[논문리뷰] From Trainee to Trainer: LLM-Designed Training Environment for RL with Multi-Agent Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chao Chen, Chengzu Li, Zhiwei Li, Yinhong Liu, Zhijiang Guo et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- LLM-as-Environment-Engineer: RL 학습 과정에서 현재 policy model이 실패 trajectories와 환경 통계치를 분석하여 다음 학습 단계의 환경 설정을 스스로 재구성하는 프레임워크.
- MAPF-FrozenLake: Multi-Agent Path Finding(MAPF) 문제를 해결하기 위해 고안된 제어 가능한 테스트베드로, grid-size, hole density, conflict ratio 등을 파라미터화하여 조절할 수 있음.
- GRPO (Group Relative Policy Optimization): Critic 모델 없이 policy model이 자체적으로 multiple trajectories를 생성하고 비교하여 학습하는 RL 알고리즘.
- Valid Rate/Optimal Rate: 모델이 생성한 경로가 물리적 제약(충돌, 장애물 등)을 준수하는지(Valid), 그리고 최단 거리 혹은 최적 경로를 달성했는지(Optimal)를 측정하는 핵심 성과 지표.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 RL 학습 환경을 수동으로 설계하는 기존 파이프라인의 비효율성과 확장성 한계를 해결하고자 수행되었습니다. 기존의 RL 학습은 환경 설정이 고정되어 있거나, 전문가가 휴리스틱에 의존하여 학습 커리큘럼을 직접 조정해야 하므로 복잡한 시나리오에서의 일반화 및 최적화 능력이 저하되는 문제가 있습니다. 특히, 수집된 rollout 로그를 바탕으로 모델의 약점을 파악하고 다음 단계를 설계하는 과정이 병목 현상을 유발하므로, 모델이 스스로 학습 환경을 최적화하는 자동화된 적응형 프레임워크가 필수적입니다 [Figure 2].
