[논문리뷰] AVTok: 1D Unified Tokenization for Holistic Audio-Video Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Kien T. Pham, I Chieh Chen, Qifeng Chen, Long Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- AVTok: 본 논문에서 제안하는 1D Unified Tokenizer로, 오디오와 비디오 데이터를 하나의 콤팩트한 1D latent representation으로 공동 인코딩하는 아키텍처입니다.
- 1D Visual Tokenization: 3D 스패티오-템포럴(spatio-temporal) 패치 대신, 1D 시퀀스 형태의 이산적(discrete) latent space를 구성하여 Autoregressive(AR) 생성 모델과의 호환성을 극대화하는 기법입니다.
- VFAL (Video-First-Audio-Later): 오디오와 비디오 간의 정보 밀도 차이로 인한 학습 불균형을 해결하기 위해, 비디오 인코딩 능력을 먼저 확보한 후 오디오 인코딩을 점진적으로 통합하는 계층적 학습 전략입니다.
- Representation Alignment Learning: 오디오-비디오 기초 모델을 활용하여 두 모달리티 간의 의미적 대응(semantic correspondence)을 강화하고, 공유된 파라미터 내에서의 암시적 cross-modal 상호작용을 보완하는 학습 목적함수입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 오디오-비디오(AV) 생성 모델들이 겪고 있는 고비용의 Dual-branch 아키텍처 문제와 모달리티 간 Representation Gap을 해결하고자 합니다 [Figure 2]. 기존 방식은 각 모달리티를 별도의 토크나이저로 처리하여 효율성이 떨어질 뿐만 아니라, 임베딩 공간의 불일치로 인해 오디오와 비디오 간의 의미적 정렬(semantic alignment)이 제대로 이루어지지 않는 한계가 있습니다. 이에 저자들은 단일 latent space에서 오디오와 비디오를 공동으로 인코딩하여 이러한 문제를 근본적으로 극복하는 통합 솔루션을 제안합니다 [Figure 1].
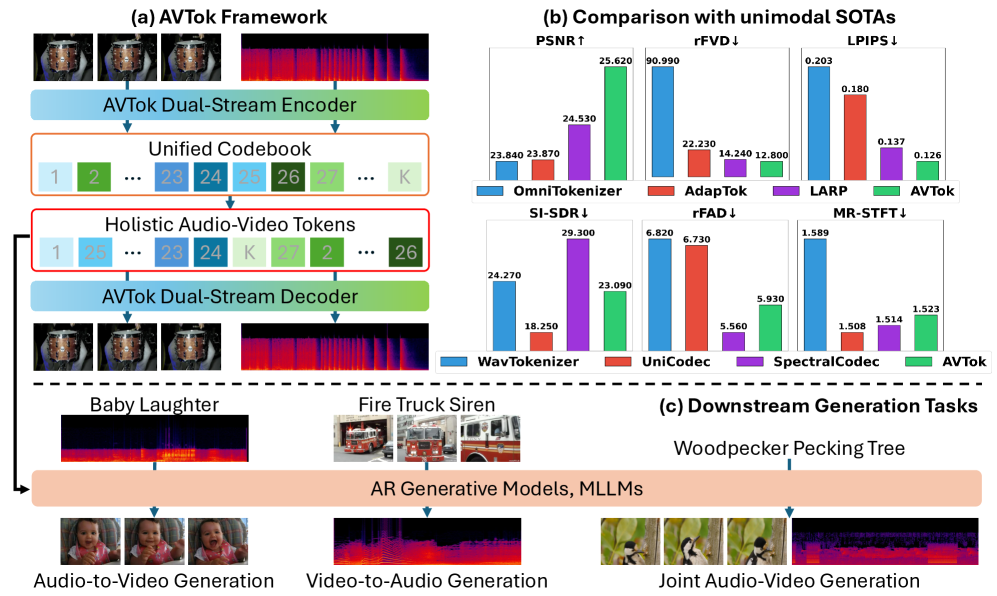
Figure 1 — AVTok 개요 및 성능
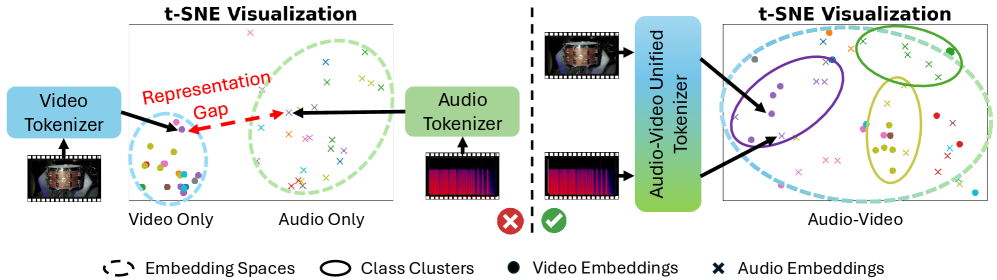
Figure 2 — 기존 방식과 AVTok의 차이
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Dual-stream Transformer 아키텍처를 기반으로 한 AVTok을 제안하며, 각 스트림이 공유된 인코더-디코더와 모달리티별 학습 가능 쿼리(learnable query)를 활용하여 효율적인 통합 인코딩을 수행합니다 [Figure 3]. 모델 학습에는 VFAL 전략을 도입하여 비디오와 오디오의 학습 순서를 최적화함으로써 정보 밀도 차이에서 발생하는 성능 저하를 방지합니다. 실험 결과, AVTok은 기존 모델 대비 오디오-비디오 재구성(reconstruction) 태스크에서 우수한 성능을 보였으며, 정량적 지표에서 PSNR 25.62, rFVD 12.80, rFAD 5.93을 기록하며 SOTA 수준의 효율성을 입증했습니다 [Table 1]. 또한, Audio-to-Video(A2V), Video-to-Audio(V2A) 및 Class-conditional Joint Audio-Video Generation(cJAVG) 등 다양한 다운스트림 작업에서도 강력한 일반화 성능을 확인했습니다.
