[논문리뷰] MIMFlow: Integrating Masked Image Modeling with Normalizing Flows for End-to-End Image Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yang Chen, Xiaowei Xu, Shuai Wang, Xinwen Zhang, Qiushi Guo, Tiezheng Ge, Limin Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- MIM (Masked Image Modeling): 이미지의 일부를 마스킹하고 이를 재구성함으로써 구조적 특징을 학습하는 자기지도 학습 패러다임입니다.
- Normalizing Flow (NF): 데이터를 단순한 사전 분포에서 복잡한 데이터 분포로 변환하는 가역적이고 미분 가능한 변환 모델입니다.
- Learnable Token Bottleneck: 고정된 수의 학습 가능한 쿼리 토큰을 사용하여 입력 이미지로부터 글로벌 시맨틱 정보를 압축 추출하는 메커니즘입니다.
- Principled Decoupling: 생성 과정을 저주파 시맨틱 매니폴드(NF 담당)와 고주파 텍스처 합성(디코더 담당)으로 분리하는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Normalizing Flows (NFs)의 엄격한 가역성이 저수준 픽셀 디테일에 모델 용량을 과도하게 소모하게 하여, 고수준 시맨틱 구조를 포착하는 데 한계가 있다는 문제를 해결하고자 합니다. 기존의 MIM 기반 생성 모델들은 토크나이저를 독립적인 전처리 모듈로 취급하여 생성 프로세스와 분리되어 있다는 단점이 존재합니다 [Figure 1]. 이러한 모듈형 접근 방식은 표현 학습과 생성 과정 간의 불일치를 초래하며, 결국 NF의 잠재 공간 최적화를 저해합니다. 따라서 저자들은 시맨틱 표현, 픽셀 재구성, 그리고 생성 흐름을 동시에 최적화하는 통합된 End-to-End 프레임워크가 필요하다고 주장합니다.
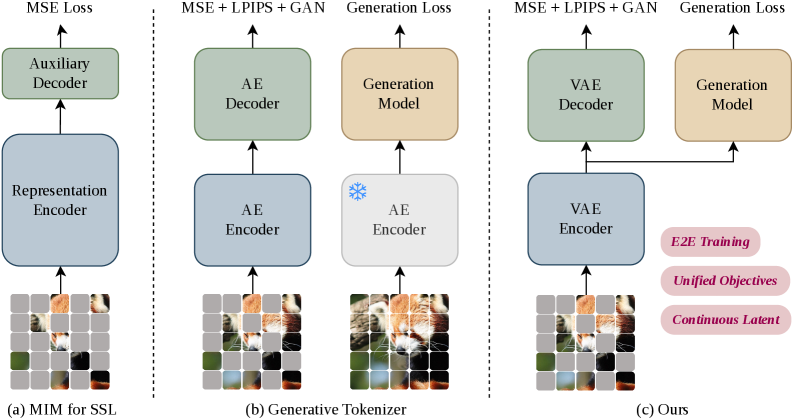
Figure 1 — 기존 패러다임과 MIMFlow 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 MIMFlow를 제안하여 시맨틱 추출을 위한 Masked Encoder, 밀도 추정을 위한 Latent Normalizing Flow, 그리고 텍스처 합성을 위한 Generative Decoder를 통합적으로 학습시킵니다 [Figure 2]. 제안 방법론은 학습 가능한 Learnable Token 병목 구조를 통해 입력된 마스킹 이미지로부터 고정 길이의 시맨틱 잠재 변수를 추출하며, 이를 통해 NF가 픽셀 단위의 노이즈가 아닌 간결한 시맨틱 매니폴드에 집중하도록 유도합니다. 실험 결과, MIMFlow-L은 ImageNet 256×256 벤치마크에서 기존의 SimFlow-L 대비 FID를 3.72에서 2.50으로 32.8% 개선하는 압도적인 성능을 보였습니다 [Table 3]. 또한, 단 128개의 토큰만을 사용하여 표준적인 256개 토큰 사용 모델들보다 더 우수한 효율성을 확보했으며, 71.3%의 Linear Probing Accuracy를 달성하여 잠재 공간의 시맨틱 우수성을 입증했습니다 [Figure 3].
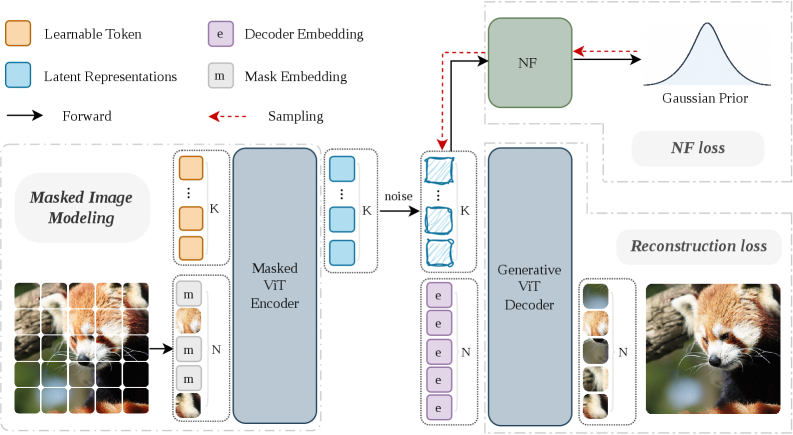
Figure 2 — MIMFlow 모델 구조

Figure 3 — MIMFlow 생성 샘플 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 MIM과 Normalizing Flows를 결합한 통합 End-to-End 생성 프레임워크인 MIMFlow를 제시하여 NF의 고질적인 용량 병목 문제를 성공적으로 해결하였습니다. 시맨틱과 텍스처 합성을 원칙적으로 분리하는 전략은 생성 모델의 효율성과 품질을 동시에 극대화합니다. 이 연구는 자기지도 학습과 확률적 생성 모델을 통합하는 새로운 패러다임을 제공하며, 향후 고해상도 생성 및 효율적인 시맨틱 이해 모델 발전에 중요한 시사점을 던집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Latent Reasoning with Normalizing Flows
- [논문리뷰] STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal Generation
- [논문리뷰] Normalizing Trajectory Models
- [논문리뷰] TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
- [논문리뷰] The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Review 의 다른글
- 이전글 [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
- 현재글 : [논문리뷰] MIMFlow: Integrating Masked Image Modeling with Normalizing Flows for End-to-End Image Generation
- 다음글 [논문리뷰] Monte Carlo Energy Aggregation for Mobile 3D Gaussian Splatting
댓글