[논문리뷰] Learning Transferable Dynamics Priors from Action to World Modeling
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ze Huang, Jiahui Zhang, Hairuo Liu, Chenxi Zhang, Ran Cheng, Li Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- A2World: 다양한 로봇 데이터로 사전 학습된, action-conditioned 다중 뷰 인터랙티브 Diffusion 기반 월드 모델입니다.
- Dynamics Priors: 로봇의 행동이 시각적 장면 변화를 어떻게 유도하는지에 대한 근본적인 상호작용 규칙으로, 다양한 로봇 시스템에 범용적으로 전이 가능한 지식입니다.
- A2World-sim: A2World를 미세 조정하여 구축한, 장기(long-horizon) 시뮬레이션 및 정책 평가를 위한 과거 지향적(history-aware) 자귀귀적(autoregressive) 모델입니다.
- A2World-policy: A2World를 비디오-액션 공동 예측 모델로 전이시킨 형태로, 시각적 정보와 지시사항을 바탕으로 액션을 생성하는 강화된 로봇 정책입니다.
- MoE-like (Mixture of Experts): 비디오와 액션이 어텐션 모듈을 공유하여 상호작용하고, 각 모달리티별로 독립적인 디노이징 브랜치를 사용하는 아키텍처 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 로봇 데이터를 활용하여 범용적인 Dynamics Priors를 학습하고, 이를 통해 로봇 학습의 시뮬레이터와 정책 성능을 동시에 향상시키는 것을 목표로 합니다. 기존의 많은 연구들은 범용 비디오 생성 모델에서 출발하거나 특정 데이터셋에만 의존하여, 다양한 로봇 구현체(embodiment)와 작업에 대한 범용적인 상호작용 규칙을 학습하는 데 한계가 있었습니다 [Figure 1]. 또한, 단순히 정책 학습에만 최적화된 모델은 시뮬레이터로 재사용하기 어렵다는 단점이 있습니다. 따라서 저자들은 액션을 통해 자연스러운 인과적 감독 신호를 제공함으로써, 환경과 작업이 변하더라도 유지되는 핵심 상호작용 규칙을 학습하는 새로운 접근 방식을 제안합니다.
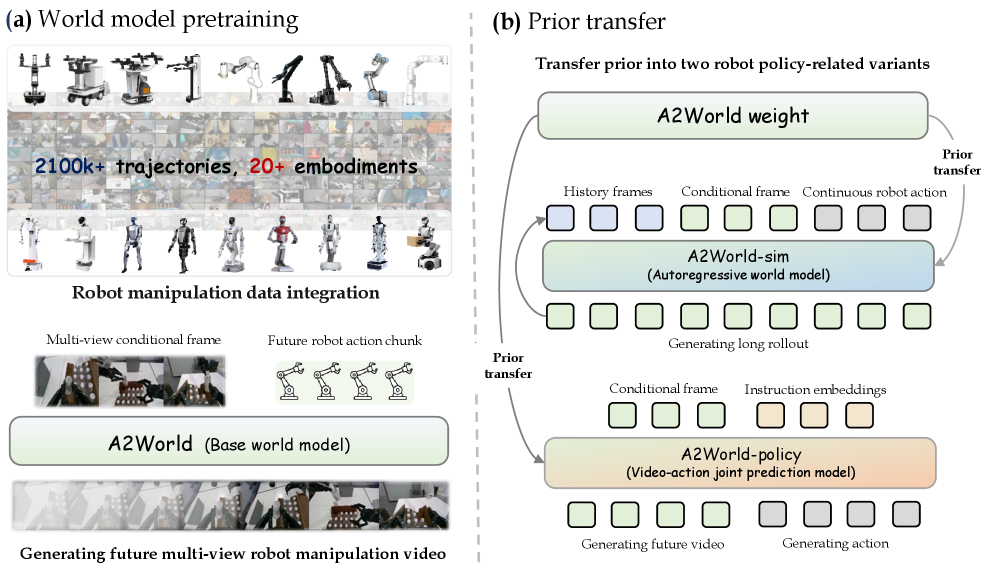
Figure 1 — 모델 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 대규모 로봇 데이터를 기반으로 A2World를 사전 학습한 후, 이를 A2World-sim과 A2World-policy라는 두 가지 핵심 변형으로 전이(transfer)하는 프레임워크를 제안합니다 [Figure 1]. A2World-sim은 과거 관측 데이터를 압축적으로 활용하는 Pose-guided history sampling 기법을 적용하여 장기 시뮬레이션 환경을 구축합니다 [Figure 2]. 정량적 결과에 따르면, 제안 모델은 LIBERO 벤치마크 및 실제 로봇 환경에서 기존 베이스라인(Cosmos-Predict2, Ctrl-World 등) 대비 PSNR 및 SSIM 측면에서 월등한 성능을 기록했습니다 [Table 2]. 특히 A2World-policy는 최소한의 미세 조정만으로 LIBERO 벤치마크에서 98.6%의 평균 성공률을 달성하며 최상위권 성능을 입증했습니다 [Table 5]. 실제 로봇 실험에서도 복잡한 접촉 작업(contact-rich manipulation) 수행 시 베이스라인 모델들을 상회하는 높은 성공률을 보여주었습니다 [Figure 9, Figure 10].
