[논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ahmed Heakl, Abdelrahman M. Shaker, Youssef Mohamed, Rania Elbadry, Omar Fetouh, Fahad Shahbaz Khan, Salman Khan
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 모델이 생성한 추론 과정(rollout)을 결정론적 검증기(verifier)로 채점하여 보상을 부여하고 정책을 최적화하는 학습 방식입니다.
- Credit Assignment: 특정 결과(정답/오답)에 도달하기까지 생성된 전체 토큰 시퀀스 중, 최종 결과에 결정적인 기여를 한 토큰과 단순한 서술(filler) 토큰을 구분하여 학습 신호를 차등 부여하는 문제를 지칭합니다.
- Information Leakage: privileged information(예: 정답)을 분포 대상(distributional target)으로 사용할 때 발생하는 문제로, 그라디언트에 편향된 상관관계가 포함되어 모델의 일반화 성능을 저해하는 현상입니다.
- Contrastive Evidence Delta ($\Delta_{t}^{\text{CE}}$): 정답 교사 모델과 오답 교사 모델의 확률 비를 활용하여, 정답을 지지하고 오답을 반박하는 토큰에 높은 가중치를 부여하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 RLVR 환경에서 기존 정책 최적화 방식들이 겪는 불균일한 credit assignment 문제를 해결하기 위해 CEPO를 제안합니다. 기존의 GRPO와 같은 방식은 전체 시퀀스에 동일한 보상을 부여하여 결정적 추론 단계와 단순 서술 토큰을 구분하지 못하는 한계가 있습니다. 이를 해결하려는 선행 연구인 RLSD는 정보를 안전하게 전달하지만, 토큰의 의미론적 중요도가 아닌 언어 모델의 기반 유창성(fluency)에 의존하는 등의 신호 품질 저하 문제를 가집니다. 특히, OPSD나 SDPO와 같은 self-distillation 방식은 학습 과정에서 정보 유출(information leakage)을 유발하여 오히려 학습 전보다 성능이 저하되는 치명적인 결함을 보입니다 [Figure 1].
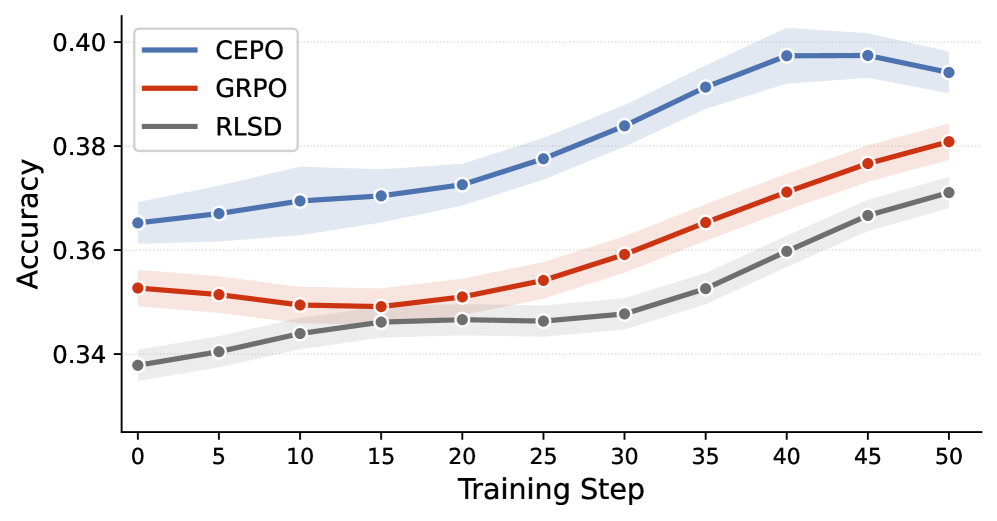
Figure 1 — 학습 초기 정확도 개선 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 정답 교사와 오답 교사를 대비시켜 학습 신호를 정교화하는 CEPO (Contrastive Evidence Policy Optimization)를 제안합니다. CEPO는 훈련 배치 내의 오답 rollout을 활용하여 오답 교사 모델 $P_{T}^{-}$를 구성하고, 정답 교사 $P_{T}^{+}$와 함께 대비 비율(contrastive ratio) $P_{T}^{+}/P_{T}^{-}$를 계산합니다 [Figure 2]. 이 방식은 베이지안 관점에서 정답에 대한 신뢰는 높이고 오답에 대한 신뢰는 낮추는 '차분 신뢰 업데이트(differential belief update)'를 수행하며, RLSD의 모든 구조적 안전성 보장(direction anchoring, leakage-free)을 유지하면서도 의사결정에 결정적인 토큰에만 신호를 집중시킵니다.
