[논문리뷰] AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jiaqi Liu, Shi Qiu, Mairui Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- AutoResearchClaw: 과학적 발견을 자동화하기 위해 5가지 핵심 메커니즘(multi-agent debate, self-healing execution, verifiable result reporting, HITL collaboration, cross-run evolution)을 통합한 다중 에이전트 연구 파이프라인입니다.
- Self-Healing Execution: 실험 실패를 단순히 종료 조건으로 처리하지 않고, 실패 원인을 진단하여 Pivot/Refine 의사결정 루프를 통해 수정하거나 방향을 전환하여 실험의 연속성을 확보하는 기법입니다.
- Verifiable Result Reporting: 실험 결과가 실제 측정값(registry)에 근거하도록 강제하고, 4단계의 자동화된 검증 파이프라인을 통해 환각(hallucination)을 방지하는 문서 작성 프로토콜입니다.
- ARC-Bench: 25개의 ML 주제와 20개의 과학 도메인(물리, 생물, 통계) 실험 과제로 구성된, 엄격한 루브릭 기반의 자동화 연구 시스템 평가 벤치마크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 자동화된 과학 연구 시스템들이 연구의 반복적이고 비선형적인 특성을 제대로 모델링하지 못하는 한계를 해결하기 위해 제안되었습니다. 현재의 시스템들은 주로 단일 에이전트의 선형 파이프라인에 의존하며, 실험 실패 시 모든 진행 상황을 포기하고, 이전 실행으로부터 학습하지 못하는 치명적인 단점이 있습니다 [Figure 1]. 이러한 문제로 인해 연구가 일회성 프로세스로 전락하며, 결과물의 신뢰성과 가설의 질이 저하되는 문제가 발생합니다. 저자들은 이러한 세 가지 과제(가설 품질, 실행 견고성, 경험 누적)가 독립적이지 않으며, 통합된 프레임워크 내에서 해결되어야 한다고 정의합니다.
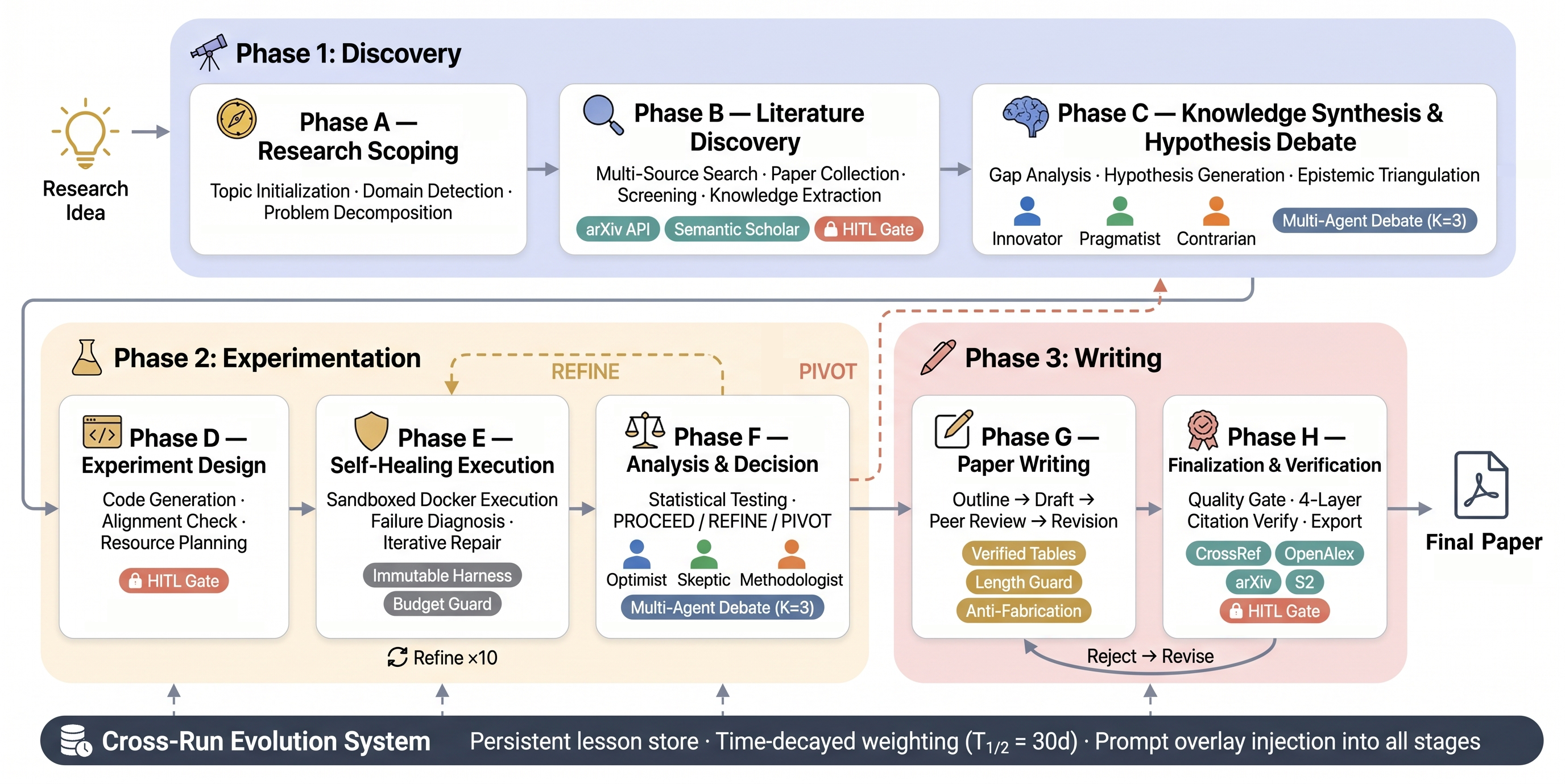
Figure 1 — AutoResearchClaw 파이프라인 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 가설 생성, 실험 실행, 결과 분석의 전 과정을 아우르는 5가지 메커니즘을 갖춘 AutoResearchClaw를 제안합니다. 