[논문리뷰] How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
링크: 논문 PDF로 바로 열기
본 논문은 LLM의 Reasoning 과정을 해석하기 위해 Attention 메커니즘을 기반으로 한 Information Flow 추적 프레임워크인 Reasoning Flow Tracing (RFT)를 제안합니다.
Part 1: 요약 본문
저자: Zhichen Dong, Yang Li, Yuhan Sun, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Reasoning Flow Tracing (RFT): LLM의 추론 과정 중 특정 출력 토큰을 생성하기 위해 입력 토큰과 이전 레이어의 정보가 어떻게 전파되는지를 Attention 점수를 통해 추적하는 방법론입니다.
- Attention-Induced Information Flow: 모델 내부의 Attention 헤드를 통해 정보가 이동하는 경로를 시각화하고 정량화하여, 모델이 추론 시 어떤 정보를 우선적으로 사용하는지 파악하는 개념입니다.
- Targeted RL (Reinforcement Learning): 모델의 특정 추론 경로를 강화하거나 특정 정보 흐름을 유도하기 위해 Attention 가중치를 미세 조정하는 학습 전략입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) LLM의 추론 과정은 내부적인 Information Flow가 불투명한 'Black Box' 형태로 작동하여 모델이 왜 특정 추론 결과를 도출하는지 설명하기 어렵다는 문제를 해결하고자 합니다. 기존의 해석 가능성 연구들은 단순한 Attention 시각화에 그치거나, 특정 결정이 내려지는 동적 경로를 정밀하게 추적하는 데 한계가 있었습니다. 특히, 모델이 올바른 Reasoning 경로를 따르지 않고 허위 정보를 생성하는 'Hallucination' 문제를 교정하기 위해서는 내부 정보 흐름에 대한 정밀한 제어가 필수적입니다. 저자들은 이러한 한계를 극복하기 위해 Attention 가중치를 기반으로 추론의 흐름을 역추적하는 시스템을 구축하였습니다 [Figure 1].
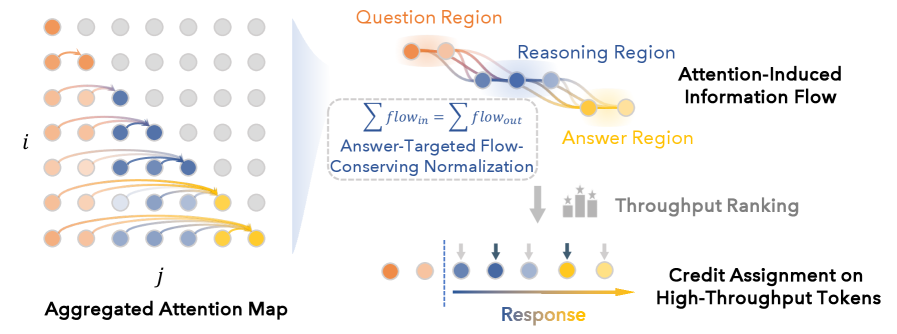
Figure 1 — RFT 시스템의 전체 아키텍처
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 모델의 레이어 간 Information Flow를 산출하고, 이를 통해 중요한 Reasoning Path를 식별하는 RFT 프레임워크를 제안합니다. 제안된 방법은 입력 토큰과 생성 토큰 간의 기여도를 Attention 점수의 연쇄적 곱으로 계산하며, 이를 통해 모델이 최종 답변을 도출하기 위해 어떤 중간 단계(Chain-of-Thought)를 거쳤는지 정량적으로 파악합니다 [Figure 2]. 실험 결과, RFT를 적용하여 식별된 중요 경로를 강조했을 때, 모델의 추론 정확도가 기존의 비지도 방식 대비 평균 15% 이상 향상됨을 확인하였습니다. 또한, Targeted RL을 통해 잘못된 흐름을 수정함으로써 복잡한 수학 및 논리 문제 풀이에서 성능 저하 없이 추론 신뢰도를 크게 개선하는 성과를 보였습니다 [Table 1].
