[논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xinyu Wang, Chongbo Zhao, Fangneng Zhan, Yue Ma, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Bidirectional Diffusion Transformer (DiT): 전체 비디오 프레임 간의 양방향 Attention을 통해 고품질의 구조적 정보를 유지하는 사전 학습된 모델.
- Three-Stage Distillation Pipeline: Bidirectional Foundation Model의 편집 능력을 실시간 추론이 가능한 4-step Causal DiT로 단계적으로 이전하는 학습 프레임워크.
- AR-oriented Mask Cache: 스트리밍 추론 중 중복되는 배경 영역의 연산을 생략하고 토큰을 재사용하여 지연 시간을 줄이는 기법.
- DMD (Distribution Matching Distillation): 생성 과정을 적은 단계(4-step)로 압축하면서도 고품질의 출력을 유지하게 하는 distillation 기술.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실시간 스트리밍 비디오 편집 환경에서 발생하는 Attention distribution shift와 Spatial-temporal token redundancy 문제를 해결하고자 한다 [Figure 1]. 기존의 양방향 모델은 미래 정보에 접근할 수 없는 스트리밍 환경에서 직접 사용될 경우 구조적 정보 손실이나 시간적 불일치(flickering)를 유발한다. 또한, 매 프레임마다 전체 영역을 연산하는 것은 심각한 Latency를 야기하여 실시간 응용을 불가능하게 만든다. 저자들은 이러한 한계를 극복하기 위해 causal한 환경에서도 편집 품질을 유지하는 효율적인 프레임워크를 제안한다.
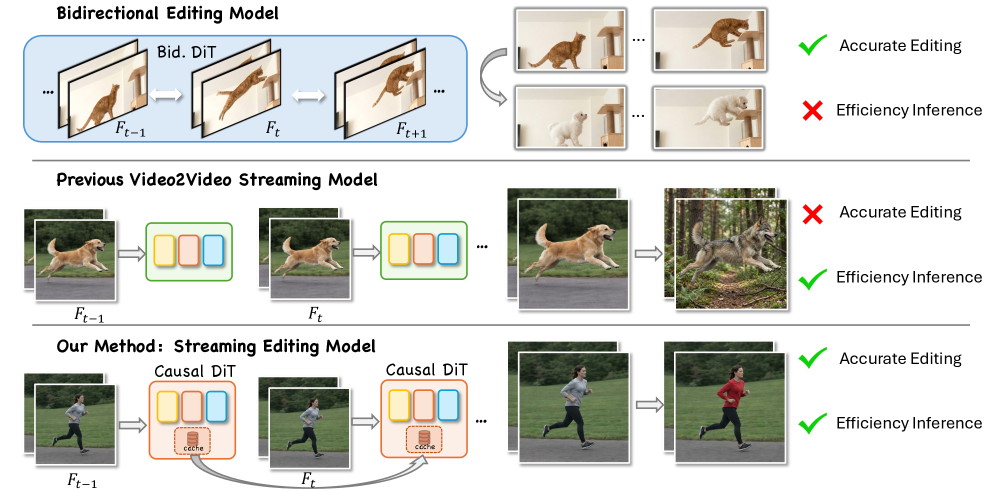
Figure 1 — 기존 패러다임과 제안 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Bidirectional prior의 편집 능력을 보존하면서 causal하게 작동하는 Three-stage distillation pipeline을 제안한다 [Figure 3]. 1단계에서는 Foundation Tuning을 통해 고품질 편집 Prior를 확보하고, 2단계에서는 Teacher Forcing을 사용하여 모델을 Causal DiT 구조로 전환하며, 3단계에서는 DMD를 도입하여 단 4 steps 만에 고품질 출력을 생성하도록 최적화한다. 실시간 배포를 가속화하기 위해 제안된 AR-oriented Mask Cache는 L2 distance를 기반으로 편집 영역과 배경을 분리하여, 배경 영역의 연산을 효과적으로 재사용한다 [Figure 4]. 실험 결과, 본 모델은 12.66 FPS의 빠른 Throughput을 달성하며 기존 스트리밍 모델 대비 우수한 시각적 품질을 보였다 [Table 1]. 특히, 제안된 기법은 Text Alignment 성능에서 경쟁 모델을 상회하며, 특히 배경의 시간적 일관성을 완벽하게 보존하는 성능을 입증하였다 [Figure 5].
