[논문리뷰] Aurora: Unified Video Editing with a Tool-Using Agent
링크: 논문 PDF로 바로 열기
저자: Yongsheng Yu, Ziyun Zeng, Zhiyuan Xiao, Zhenghong Zhou, Hang Hua, Wei Xiong, Jiebo Luo
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visual Underspecification: 사용자의 편집 요청이 특정 타겟이나 영역을 명시하지만, 이를 수행하기 위한 시각적 근거(이미지, 마스크 등)가 부족한 현상을 의미합니다.
- Unified Video Diffusion Transformer (DiT): 텍스트, 소스 비디오, 참조 이미지 등 다양한 입력 조건을 하나의 모델 가중치 내에서 처리하는 비디오 생성 모델입니다.
- AgentEdit-Bench: 텍스트 및 시각적 불확실성이 존재하는 150개의 테스트 케이스를 포함하여, 불완전한 사용자 요청에 대한 편집 성능을 평가하기 위해 제안된 새로운 벤치마크입니다.
- Conditioning Tuple: VLM agent가 생성한 rewritten instruction, task label, image-search query, mask phrase 등으로 구성된 구조화된 계획으로, DiT가 최종 비디오를 생성하기 위한 입력값으로 사용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 통합형 비디오 편집 모델들이 모델이 처리할 수 있는 형식의 입력(model-ready input)을 전제로 설계되어 있어, 실제 사용자의 불완전한 자연어 요청을 처리하는 데 한계가 있다는 문제에서 출발합니다. 기존 모델들은 정밀한 텍스트, 참조 이미지, 공간적 마스크를 이미 제공받아야 성공적인 편집이 가능하지만, 실제 사용자 요청에는 이러한 시각적 근거가 누락된 경우가 많습니다. 특히 Visual underspecification은 모델이 모호한 지시를 스스로 해석하게 만들어 결과물의 품질 저하와 의도하지 않은 편집을 야기합니다. 이를 해결하기 위해 저자들은 편집 전 단계에서 사용자 요청을 모델이 이해할 수 있는 완벽한 계획으로 변환해주는 에이전트 기반 프레임워크가 필요함을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VLM agent와 Unified video DiT를 결합하여 사용자 요청을 구조화된 조건으로 변환하는 Aurora 프레임워크를 제안합니다. [Figure 2]에 나타난 바와 같이, Qwen3-VL-8B-Instruct 기반의 에이전트는 사용자의 원시 요청을 받아 rewrite와 task route를 수행하며, 필요시 웹 검색(Serper API)과 세분화(Segmentation) 도구를 호출하여 누락된 참조 이미지와 마스크를 확보합니다. 이렇게 생성된 Conditioning Tuple은 고정된 Video DiT로 전달되어 최종 비디오가 생성됩니다. DiT는 Wan2.2-TI2V-5B 모델을 기반으로 하며, 에이전트로부터 전달받은 다중 모달 컨텍스트와 잠재 토큰 시퀀스를 처리하여 편집을 수행합니다. 실험 결과, Aurora는 AgentEdit-Bench에서 에이전트가 없을 때(74.7점) 대비 에이전트를 결합했을 때(87.9점) 현저한 성능 향상을 보였습니다. [Table 2]에서 볼 수 있듯이, 특히 IP 관련 작업(Replacement, Addition)에서 압도적인 개선을 달성하였으며, 기존의 UniVideo나 Kiwi-Edit 대비 우수한 일반화 성능을 입증하였습니다.
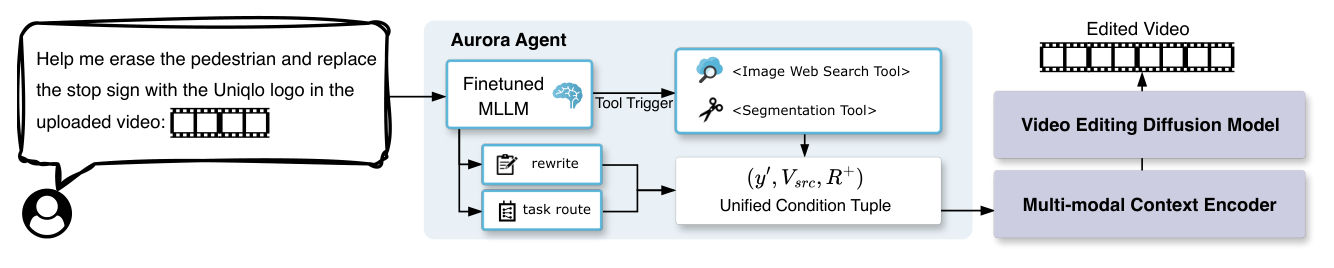
Figure 2 — Aurora 프레임워크의 전체적인 파이프라인과 VLM agent의 역할을 보여주는 핵심 구조도

Table 2 — AgentEdit-Bench에서의 정량적 성능 비교 테이블로, 에이전트 사용 유무에 따른 성능 차이를 명확히 보여줌
4. Conclusion & Impact (결론 및 시사점)
본 연구는 VLM agent를 활용하여 불완전한 사용자 요청을 모델이 처리 가능한 수준의 정밀한 조건으로 재구성함으로써 비디오 편집의 진입 장벽을 크게 낮추었습니다. Aurora는 특정 모델에 종속되지 않는 범용적인 에이전트 설계를 통해, 기존의 강력한 비디오 모델들과 결합했을 때도 성능을 보완할 수 있는 확장성을 보여주었습니다. 이번 연구가 제시한 AgentEdit-Bench는 향후 비디오 생성 AI 분야에서 사용자 의도와 실제 모델 생성물 간의 간극을 줄이는 연구의 중요한 이정표가 될 것입니다. 비디오 편집 자동화 분야는 이처럼 지능형 에이전트와 생성 모델을 결합하는 방향으로 빠르게 진화할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] VEFX-Bench: A Holistic Benchmark for Generic Video Editing and Visual Effects
- [논문리뷰] MultiRef-Compass: Towards Comprehensive Evaluation of Multi-Reference-to-Audio-Video Generation
- [논문리뷰] LooseControlVideo: Directorial Video Control using Spatial Blocking
- [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
- [논문리뷰] OmniCap-IF: Benchmarking and Improving Instruction Following Abilities for Omni-Video Captioning
Review 의 다른글
- 이전글 [논문리뷰] Artifact-Bench: Evaluating MLLMs on Detecting and Assessing the Artifacts of AI-Generated Videos
- 현재글 : [논문리뷰] Aurora: Unified Video Editing with a Tool-Using Agent
- 다음글 [논문리뷰] AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
댓글