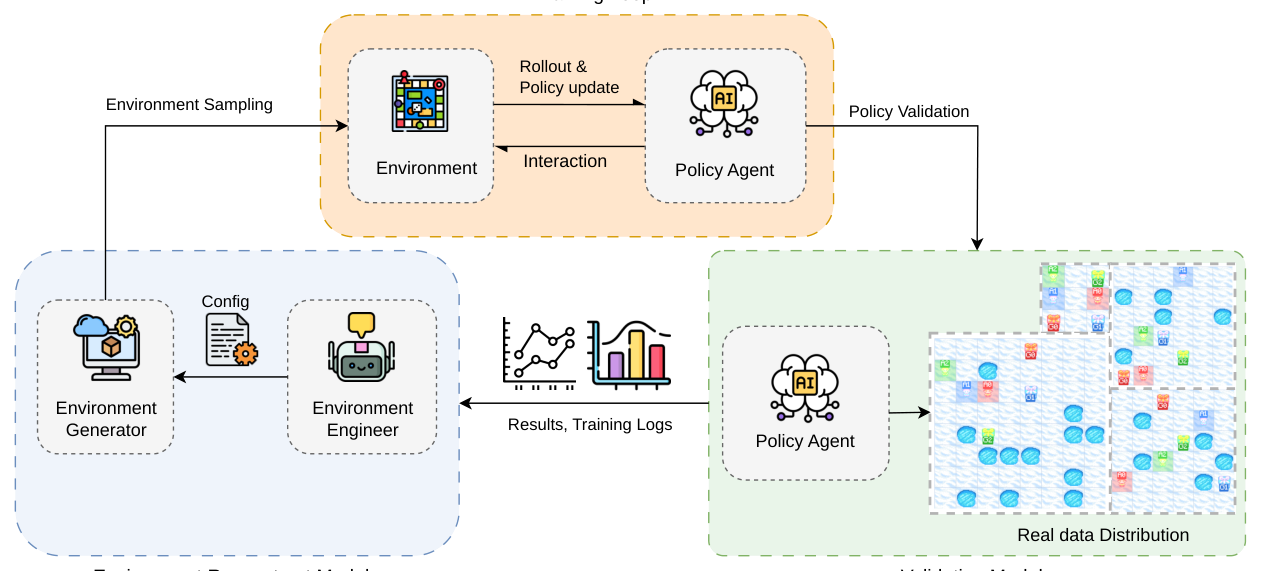
Figure 2 — 제안하는 LLM-as-Environment-Engineer의 전체적인 closed-loop 프로세스를 보여주는 핵심 아키텍처 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 제안하는 프레임워크는 각 RL 학습 단계 후, policy model이 자신의 수행 결과(failure breakdown 등)를 기반으로 환경 생성 파라미터를 수정하여 다음 학습을 위한 distribution을 reshape하는 closed-loop 방식을 채택합니다. 모델은 Qwen3-4B를 백본으로 사용하여 GRPO로 학습되며, 5가지 모듈(Failure breakdown, Guideline, History, Summary, Training details)의 결합을 통해 환경 설계의 근거를 마련합니다 [Figure 2]. 주요 실험 결과, 제안 모델은 3-agent에서 5-agent까지의 모든 benchmark에서 GPT-5.4, Gemini-3.1-Pro 등 대형 Proprietary LLM 모델들을 상회하는 성능을 보였습니다 [Table 2, 3, 4]. 특히, 제안 방법은 고정 환경에서 학습된 baseline 대비 valid rate에서 최대 +11.25점, optimal rate에서 최대 +5.59점의 큰 성능 향상을 기록하며, evidence-based adaptation이 단순한 difficulty scaling보다 효과적임을 입증했습니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 LLM이 환경 생성기의 설정을 스스로 재구성함으로써 자신의 약점을 보완하고 최적의 학습 환경을 조성할 수 있는 self-improving 학습 시스템의 토대를 마련하였습니다. 제안하는 LLM-as-Environment-Engineer 프레임워크는 RL 학습 과정에서 policy learning이 모델의 자기 진단 능력을 향상시키며, 이는 데이터의 물리적 실재감보다 환경 파라미터 제어를 통한 학습 분포의 최적화가 중요함을 시사합니다. 