Figure 2 — CEPO 학습 파이프라인
실험 결과, CEPO는 5개의 다중 모달 수학 추론 벤치마크에서 기존 GRPO 대비 높은 성능 향상을 기록했습니다. Qwen3-VL-2B 모델에서 CEPO는 43.43%의 평균 정확도를 달성하여 GRPO(41.17%)를 상회하였으며, 4B 규모 모델에서도 60.56%의 정확도로 GRPO(57.43%) 대비 우위를 점했습니다 [Table 2]. 반면, 정보 유출이 발생하는 OPSD와 SDPO는 모든 실험에서 기준 모델보다 낮은 성능을 보여, 구조적 안전성이 단순한 최적화 문제가 아닌 필수적인 해결 과제임을 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RLVR 학습에서 정보 유출 없이 토큰 단위의 credit assignment를 최적화하는 CEPO 프레임워크를 성공적으로 구축하였습니다. 정답과 오답 교사의 대비를 통해 모델은 불필요한 filler 토큰에 대한 학습 노이즈를 제거하고 결정적인 추론 단계에 집중할 수 있게 되었습니다. 본 연구는 대규모 언어 모델의 추론 능력 향상을 위한 실질적이고 구조적으로 안전한 방법론을 제시함으로써, 향후 다양한 도메인의 강화 학습 기반 언어 모델 학습에 폭넓게 적용될 것으로 기대됩니다.
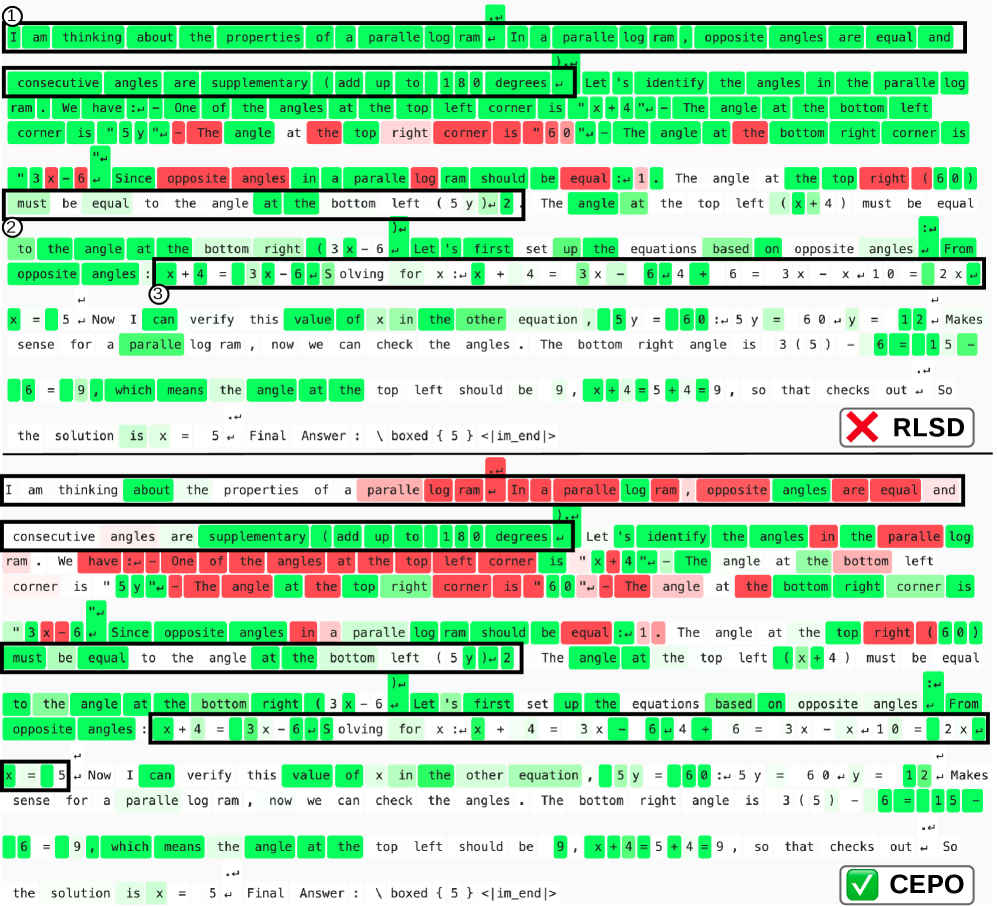
Figure 5 — 토큰 가중치 히트맵 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reinforcement Learning from Rich Feedback with Distributional DAgger
- [논문리뷰] Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing
- [논문리뷰] Self-Distilled RLVR
- [논문리뷰] Reinforcement Learning via Self-Distillation
- [논문리뷰] Denser neq Better: Limits of On-Policy Self-Distillation for Continual Post-Training
Review 의 다른글
- 이전글 [논문리뷰] AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
- 현재글 : [논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
- 다음글 [논문리뷰] Code-Guided Reasoning for Small Language Models: Evaluating Executable MCQA Scaffolds
댓글