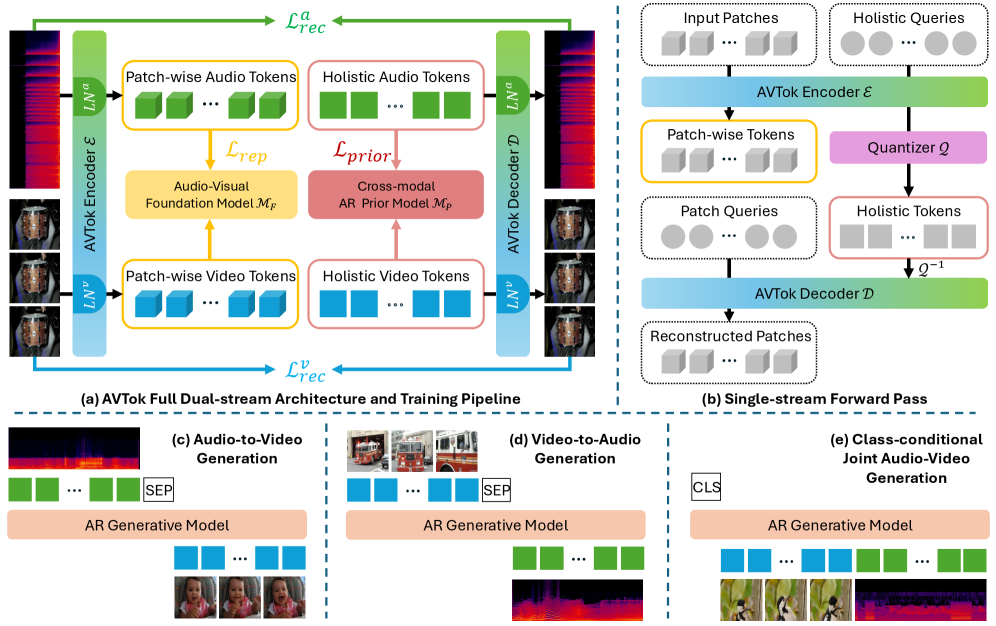
Figure 3 — AVTok 아키텍처 세부사항
4. Conclusion & Impact (결론 및 시사점)
본 연구는 1D Unified Tokenization을 통해 효율적이고 효과적인 오디오-비디오 생성의 새로운 패러다임을 제시하였습니다. AVTok은 복잡한 듀얼 브랜치 설계를 단순화하고 모달리티 간의 정렬 문제를 성공적으로 완화하였습니다. 이 연구는 대규모 멀티모달 모델(LMM)의 효율적인 학습을 위한 토대를 마련하였으며, 향후 고품질의 동기화된 오디오-비디오 생성 모델 개발에 중요한 지침을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MVEB: Massive Video Embedding Benchmark
- [논문리뷰] LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
- [논문리뷰] Multimodal Music Recommendation System using LLMs
- [논문리뷰] StreamChar: Long-Horizon Streaming Character Audio-Video Generation with Decoupled Orchestration
Review 의 다른글
- 이전글 [논문리뷰] ZooClaw-FashionSigLIP2: Distilled Fine-tuning for Robust Fashion Retrieval
- 현재글 : [논문리뷰] AVTok: 1D Unified Tokenization for Holistic Audio-Video Generation
- 다음글 [논문리뷰] BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
댓글