[논문리뷰] minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Min Zhao, Hongzhou Zhu, Bokai Yan, Zihan Zhou, Yimin Chen, Wenqiang Sun, Kaiwen Zheng, Guande He, Xiao Yang, Chongxuan Li, Fan Bao, Jun Zhu
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- minWM: T2V(Text-to-Video) 또는 TI2V(Text-and-Image-to-Video) 기반 모델을 카메라 제어 가능한 실시간 인터랙티브 비디오 월드 모델로 변환하는 오픈소스 풀스택 프레임워크입니다.
- Causal Forcing/Causal Forcing++: 기존 Bidirectional Diffusion 모델을 실시간 추론이 가능한 Autoregressive(AR) 생성기로 변환하기 위한 증류(Distillation) 파이프라인입니다.
- Asymmetric DMD: Student 모델(AR 생성기)이 Teacher 모델(Bidirectional Diffusion 모델)의 고품질 분포를 모방하도록 최적화하는 학습 기법입니다.
- PRoPE (Projective RoPE): 비디오 생성 모델에 카메라의 내/외부 파라미터를 효과적으로 주입하여 카메라 궤적 제어 능력을 부여하는 방식입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 고품질 Video Foundation Model을 실시간 상호작용이 가능한 Interactive World Model로 전환하는 파이프라인의 부재 문제를 해결합니다. 최신 비디오 생성 모델들은 시각적 품질은 뛰어나지만, 실시간 인터랙션을 위해 필수적인 인과적(Causal) 생성과 낮은 Latency를 지원하지 못한다는 한계가 있습니다. 이러한 전환을 위해서는 데이터 구성부터 모델 증류, 실시간 추론까지 이어지는 복잡한 과정이 요구되나, 이를 통합한 공개된 프레임워크가 부족합니다. 저자들은 재현 가능하고 확장 가능한 오픈소스 파이프라인을 구축함으로써 비디오 월드 모델 연구의 효율성을 높이고자 합니다 [Figure 1].
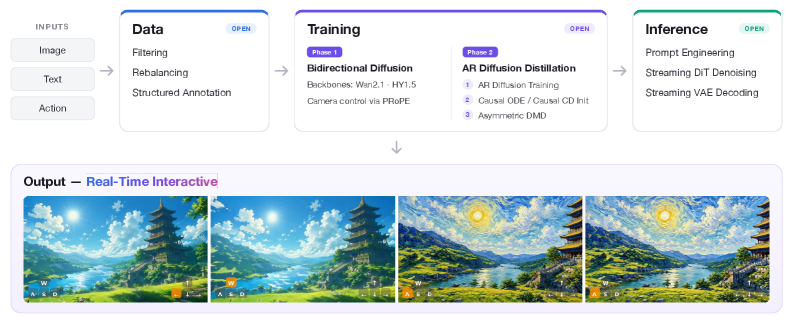
Figure 1 — minWM 전체 파이프라인
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 minWM 프레임워크를 통해 비디오 모델을 두 단계에 걸쳐 변환합니다. 첫 번째로, PRoPE 기법을 사용하여 Bidirectional Diffusion 모델에 카메라 제어 능력을 부여하는 Fine-tuning을 수행합니다. 두 번째로, Causal Forcing 또는 Causal Forcing++ 파이프라인을 도입하여, 모델을 Few-step AR 생성기로 증류합니다. 이 과정은 AR Diffusion Training, Causal ODE 또는 Causal CD 초기화, 그리고 최종적인 Asymmetric DMD 최적화 단계를 포함합니다 [Figure 2]. 실험 결과, 제안된 모델은 기존 방식 대비 HY1.5 백본에서 223.75배, Wan2.1 백본에서 236.64배의 First-frame Latency 감소를 달성하였습니다 [Table 1]. 또한, 학습 과정에서 카메라 궤적의 정확성과 최소 배치 사이즈(Batch size 16 이상 권장)가 제어 성능 확보에 결정적인 역할을 함을 정량적으로 입증하였습니다 [Figure 3, Figure 5].

Figure 2 — 카메라 제어 예시
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 실시간 인터랙티브 비디오 월드 모델을 위한 최초의 통합 오픈소스 프레임워크인 minWM을 제안하며, 다양한 비디오 Backbone 확장을 지원합니다. 이 연구는 복잡한 증류 파이프라인을 구조화하고 재현 가능한 레시피를 제공함으로써, 향후 비디오 기반 환경 시뮬레이션 및 인터랙티브 콘텐츠 연구의 기반을 마련했습니다. 향후 포즈 제어 등 다양한 제어 조건으로의 확장성을 확보하여 학계와 산업계의 실시간 비디오 월드 모델 연구를 가속화할 것으로 기대됩니다.
Part 2: 중요 Figure 정보

Figure 5 — 배치 사이즈 영향
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MetaView: Monocular Novel View Synthesis with Scale-Aware Implicit Geometry Priors
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
- [논문리뷰] Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
- [논문리뷰] Latent Spatial Memory for Video World Models
- [논문리뷰] StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
Review 의 다른글
- 이전글 [논문리뷰] YoCausal: How Far is Video Generation from World Model? A Causality Perspective
- 현재글 : [논문리뷰] minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
- 다음글 [논문리뷰] A Topology-Aware Spatiotemporal Handover Framework for Continuous Multi-UAV Tracking
댓글