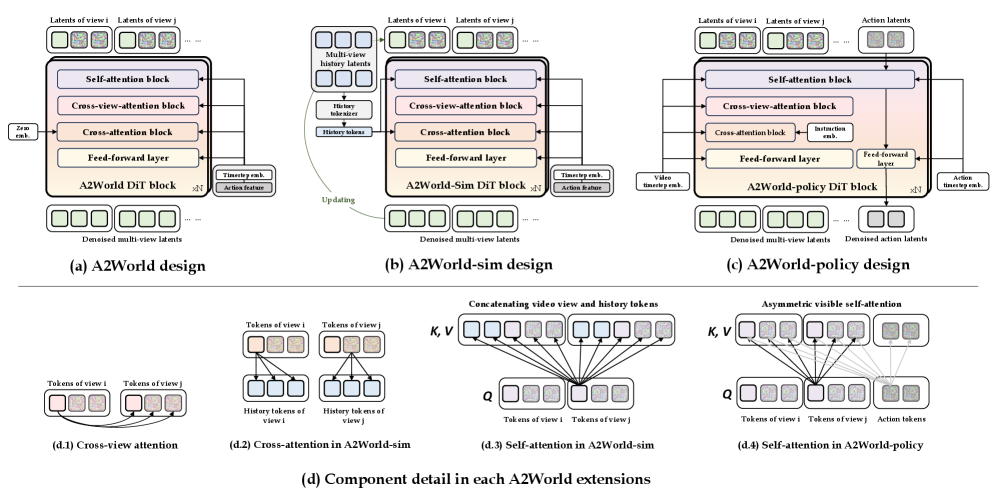
Figure 2 — A2World 시리즈 모듈 설계
4. Conclusion & Impact (결론 및 시사점)
본 연구는 액션 기반의 월드 모델 사전 학습이 로봇 학습을 위한 강력하고 범용적인 Dynamics Priors를 구축하는 효과적인 경로임을 증명했습니다. 제안된 A2World는 단순한 비디오 생성 모델을 넘어, 시뮬레이터 중심의 정책 평가와 정책 중심의 제어 성능을 동시에 강화할 수 있는 이중 목적(dual-use)을 달성했습니다. 본 연구의 결과는 향후 다양한 환경에서 로봇의 일반화 성능을 높이고, 실시간 시뮬레이션 데이터를 통한 로봇 정책 학습의 효율성을 극대화하는 데 중요한 학계 및 산업적 시사점을 제공합니다.

Figure 7 — 장기 생성 결과 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] StaMo: Unsupervised Learning of Generalizable Robot Motion from Compact State Representation
- [논문리뷰] RealWonder: Real-Time Physical Action-Conditioned Video Generation
- [논문리뷰] DreamWorld: Unified World Modeling in Video Generation
- [논문리뷰] Beyond Language Modeling: An Exploration of Multimodal Pretraining
- [논문리뷰] FRAPPE: Infusing World Modeling into Generalist Policies via Multiple Future Representation Alignment
Review 의 다른글
- 이전글 [논문리뷰] Large-Scale Tunnel Air-Ground Collaboration With FLISP: Fast LiDAR-IMU Synchronized Path Planner
- 현재글 : [논문리뷰] Learning Transferable Dynamics Priors from Action to World Modeling
- 다음글 [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
댓글