[논문리뷰] Guava: An Effective and Universal Harness for Embodied Manipulation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haowen Liu, Xirui Li, Shaoxiong Yao, Peng Shi, Tianyi Zhou, Jia-Bin Huang, Furong Huang, Jiayuan Mao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Harness: 로봇의 감각(perception), 계획(planning), 제어(control) 모듈을 언어 모델이 활용할 수 있도록 연결하는 인터페이스 체계입니다.
- ReAct: 언어 모델이 추론(Reasoning)과 행동(Action)을 반복적으로 수행하여, 환경의 피드백을 기반으로 계획을 수정하고 오류에서 복구하도록 하는 워크플로우입니다.
- Semantic Action Abstractions: 로봇의 복잡한 저수준 제어(joint-space control) 대신,
grasp(),move()와 같이 의미론적으로 명확한 고수준 도구를 사용하는 방식입니다. - Policy Distillation: 고성능(Proprietary) 모델의 지식과 행동 패턴을 보다 작은 규모의 모델(Compact model)로 이전하여 동일한 수준의 성능을 구현하는 학습 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Embodied Manipulation 환경에서 복잡한 저수준 제어를 직접 학습하는 기존의 End-to-End VLA(Vision-Language-Action) 모델의 데이터 비효율성과 낮은 복구 능력을 해결하기 위해 Guava 프레임워크를 제안합니다. 기존 연구들은 대규모 로봇 데모 데이터에 의존해야 하며, 실행 중 발생하는 오류에 대응하기 어렵다는 한계가 있습니다 [Figure 1]. 저자들은 고수준 추론에 강점이 있는 VLM을 활용하여 외부 도구 모듈을 호출하는 'Harness' 중심의 접근 방식을 통해, 훨씬 적은 데이터로도 범용적이고 강인한 로봇 에이전트를 구축하고자 합니다.
Figure 1 — Guava 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 효율적인 Embodied Agent를 위해 iterative ReAct 루프, semantic action abstractions, 그리고 multimodal observations라는 세 가지 핵심 설계 원칙을 도출하였습니다 [Figure 2]. 이러한 원칙을 바탕으로, 저자들은 Frontier VLM의 데이터를 활용해 2,000개 미만의 시뮬레이션 trajectory만으로 Guava-Agent-4B(4B 파라미터 모델)를 학습시키는 효율적인 파이프라인을 구축하였습니다 [Figure 3]. 실험 결과, Guava-Agent-4B는 시뮬레이션 및 Real-world 환경에서 전체 성공률 75.6%를 기록하며, 기존 Frontier 모델인 GPT-5.4(70.2%)를 상회하는 성능을 보였습니다 [Table 2]. 특히, GRPO(Group Relative Policy Optimization)를 포함한 RL post-training 적용 시 긴 호흡의 과제(Long-horizon task)에서의 성공률이 비약적으로 향상되었으며, 학습된 모델은 보지 못한 환경이나 실행 오류 상황에서도 우수한 Zero-shot 복구 능력을 입증하였습니다 [Figure 4, 6].
