[논문리뷰] IndustryBench-MIPU: Benchmarking Multi-Image Attribute Value Extraction for Industrial Products
링크: 논문 PDF로 바로 열기
저자: Haonan Qi, Jin Cao, Yongqi Zhang, Xintong Wang, Weidong Tang, Bin Chen, Chengfu Huo, Haojun Pan, Hengyu You, Jing Li, Yingde Wang, Liang Ding
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Attribute Value Extraction (AVE): 제품 이미지와 텍스트로부터 구조화된 속성-값(property-value) 쌍을 추출하는 작업입니다.
- Completeness Gap: 모델이 개별 이미지 인식에는 능숙하지만, 복수의 이미지에 분산된 정보를 통합하여 제품 전체의 사양을 완전히 추출하지 못하는 성능 격차를 의미합니다.
- MLLM (Multimodal Large Language Models): 텍스트와 비주얼 데이터를 동시에 처리하여 산업용 제품의 기술 사양을 이해하고 분석하는 모델입니다.
- Stratified Sampling: 데이터셋 구축 시 범주별 불균형을 해소하기 위해 각 leaf-level 카테고리에서 고정된 수의 제품을 균형 있게 샘플링하는 기법입니다.
- Multi-Model Consensus: 5개의 서로 다른 MLLM이 독립적으로 수행한 결과물을 결합하여 벤치마크의 정답 세트(recall ceiling)를 생성하는 구축 방식입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존의 일반적인 시각적 추론 벤치마크가 산업용 제품의 복잡하고 지식 집약적인 사양 이해를 다루지 못한다는 한계에서 출발합니다. 산업용 제품은 specification tables, nameplates, technical drawings 등 다양한 형식으로 정보가 파편화되어 있으며, 이를 정확히 추출하기 위해서는 domain knowledge와 복수의 이미지에 걸친 evidence integration이 필수적입니다. 그러나 기존 모델들은 이러한 다중 이미지 환경에서의 정보 통합 능력이 부족하며, 이를 평가할 체계적인 벤치마크조차 부재한 상황입니다. 저자들은 이러한 문제를 해결하기 위해 대규모 다중 이미지 산업 제품 이해 벤치마크인 IndustryBench-MIPU를 제안하며, [Figure 1]에서 제시된 바와 같이 텍스트 인식, 시각적 추론, 도메인 지식, 정보 통합이라는 4대 핵심 도전 과제를 해결하고자 합니다.

Figure 1 — 산업용 제품 사양 추출의 4대 핵심 도전 과제를 시각적으로 요약
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 산업용 제품의 속성 추출을 위해 4,559개 제품, 27,652개 이미지, 103,703개 주석을 포함하는 대규모 데이터셋인 IndustryBench-MIPU를 구축하였습니다. 해당 프레임워크는 [Figure 2]와 같이 5개의 모델이 독립적으로 수행하는 3단계 파이프라인(Entity Recognition, Image Filtering, Per-Image Extraction)과 3단계 품질 보증(Frontier Model Audit, Gold-Standard Cross-Check, Human Verification)으로 구성됩니다. 주요 실험 결과, Gemini 3.1 Pro가 multi-image 환경에서 65.1%의 F1 score로 가장 우수한 성능을 보였으나, 모든 모델이 공통적으로 86–94%의 높은 precision을 유지함에도 불구하고 recall은 절반 수준에 머무르는 높은 수준의 completeness gap을 보였습니다. [Table 2]에 따르면, single-image 환경에서 multi-image 환경으로 전환 시 recall이 15–34% 포인트 감소하며, 이는 모델이 이미지 내의 특정 정보 인식에는 강하나, 파편화된 다중 이미지 정보를 통합하는 능력이 부족함을 시사합니다. 또한 [Table 4]를 통해 모델의 active parameter scale이 커질수록 multi-image 성능이 급격히 향상됨을 확인하였습니다.
