[논문리뷰] Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xiaokun Feng, Jiashu Zhu, Meiqi Wu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Train-Free: 별도의 추가적인 모델 학습(Tuning) 없이, 기학습된 Foundation model의 능력을 활용하여 추론 단계에서만 영상 길이를 확장하는 방식을 의미합니다.
- Frame-level Autoregressive Generation: 비디오를 프레임 단위로 생성하며, 생성된 프레임이 다음 프레임 생성을 위한 컨텍스트(Queue)로 사용되는 방식을 지칭합니다.
- Two-Stage Training-Inference Alignment (TTA): 추론 과정에서의 과도한 노이즈 분포 차이(Noise span)를 완화하기 위해 제안된 두 단계의 정렬 메커니즘입니다.
- Dual Consistency Enhancement (DCE): 생성된 비디오의 시간적 일관성을 확보하기 위해 사용되는 보완적 기법들로, Self-reflection과 Long-range frame guidance로 구성됩니다.
- Noise span: 추론 과정에서 모델에 입력되는 잠재 변수(Latents)들의 노이즈 수준 차이를 의미하며, 이 격차가 클수록 생성 품질이 저하됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Foundation video generation 모델을 활용하여 학습 없이 무한한 길이의 영상을 일관성 있게 생성하는 것을 목표로 합니다. 기존의 Frame-level autoregressive 접근 방식(예: FIFO-Diffusion)은 고정된 메모리 소비라는 장점이 있으나, 학습 시의 노이즈 수준과 추론 시 입력되는 노이즈 수준 사이의 간극(Training-Inference Gap)으로 인해 내용이 드리프트되거나 시각적 아티팩트가 발생하는 문제가 있습니다 [Figure 2]. 또한, 기존 방법들은 장기적인 시간 일관성(Long-term consistency)을 확보하기 위한 모델링이 부족하여, 긴 영상 생성 시 시공간적 불일치가 발생하는 한계가 있습니다. 이를 해결하기 위해 저자들은 MIGA라는 새로운 프레임워크를 제안합니다.
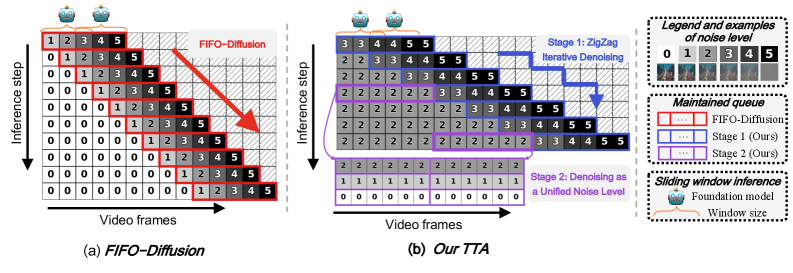
Figure 2 — TTA 매커니즘 프레임워크 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문이 제안하는 MIGA는 Two-Stage Training-Inference Alignment (TTA)와 Dual Consistency Enhancement (DCE) 메커니즘을 통해 위 문제들을 해결합니다 [Figure 2, Figure A1]. TTA는 첫 번째 단계에서 Zigzag 구조를 통해 노이즈 변화율을 낮추고, 두 번째 단계에서 모든 잠재 변수의 노이즈 수준을 동일하게 정렬하여 학습 조건과 추론 조건을 동기화합니다. DCE는 초기 고노이즈 프레임의 일관성을 스스로 평가하고 보정하는 Self-reflection과, 이전에 생성된 원거리 프레임을 현재 생성 과정에 참조 정보로 활용하는 Long-range frame guidance를 포함합니다 [Figure 3, Figure 4].
VBench 실험 결과, MIGA는 VideoCrafter2 기반 모델에서 FreeLong 대비 우수한 S.C.와 B.C. 성능을 보였으며, Wan2.1 기반 모델에서도 FIFO-Diffusion 대비 모든 지표에서 향상된 성능을 기록하였습니다 [Table 1]. 특히 NarrLV 벤치마크에서도 더욱 풍부한 서사 표현력을 입증하였으며, ablation study를 통해 TTA와 DCE의 도입이 각각 Overall Score(O.S.)를 2.03%, 1.73% 향상시켰음을 확인하였습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 학습 비용 없이도 높은 시간적 일관성과 풍부한 서사를 갖춘 장편 영상을 생성할 수 있는 MIGA 프레임워크를 제시하였습니다. 저자들이 제안한 노이즈 수준 정렬과 실시간 일관성 보정 메커니즘은 기존 FIFO-Diffusion 기반의 한계를 극복하며, 고비용의 학습 없이도 강력한 비디오 생성 모델을 확장할 수 있음을 입증했습니다. 이 연구는 영화 제작, 게임 개발, 가상 세계 시뮬레이션 등 장편 비디오 생성의 상업적 활용 가능성을 크게 높였으며, 향후 Test-Time Scaling (TTS)을 비디오 도메인에 적용하는 데 중요한 기반이 될 것입니다.

Figure 1 — MIGA를 통한 무한 프레임 생성 예시
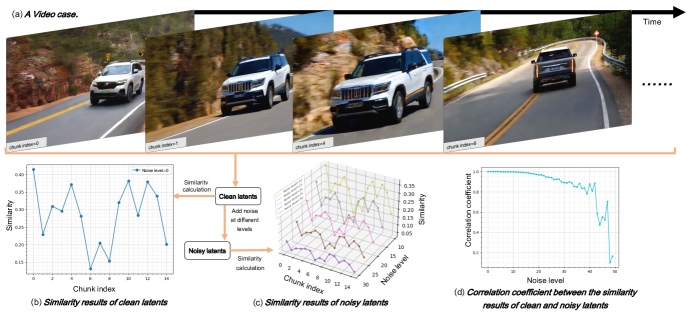
Figure 3 — Self-reflection 모델링 통찰
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Memento: Reconstruct to Remember for Consistent Long Video Generation
- [논문리뷰] FrameDiffuser: G-Buffer-Conditioned Diffusion for Neural Forward Frame Rendering
- [논문리뷰] LongVie: Multimodal-Guided Controllable Ultra-Long Video Generation
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
- [논문리뷰] FadeMem: Distance-Aware Memory Consolidation for Autoregressive Video Diffusion
Review 의 다른글
- 이전글 [논문리뷰] DrawMotion: Generating 3D Human Motions by Freehand Drawing
- 현재글 : [논문리뷰] Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
- 다음글 [논문리뷰] Evaluating Temporal Semantic Caching and Workflow Optimization in Agentic Plan-Execute Pipelines
댓글