[논문리뷰] From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
링크: 논문 PDF로 바로 열기
저자: Xitai Jiang, Zihan Tang, Wenze Lin, Yang Yue, Shenzhi Wang, Gao Huang
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): LLM 학습 시 정답 여부를 자동으로 검증할 수 있는 보상을 활용하여 모델의 추론 능력을 향상하는 강화학습 패러다임.
- Subproblem Curriculum: 어렵고 복잡한 문제를 여러 개의 검증 가능한 하위 문제(Subproblem)로 분해하여, 난이도가 낮은 문제부터 높은 문제 순으로 학습하도록 구성한 커리큘럼.
- Subproblem-level Normalization: 각 하위 문제의 수행 결과에 대해 독립적으로 보상을 정규화하고, 이를 토대로 토큰 단위의 세밀한 Advantage를 산출하는 학습 기법.
- Progress-Aware Correction: 하위 문제 수행 시 앞선 문제를 성공적으로 해결한 연속된 시퀀스에만 보상을 부여함으로써, 모델의 추론 단계를 올바르게 정렬하는 보상 보정 방식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 난도가 높은 추론 문제에 대해 기존의 RLVR 방식이 가지는 효율성 한계를 해결하고자 한다 [Figure 1]. 고난도 문제에서는 최종 정답에 도달하는 경로가 매우 희소하여, 모델이 중간 단계에서 올바른 추론을 수행하더라도 이를 학습 신호로 적절히 환원하기 어렵다. 기존 GRPO와 같은 샘플 단위의 Credit Assignment는 전체 rollout에 대해 하나의 보상만을 부여하므로, 거의 정답에 근접한 시도와 완전히 실패한 시도를 구분하지 못하는 문제가 발생한다. 결과적으로 고난도 문제 학습 시 모델은 정보가 부족한 gradient dead zone에 빠지게 되며, 이를 극복하기 위한 새로운 학습 신호 추출 전략이 요구된다.
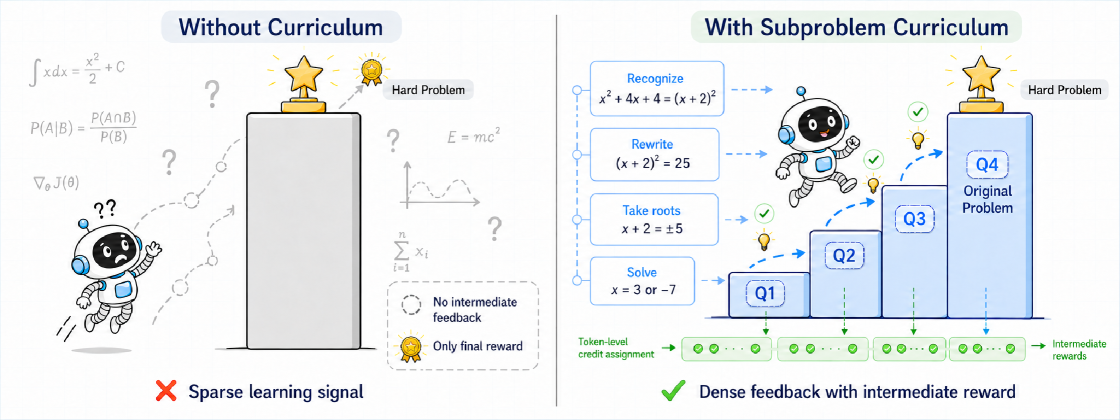
Figure 1 — SCRL 핵심 아이디어
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 고난도 문제를 검증 가능한 하위 문제 시퀀스로 분해하고, 이를 모델이 직접 풀게 함으로써 중간 보상을 추출하는 SCRL (Subproblem Curriculum Reinforcement Learning) 프레임워크를 제안한다 [Figure 2]. 저자들은 외부 LLM을 통해 참조 해결 과정을 하위 문제들로 분해하고, 학습 시 이를 하나의 on-policy rollout 내에서 순차적으로 풀도록 유도한다. 핵심 기술인 subproblem-level normalization은 각 위치에서의 상대적 성공 여부를 advantage로 산출하여, 태그 기반의 응답 포맷을 통해 토큰 단위로 세밀하게 크레딧을 할당한다 [Figure 3]. 또한 mixed-group training을 도입하여 curriculum rollout과 일반적인 원본 문제 풀이를 병행 학습함으로써 프롬프트 불일치를 최소화한다. 실험 결과, SCRL은 7개의 수학적 추론 벤치마크에서 기존 GRPO 대비 Qwen3-4B-Base 모델 기준 +4.1점, Qwen3-14B-Base 모델 기준 +1.9점의 평균 성능 향상을 보였다 [Table 1]. 특히 AIME24, AIME25, IMO-Bench와 같은 고난도 벤치마크에서 pass@1 및 pass@64 지표 기준 각각 +3.7, +4.6의 탁월한 개선을 기록하여, 어려운 문제에 대한 탐색 효율성을 입증하였다.
