[논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tao Chen, Gangwei Jiang, Pengyu Cheng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Skill-RM (Skill Reward Model): Reward modeling을 단일 스칼라 점수 예측이 아닌, 재사용 가능한 Reward-Evaluation Skill을 실행하는 agentic 절차로 재정의한 통합 프레임워크.
- Reward-Evaluation Skill: 평가를 위한 절차적 지침(SKILL.md)과 루브릭(rubric), 체크리스트, verifier, 레퍼런스 등 이질적인 평가 자원을 담고 있는 패키지화된 아티팩트.
- Agentic Judge: Skill-RM 내에서 정의된 프로토콜에 따라 필요한 자원을 동적으로 검색하고, 기준별 증거(evidence)를 수집하여 최종 보상을 도출하는 판단 모델.
- Structured Judgment (z): 단순한 스칼라 점수가 아닌, 각 평가 기준(criterion)에 대한 근거(evidence)와 관측치(observation)가 포함된 체계화된 평가 결과.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM post-training에서 활용되는 기존의 reward evaluation 방식이 이질적인 평가 기준을 통합하는 데 한계를 보이고 있다는 점을 지적한다. 기존의 Scalar RM은 복잡한 평가 근거를 불투명한 점수로 압축하여 해석 가능성을 저해하며, 단순한 LLM-as-a-Judge 방식은 구조화되지 않은 프롬프트를 사용하여 평가 과정에서 자원 선택과 증거 추적을 명시적으로 관리하지 못한다 [Figure 1]. 루브릭 기반의 평가 시스템들은 종종 격리된 메커니즘에 의존하여 다양한 평가 자원을 통합하는 데 어려움을 겪는다. 따라서 본 연구는 이질적인 자원을 유연하게 결합하고, 평가 근거를 명시적으로 도출할 수 있는 통합된 추상화 모델의 필요성을 제안한다.
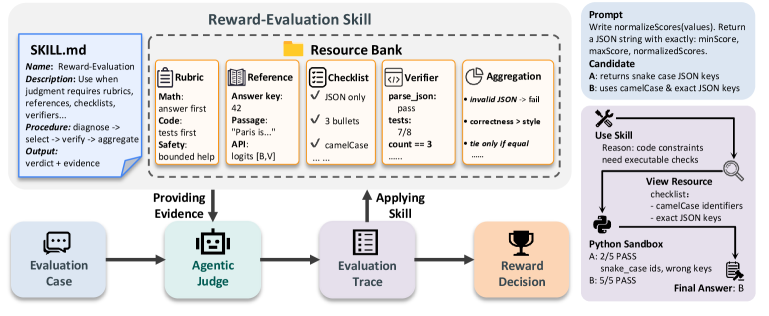
Figure 1 — Skill-RM의 전체 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구에서 제안하는 Skill-RM은 보상 평가를 재사용 가능한 Reward-Evaluation Skill의 실행으로 공식화한다. Skill-RM은 세 가지 핵심 구성 요소인 (1) 명시적인 평가 프로토콜을 담은 Reward-Evaluation Skill, (2) 자원을 동적으로 검색하고 Criterion-level 증거를 수집하는 Agentic Judge, (3) 수집된 증거를 바탕으로 최종 보상을 산출하는 결정론적 Reward Readout 함수로 이루어진다 [Figure 1]. 이 과정에서 평가 자원은 사용자가 직접 프롬프트에 나열하는 방식이 아닌, 필요에 따라 스킬을 통해 호출되는 형태로 관리되어 불필요한 문맥적 노이즈를 최소화한다. 실험 결과, Skill-RM (Qwen3.5-27B)은 매칭된 LLM-as-a-Judge Baseline 대비 평균 성능을 83.9에서 86.2로 향상시켰으며, 샘플별 자원(sample-specific resources)을 마운트할 경우 89.1까지 기록하였다 [Table 2, Table 3]. 특히, 자원 사용에 관한 Ablation 연구를 통해 성능 향상이 단순한 자원 추가가 아닌 스킬 기반의 조직화된 평가 방식에서 기인함을 확인하였다 [Table 4]. 또한, Instruction-following RL 환경에서도 Skill-RM은 최신 Baseline들을 상회하는 결과를 보이며 우수한 평가 신호를 제공함을 입증하였다 [Table 6].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 보상 평가를 구조화된 에이전트 절차로 전환함으로써 전통적인 RM 및 LLM-as-a-Judge 방식의 한계를 극복하는 Skill-RM을 성공적으로 제시하였다. 평가를 재사용 가능하고 감사 가능한(auditable) 절차로 설계함으로써, LLM 정렬(alignment) 과정에서 보다 투명하고 고품질의 피드백 신호를 확보할 수 있게 되었다. 이 연구는 보상 모델링이 단순한 수치 예측을 넘어 복잡한 에이전트적 추론 과정으로 진화하고 있음을 시사하며, 향후 LLM post-training의 신뢰성을 높이는 확장 가능한 방법론이 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation
- [논문리뷰] LSRIF: Logic-Structured Reinforcement Learning for Instruction Following
- [논문리뷰] Language Self-Play For Data-Free Training
- [논문리뷰] Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] Skill-3D: Evolving Scene-Aware Skills for Agentic 3D Spatial Reasoning
- 현재글 : [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
- 다음글 [논문리뷰] SlimSearcher: Training Efficiency-Aware Web Agents via Adaptive Reward Gating
댓글