 가변적인 '의사결정 변수'여야 함을 강조합니다. 이에 따라, 샘플마다 최적의 Block Size를 실시간으로 예측하여 추론 성능을 최적화할 수 있는 새로운 정책 학습 프레임워크가 필요합니다.
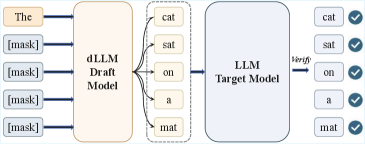
Figure 1 — 확산 기반 Speculative Decoding 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 BlockPilot이라 명명된 인스턴스 적응형(instance-adaptive) 정책 학습 프레임워크를 제안합니다. 제안된 방법론은 사전 정의된 훈련용 Block Size 주변의 로컬 구간에서 최적값을 찾는 분류 문제로 문제를 정형화하며, Target model의 prefilling stage 직후 마지막 토큰의 예측 확률 분포(predictive probability distribution)를 입력 특성으로 활용합니다 [Figure 4]. 이 분포는 문맥 정보와 미래 생성 안정성을 효과적으로 요약하므로, lightweight한 다층 퍼셉트론(MLP) 기반의 예측기만으로도 높은 정확도로 최적 Block Size를 선택할 수 있습니다 [Figure 3]. Qwen3-4B 모델 환경에서 BlockPilot은 Temperature T=1 조건 하에 4.20× Speedup 및 평균 Acceptance Length 5.92를 달성하여 SOTA 성능을 기록했습니다 [Figure 2, Table 2]. 이는 기존의 고정된 DFlash 방식과 비교했을 때, 모든 벤치마크(Math, Code, Chat)에서 일관된 효율성 향상을 입증한 결과입니다 [Table 2].
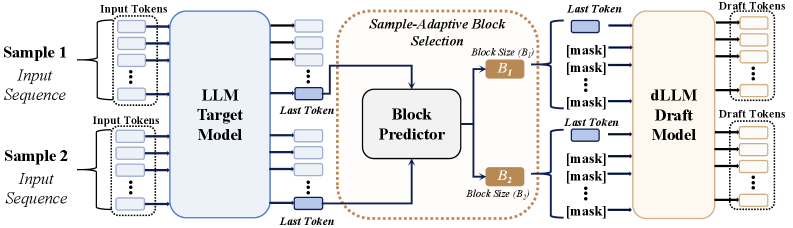
Figure 4 — BlockPilot 추론 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Block Size 결정을 추론 과정의 학습 가능한 정책으로 변환함으로써 Diffusion-based Speculative Decoding의 효율성을 극대화하는 새로운 패러다임을 제시합니다. BlockPilot은 기존 프레임워크의 모델 구조를 수정하지 않는 플러그인(plug-and-play) 방식으로 구현되어 실무 적용 가능성이 매우 높습니다. 이 연구는 LLM 추론 가속화 분야에서 샘플별 동적 자원 할당의 중요성을 재확인하였으며, 향후 고성능 언어 모델의 추론 최적화 전략에 중요한 이정표가 될 것으로 기대됩니다.
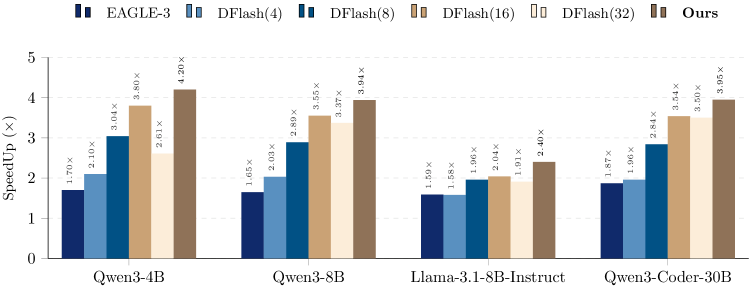
Figure 2 — 모델별 가속화 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] When Confidence Misleads: Suffix Anchoring and Anchor-Proximity Confidence Modulation for Diffusion Language Models
- [논문리뷰] Scaling Embeddings Outperforms Scaling Experts in Language Models
- [논문리뷰] Learning Unmasking Policies for Diffusion Language Models
- [논문리뷰] A Survey on Diffusion Language Models
- [논문리뷰] Multi-Block Diffusion Language Models
Review 의 다른글
- 이전글 [논문리뷰] AVTok: 1D Unified Tokenization for Holistic Audio-Video Generation
- 현재글 : [논문리뷰] BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
- 다음글 [논문리뷰] BrainJanus: A Unified Model for Understanding and Generation across Brain, Vision, and Language
댓글