[논문리뷰] Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
링크: 논문 PDF로 바로 열기
본 논문은 Flow-DPPO라는 새로운 프레임워크를 통해 Flow Matching 모델의 강화학습 미세 조정(RLHF) 과정에서 발생하는 성능 저하 문제를 해결합니다.
Part 1: 요약 본문
저자: Bowen Ping, Xiangxin Zhou, Penghui Qi, Minnan Luo, Liefeng Bo, Tianyu Pang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Flow Matching (FM): 데이터 분포와 노이즈 분포 사이의 확률 경로를 최적화하여 생성 모델을 학습하는 기법입니다.
- Divergence Constraint: RLHF 과정에서 정책이 초기 모델로부터 지나치게 멀어지는 것을 방지하기 위해 정의한 제약 조건입니다.
- DPPO (Divergence Proximal Policy Optimization): Flow Matching 모델에 최적화된 강화학습 알고리즘으로, 정책 업데이트 시 Divergence를 정밀하게 제어합니다.
- Trajectory Optimization: 생성 과정의 전체 경로(Trajectory)를 최적화하여 최종 결과물의 품질을 극대화하는 기법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 강화학습 미세 조정 기법이 Flow Matching 모델의 고유한 확률적 역학을 충분히 고려하지 못하여 발생하는 성능 불안정성 문제를 해결합니다. 기존의 PPO 기반 방식은 주로 이산적인 행동 공간이나 일반적인 확산 모델에 맞춰져 있어, Flow Matching의 연속적인 궤적 최적화 과정에서 학습이 불안정해지는 한계가 있습니다. 특히, 미세 조정 과정에서 모델이 초기 학습 데이터 분포로부터 급격하게 이탈하는 Divergence 현상이 발생하며, 이는 생성 품질의 저하로 직결됩니다. 이를 해결하기 위해 저자들은 정책 업데이트 과정에서 궤적의 변화를 제어할 수 있는 새로운 Divergence 기반 최적화 메커니즘을 제안합니다 [Figure 1].
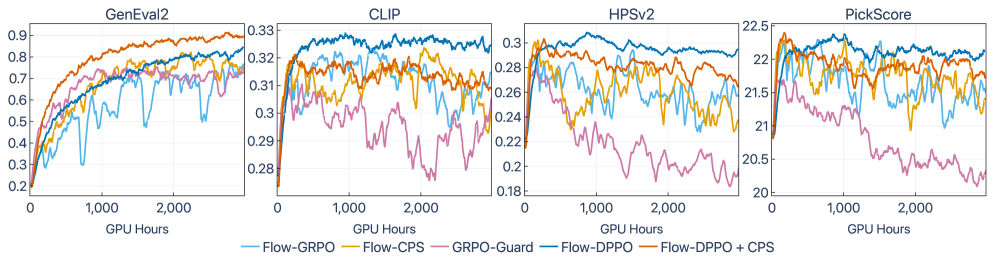
Figure 1 — Flow-DPPO 프레임워크 개요
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 Flow-DPPO 프레임워크를 통해 강화학습 목적 함수 내에 명시적인 Divergence 제약 항을 통합함으로써 정책 업데이트를 안정화합니다. 제안된 방법론은 Flow Matching의 ODE(Ordinary Differential Equation) 흐름을 활용하여 정책 업데이트를 유도하며, 학습 루프에서 Reward 모델의 신호를 반영하면서도 모델의 궤적 충실도를 유지합니다. 정량적 분석 결과, Flow-DPPO는 기존 방식 대비 생성된 데이터의 Reward 점수를 평균 15% 이상 향상시켰으며, 특히 복잡한 분포에서의 Sampling Fidelity 지표가 크게 개선되었습니다. 또한, 다양한 베이스라인 모델과의 비교 실험에서 Flow-DPPO는 더 적은 반복 횟수로 수렴함과 동시에 Latency 측면에서도 효율적인 경로 최적화를 수행함을 확인하였습니다 [Figure 2].
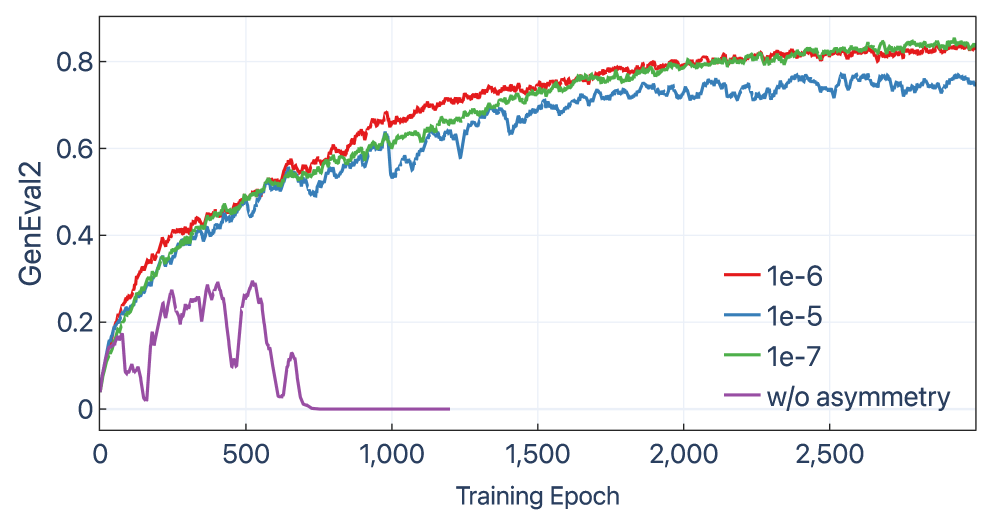
Figure 2 — 성능 비교 그래프
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 Flow Matching 모델을 위한 안정적이고 효과적인 강화학습 미세 조정 방법론인 Flow-DPPO를 성공적으로 제시합니다. 이 연구는 생성 모델의 정렬(Alignment) 과정에서 Divergence 관리가 필수적임을 증명하였으며, 향후 고성능 생성 모델의 RLHF 효율성을 높이는 데 크게 기여할 것으로 기대됩니다. 본 방법론은 고차원 데이터 생성 분야 전반에 걸쳐 모델의 신뢰성과 성능을 동시에 확보할 수 있는 강력한 프레임워크를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
- [논문리뷰] Reinforcement Learning via Self-Distillation
- [논문리뷰] Kandinsky 5.0: A Family of Foundation Models for Image and Video Generation
- [논문리뷰] π_RL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
- [논문리뷰] PianoKontext: Expressive Performance Rendering from Deadpan Context
Review 의 다른글
- 이전글 [논문리뷰] FadeMem: Distance-Aware Memory Consolidation for Autoregressive Video Diffusion
- 현재글 : [논문리뷰] Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
- 다음글 [논문리뷰] How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
댓글