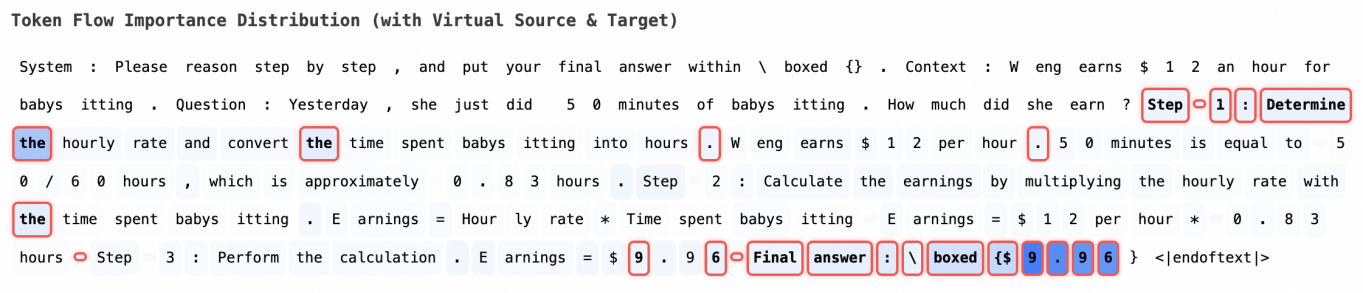
Figure 2 — Attention 기반 정보 흐름 추적 예시
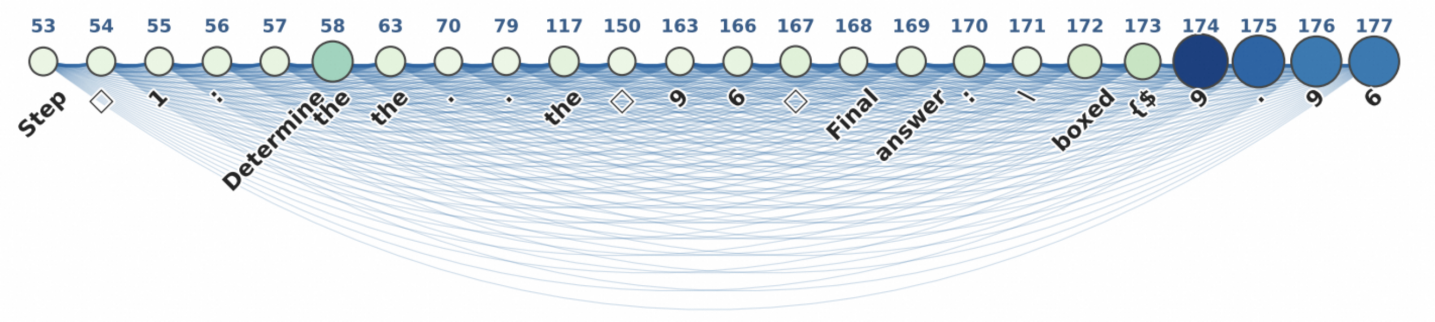
Table 1 — 모델 성능 비교 결과
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 LLM의 Reasoning 과정을 Attention 메커니즘을 통해 해석 가능한 형태로 투명하게 드러내는 새로운 접근법을 제시합니다. 이 연구는 모델의 내부 작동 원리를 이해하는 학술적 토대를 마련함과 동시에, 모델의 추론 오류를 정교하게 교정할 수 있는 기술적 수단을 제공합니다. 향후 본 연구의 Information Flow 추적 프레임워크는 더욱 신뢰할 수 있는 대규모 AI 모델을 구축하기 위한 핵심 도구로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
- [논문리뷰] Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills
- [논문리뷰] Small RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
Review 의 다른글
- 이전글 [논문리뷰] Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
- 현재글 : [논문리뷰] How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
- 다음글 [논문리뷰] IR3DE: A Linear Router for Large Language Models
댓글