이 시스템은 multi-agent debate를 통해 혁신가, 실용주의자, 회의론자 에이전트 간의 상호작용으로 가설을 검증하며, self-healing 기능으로 실험 성공률을 높입니다 [Figure 1]. ARC-Bench 실험 결과, AutoResearchClaw는 AI Scientist v2 대비 전체 성능 지표에서 54.7% 향상된 성과를 거두었습니다. 특히 결과 분석(Result Analysis) 부문에서는 100.4%의 상대적 성능 향상을 기록하며, 연구의 논리적 엄밀함을 입증했습니다. 또한, human-in-the-loop (HITL) 실험을 통해 고레버리지 결정 지점에 인간의 전문성을 결합하는 CoPilot 모드가 완전 자동화나 과도한 개입보다 우수한 논문 품질(평균 7.27점)과 승인율(87.5%)을 보임을 확인했습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 자동화된 과학 연구가 인간의 판단을 대체하는 것이 아니라, 연구자의 판단을 증폭(amplify)시키는 도구로 기능해야 한다는 새로운 패러다임을 제시합니다. AutoResearchClaw는 복잡한 실험 환경에서의 성공적인 실행과 학술적 정직성을 동시에 보장하며, 다학제적 과학 연구로의 확장 가능성을 입증했습니다. 이 연구는 향후 AI 기반 연구 시스템 설계 시, 단순히 생성 역량에 집중하는 것을 넘어 사후 검증, 경험 축적, 그리고 인간과의 지능적 협업 메커니즘을 어떻게 구축할 것인지에 대한 중요한 학술적 근거를 제공합니다.

Figure 2 — Topic T10 케이스 스터디 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams
- [논문리뷰] ScientistOne: Towards Human-Level Autonomous Research via Chain-of-Evidence
- [논문리뷰] AI for Auto-Research: Roadmap & User Guide
- [논문리뷰] FlowPIE: Test-Time Scientific Idea Evolution with Flow-Guided Literature Exploration
- [논문리뷰] RoboPocket: Improve Robot Policies Instantly with Your Phone
Review 의 다른글
- 이전글 [논문리뷰] Aurora: Unified Video Editing with a Tool-Using Agent
- 현재글 : [논문리뷰] AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
- 다음글 [논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
댓글