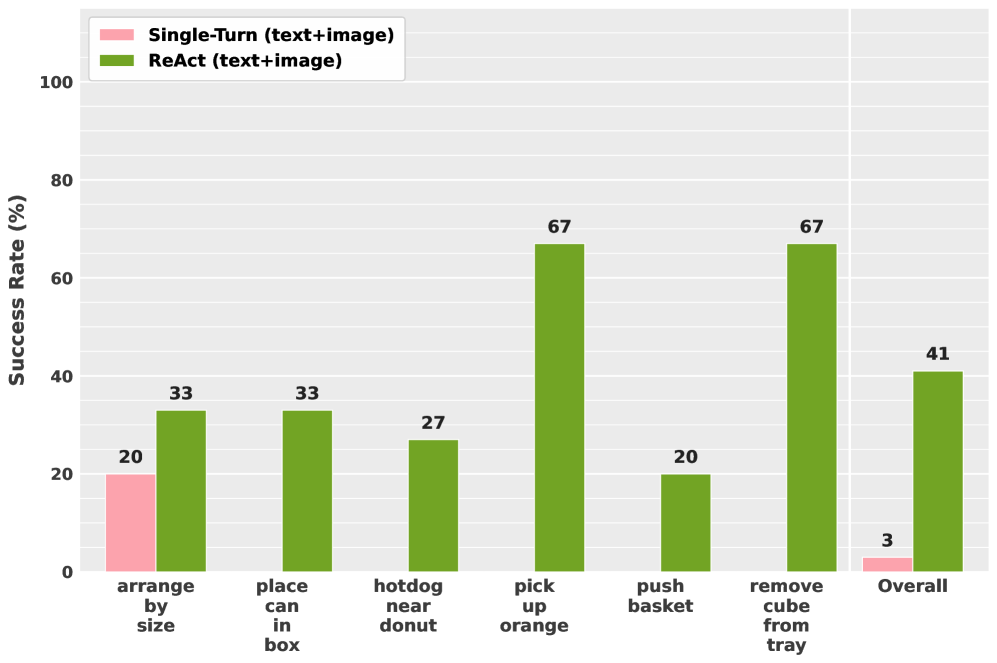
Figure 2 — Harness 설계 원칙 비교
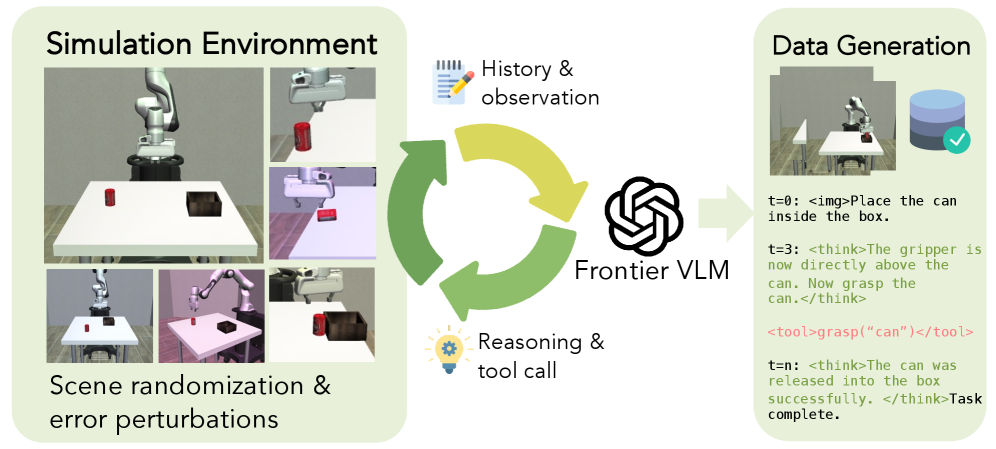
Figure 3 — 정책 증류를 위한 데이터 생성 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고도로 설계된 Harness가 Embodied Manipulation에서 강력한 모델-애그노스틱 인터페이스로 작용할 수 있음을 입증하였습니다. Guava는 소형 오픈소스 모델이 최소한의 데이터로도 대규모 독점 모델에 필적하는 embodied 능력을 확보할 수 있는 경로를 제시합니다. 이는 로봇 학습 분야에서 값비싼 데이터 수집 비용을 절감하고, 다양한 로봇 플랫폼에 보편적으로 적용 가능한 실용적인 에이전트 개발 모델로서 학계와 산업계에 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
- [논문리뷰] CodeV: Code with Images for Faithful Visual Reasoning via Tool-Aware Policy Optimization
- [논문리뷰] MM-BrowseComp: A Comprehensive Benchmark for Multimodal Browsing Agents
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
Review 의 다른글
- 이전글 [논문리뷰] From Trainee to Trainer: LLM-Designed Training Environment for RL with Multi-Agent Reasoning
- 현재글 : [논문리뷰] Guava: An Effective and Universal Harness for Embodied Manipulation
- 다음글 [논문리뷰] IndustryBench-MIPU: Benchmarking Multi-Image Attribute Value Extraction for Industrial Products
댓글