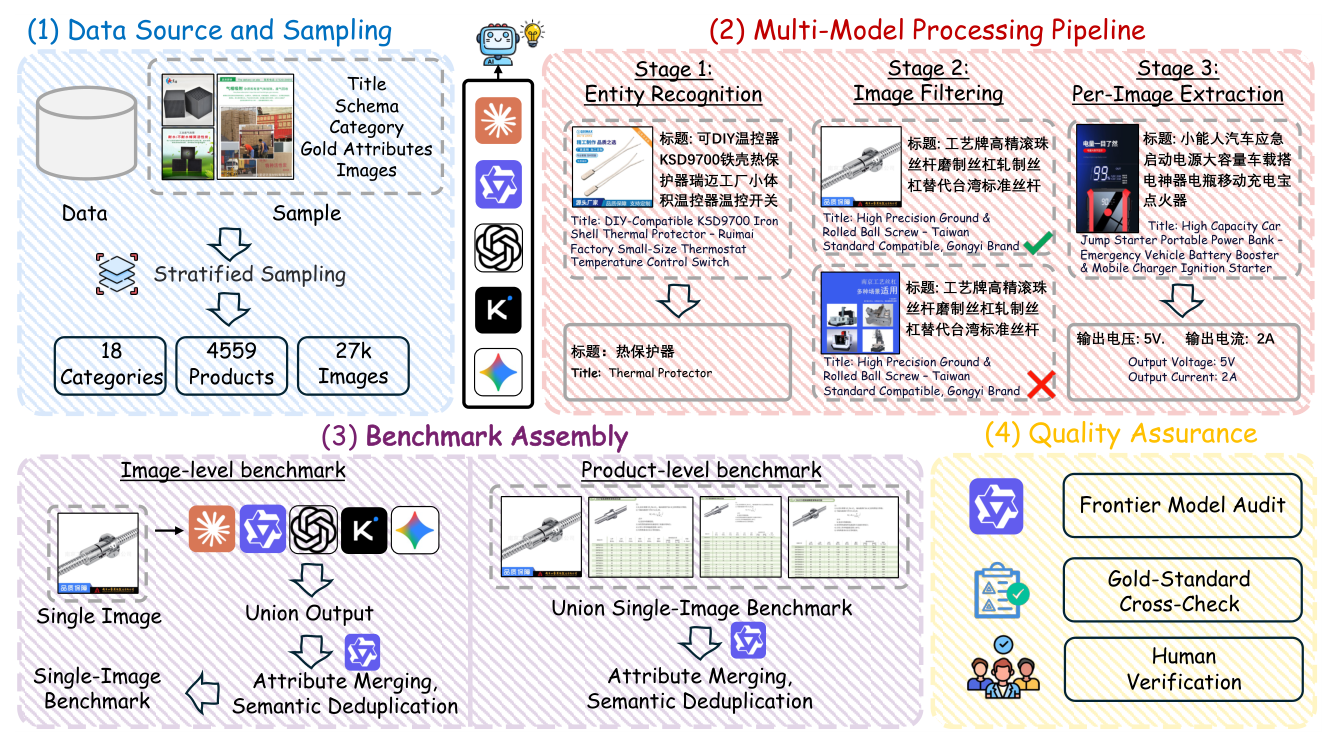
Figure 2 — 데이터셋 구축 및 품질 보증 과정을 나타내는 전체 아키텍처 다이어그램
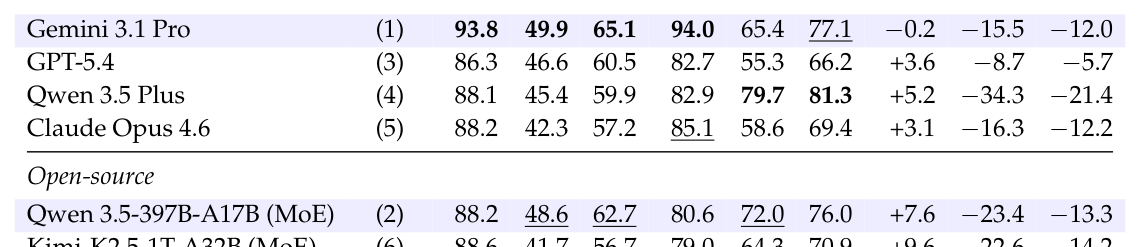
Table 2 — 제안된 벤치마크에서의 주요 모델별 정량적 성능 지표 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 산업용 제품의 다중 이미지 사양 추출을 위한 최초의 대규모 벤치마크를 정립하고, 현재의 고성능 MLLM들이 정보의 정확도(precision)보다는 전체 사양의 완성도(completeness) 측면에서 결정적인 병목 현상을 겪고 있음을 입증하였습니다. 이러한 결과는 향후 다중 이미지 추론 모델이 나아가야 할 방향이 단순히 개별적인 인식을 넘어, 복잡한 산업 도메인에서의 정보 통합 및 추론 역량 강화에 있음을 시사합니다. 제안된 데이터셋과 코드는 오픈 소스로 공개되어, 복잡한 멀티모달 환경에서의 의사결정 보조 도구 개발을 위한 핵심적인 학술적·산업적 테스트베드로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Beyond the Current Observation: Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
- [논문리뷰] Visual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
- [논문리뷰] LLM Agents Can See Code Repositories
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
- [논문리뷰] Late-Layer Fusion is Enough: Dual-Path Vision Token Routing for Multimodal Large Language Models under Visual Saturation
Review 의 다른글
- 이전글 [논문리뷰] Guava: An Effective and Universal Harness for Embodied Manipulation
- 현재글 : [논문리뷰] IndustryBench-MIPU: Benchmarking Multi-Image Attribute Value Extraction for Industrial Products
- 다음글 [논문리뷰] Kairos: A Native World Model Stack for Physical AI
댓글