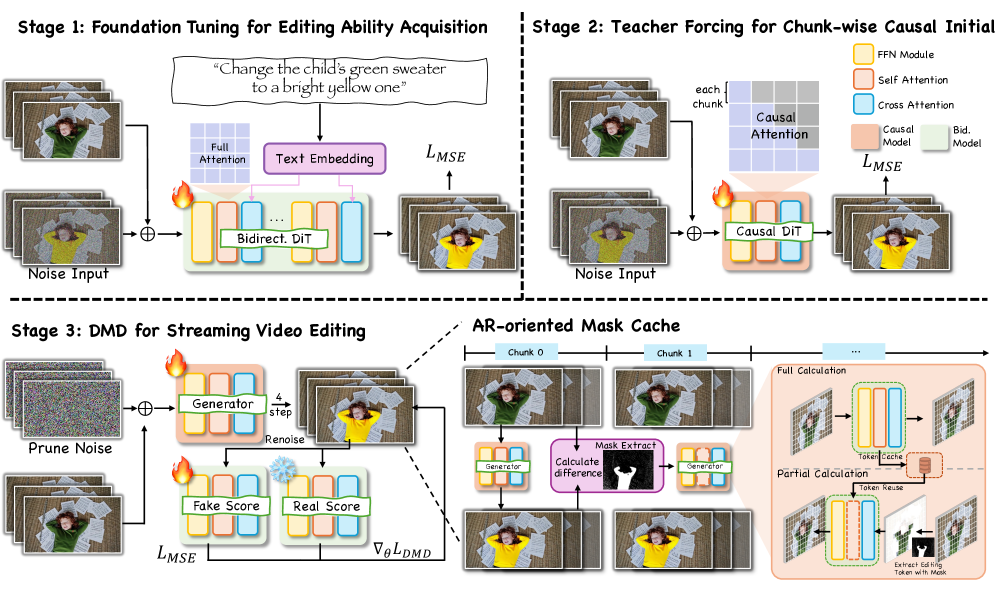
Figure 3 — 전체 프레임워크 아키텍처
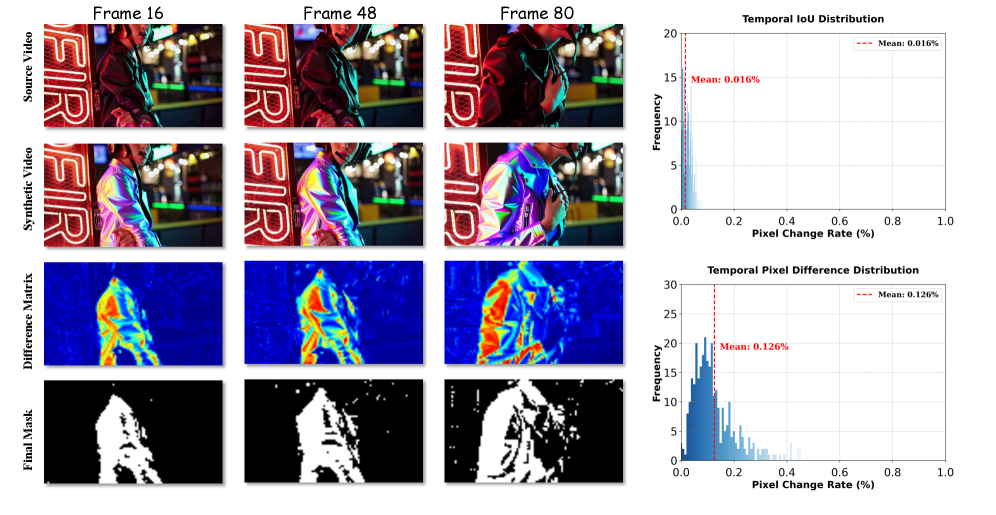
Figure 4 — Mask Cache 및 일관성 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고성능 양방향 편집 모델을 효율적인 단방향 스트리밍 에디터로 변환하는 새로운 접근 방식을 성공적으로 제시하였다. Three-stage distillation과 AR-oriented Mask Cache의 결합은 실시간성 확보와 높은 시각적 완성도라는 두 가지 핵심 요구사항을 동시에 만족시킨다. 이 연구는 향후 Augmented Reality 및 실시간 인터랙티브 미디어 생태계에서 비디오 편집 기술의 실용적 배포를 가속화하는 중요한 토대가 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Memento: Reconstruct to Remember for Consistent Long Video Generation
- [논문리뷰] minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
- [논문리뷰] Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
- [논문리뷰] FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
- [논문리뷰] Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
Review 의 다른글
- 이전글 [논문리뷰] Learning Transferable Dynamics Priors from Action to World Modeling
- 현재글 : [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
- 다음글 [논문리뷰] MIMFlow: Integrating Masked Image Modeling with Normalizing Flows for End-to-End Image Generation
댓글