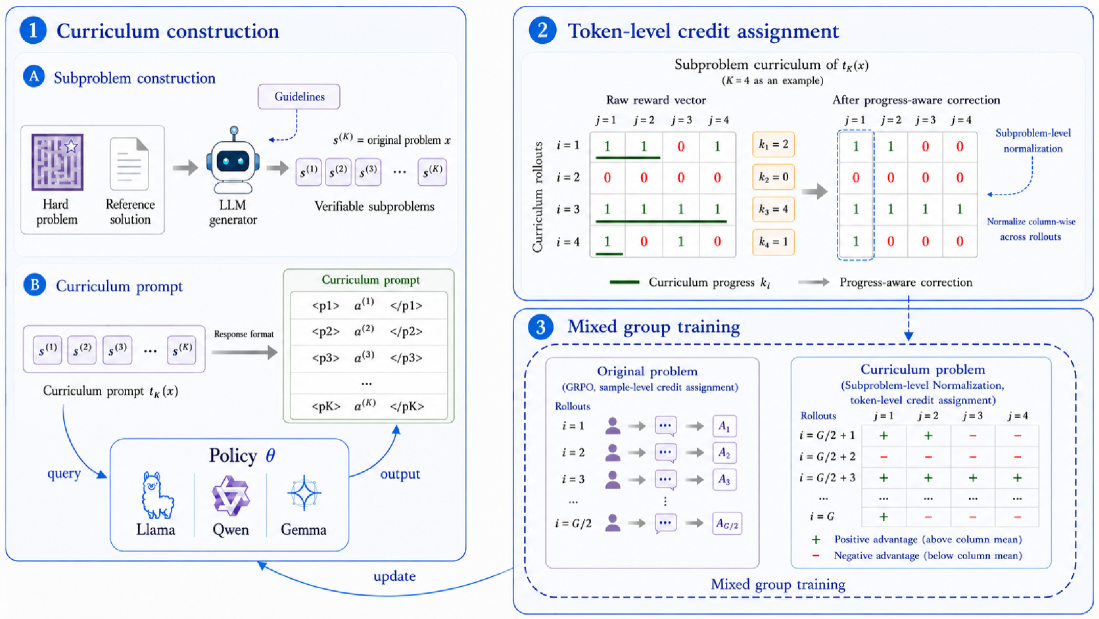
Figure 2 — SCRL 전체 프레임워크
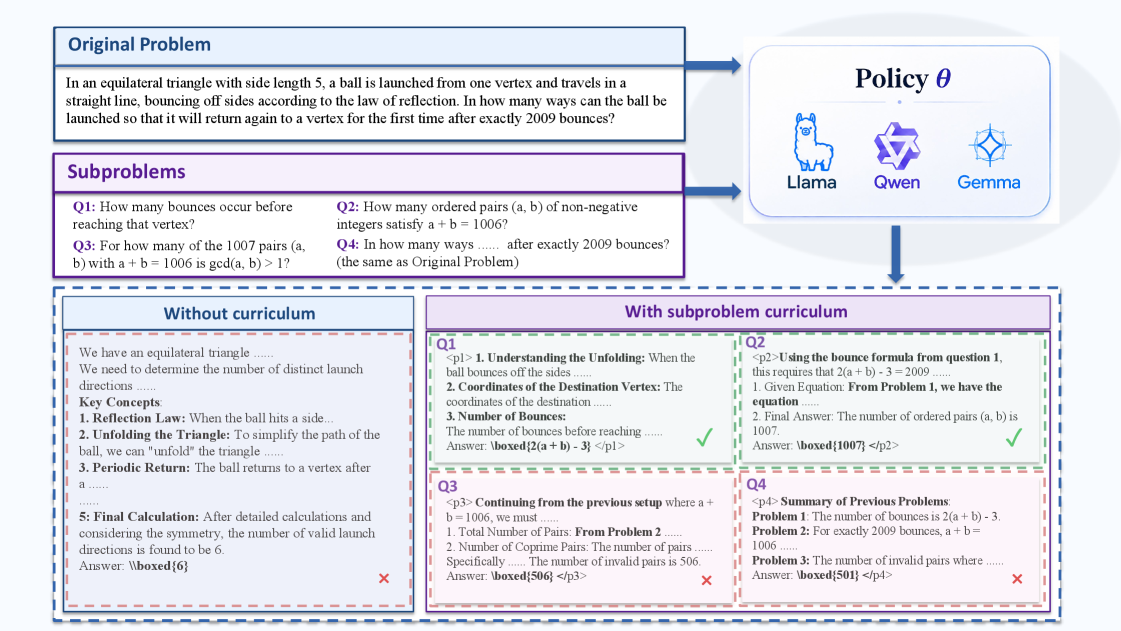
Figure 3 — 혼합 훈련 rollout 구성
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고난도 추론 문제를 검증 가능한 단위로 분해하고 이를 커리큘럼화하여 Credit Assignment 문제를 효과적으로 해결하였다. 제안된 SCRL 프레임워크는 이론적으로 고난도 문제를 gradient dead zone에서 구출함을 증명하였으며, 실증적으로도 다양한 모델 규모와 벤치마크에서 우수한 일반화 성능을 보여주었다. 이 방법론은 별도의 복잡한 외부 보상 모델이나 인간의 피드백 없이도 모델의 자체 추론 과정을 개선할 수 있다는 점에서 학계 및 산업계의 LLM 추론 능력 강화 학습에 중요한 기술적 토대를 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Beyond Entropy: Correctness-Aware Advantage Shaping via Contrastive Policy Optimization
- [논문리뷰] Transferability for General Reasoning: An Automated Curriculum for Multi-Domain RLVR
- [논문리뷰] DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
- [논문리뷰] Video Models Can Reason with Verifiable Rewards
- [논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching
- 현재글 : [논문리뷰] From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
- 다음글 [논문리뷰] Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
댓글