향후 본 연구는 복잡한 embodied agent 및 web environment를 넘어, 다양한 도메인의 RL 파이프라인 자동화에 기여할 것으로 기대됩니다.
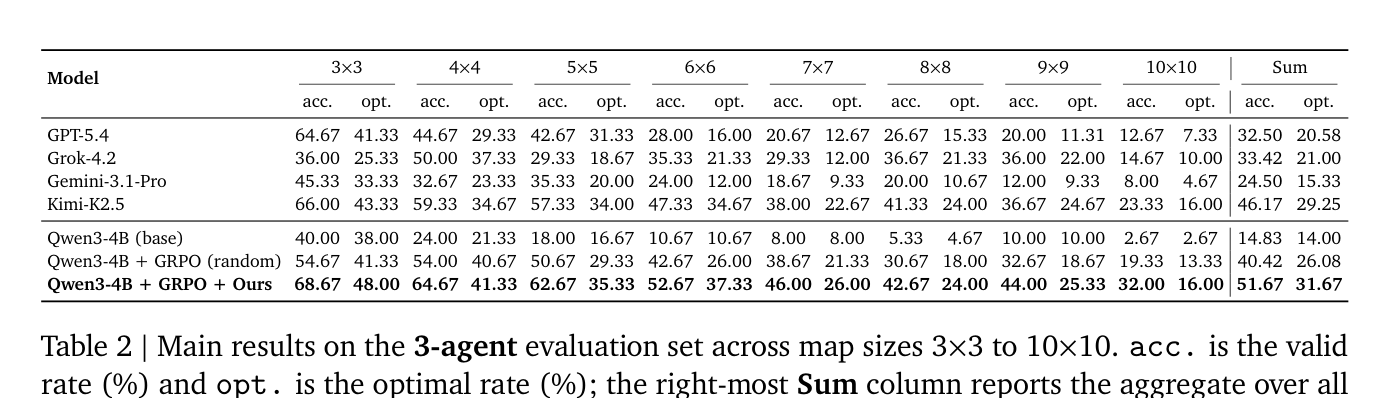
Table 2 — 기존 대형 모델 및 baseline과의 성능 비교를 통해 제안 방법론의 우수성을 입증하는 핵심 실험 결과
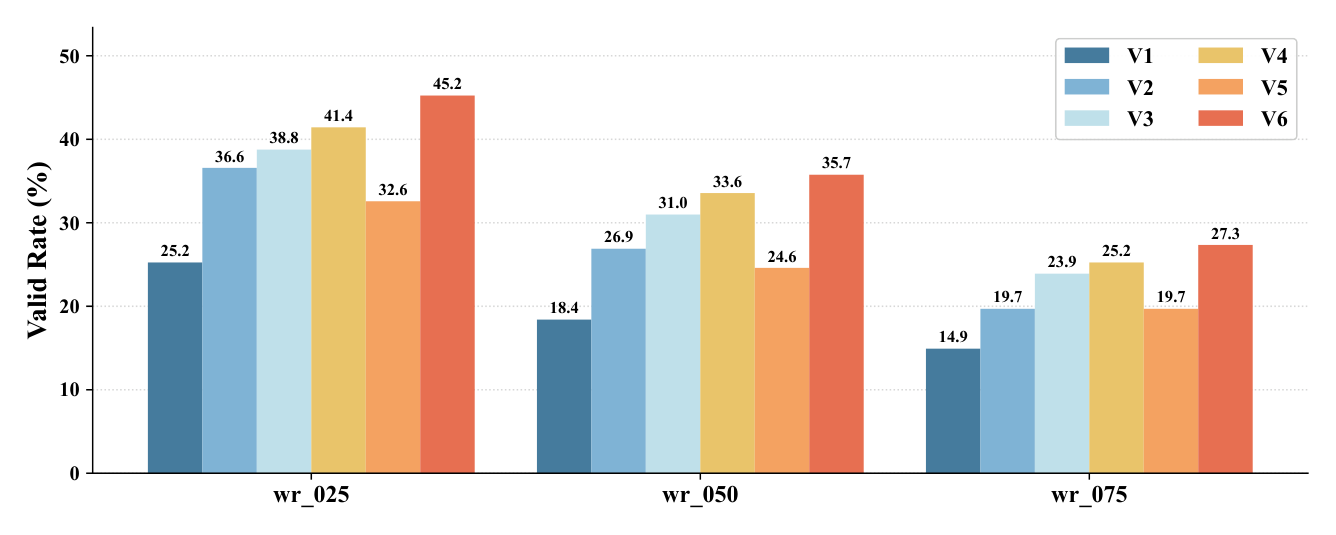
Figure 8 — 다양한 context variant(V1-V6) 간의 성능을 비교하여 최적의 프레임워크 설정을 증명하는 결과 그래프
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] BenchEvolver: Frontier Task Synthesis via Solution-Centric Evolution
- [논문리뷰] Self-Improving World Modelling with Latent Actions
- [논문리뷰] Self-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training
- [논문리뷰] SIMA 2: A Generalist Embodied Agent for Virtual Worlds
- [논문리뷰] Self-Improvement in Multimodal Large Language Models: A Survey
Review 의 다른글
- 이전글 [논문리뷰] Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
- 현재글 : [논문리뷰] From Trainee to Trainer: LLM-Designed Training Environment for RL with Multi-Agent Reasoning
- 다음글 [논문리뷰] Guava: An Effective and Universal Harness for Embodied Manipulation
댓글